
云原生实战笔记
涵盖中间件k8s Operator开发笔记,云资源terraform provider开发笔记,kubevela工作原理解析,kubevela插件安装原理解析,kubevela terraform插件开发笔记,运行时Serverless实现等。
涵盖中间件k8s Operator开发笔记,云资源terraform provider开发笔记,kubevela工作原理解析,kubevela插件安装原理解析,kubevela terraform插件开发笔记,运行时Serverless实现等。
在实战的过程中,我自己做了很多笔记,从模糊到清晰,逐渐了解云原生架构,不仅参与了中间件容器化架构改造与自动化部署Operator开发,还参与了IaC基础设施即代码的开发,kubevela terraform Addon插件开发,从应用层到中间件到基础设施都有参与,整条链路的一些核心原理都非常清晰。
Serverless、ServiceMesh是2023年全球架构师峰会(北京站)出现频率最高的词,本篇将从这两个方面分享笔者参会了解到的一些信息。
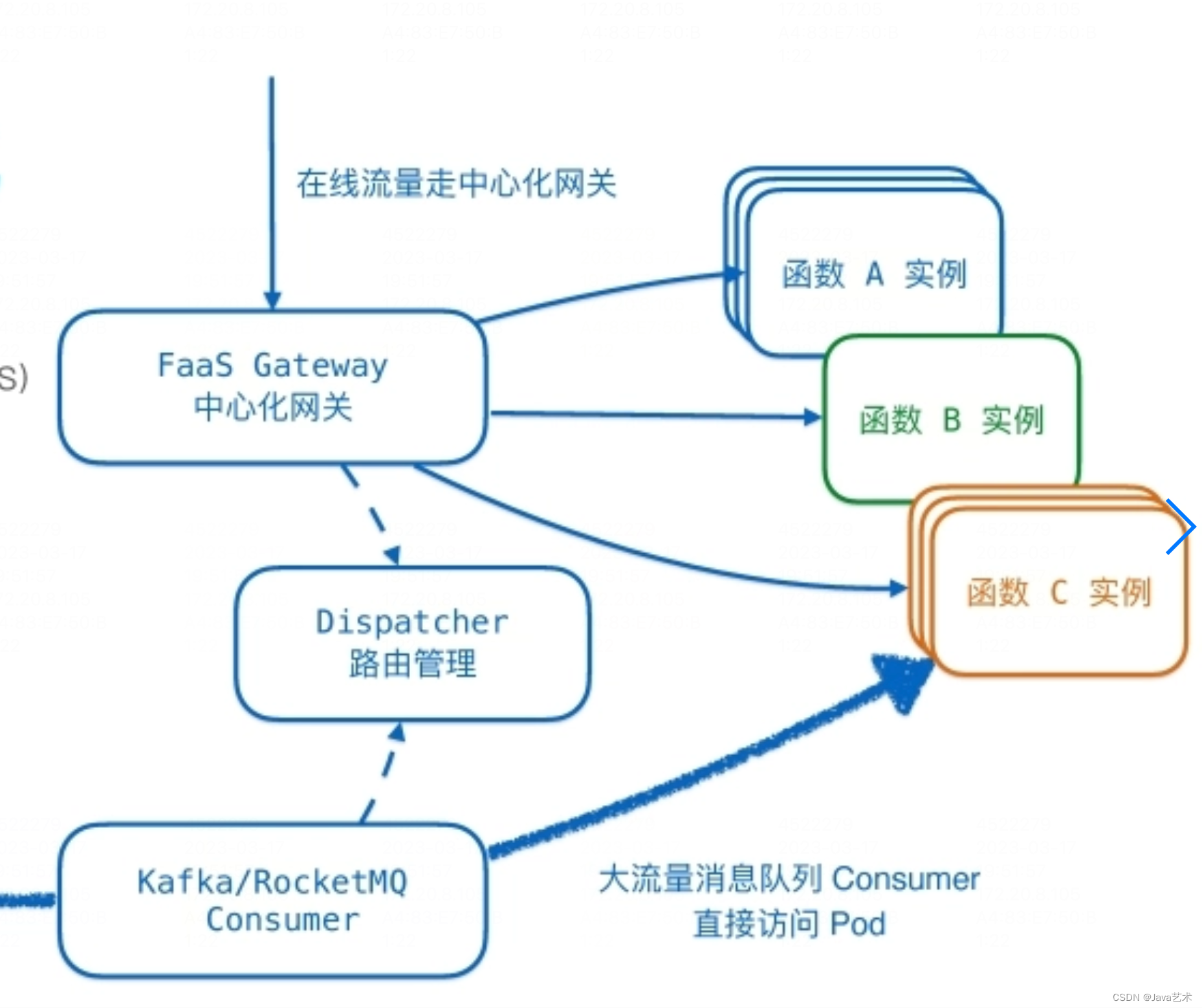
中间件容器化部署是为了实现GitOps模式的持续交付,实现部署即代码。痛点在于大多数中间件都是有状态的,本篇介绍如何实现有状态中间件的容器化部署。
新的云原生中间件很难短时间内覆盖到企业项目中,企业走云原生这条道路,还需要考虑传统中间件如何上云的问题。最需要解决的是如何容器化部署,以及自动化运维。这就不得不借助Operator了。
举一个非常简单的需求场景,仅用于介绍如何使用kubebuilder开发一个Operator,非真实需求场景。
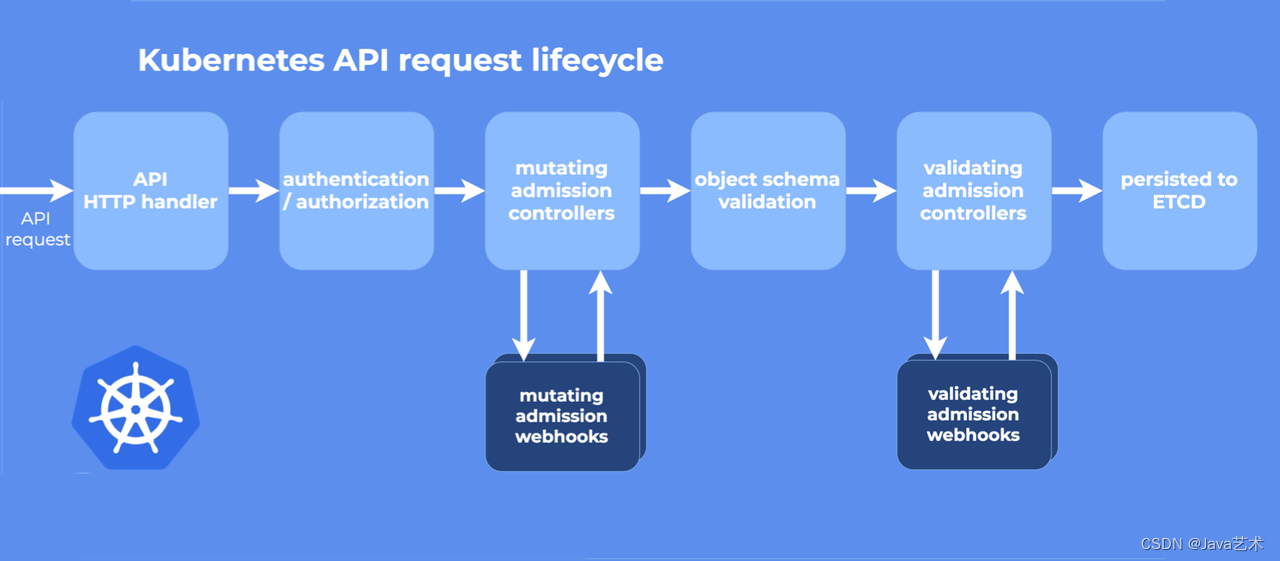
terraform-controller默认Job会一直重试,导致重复申请资源。
kubebuilder使用helm代替kustomize;代码改了但似乎没生效-镜像拉取问题; 使用ConfigMap替代Apollo配置中心的最少改动方案;环境变量的注入以及传递;Kubebuilder单测跑不起来;Helm chart和finalizer特性冲突问题。
在Job场景,如果Job达到backoffLimit还是失败,而且backoffLimit值很小,很快就重试完,没能及时的获取到容器的日记。而达到backoffLimit后,job的controller会把pod删掉,这种情况就没办法获取pod的日记了,导致无法得知job执行失败的真正原因,只能看到job给的错误:"Job has reached the specified backoff limit"。
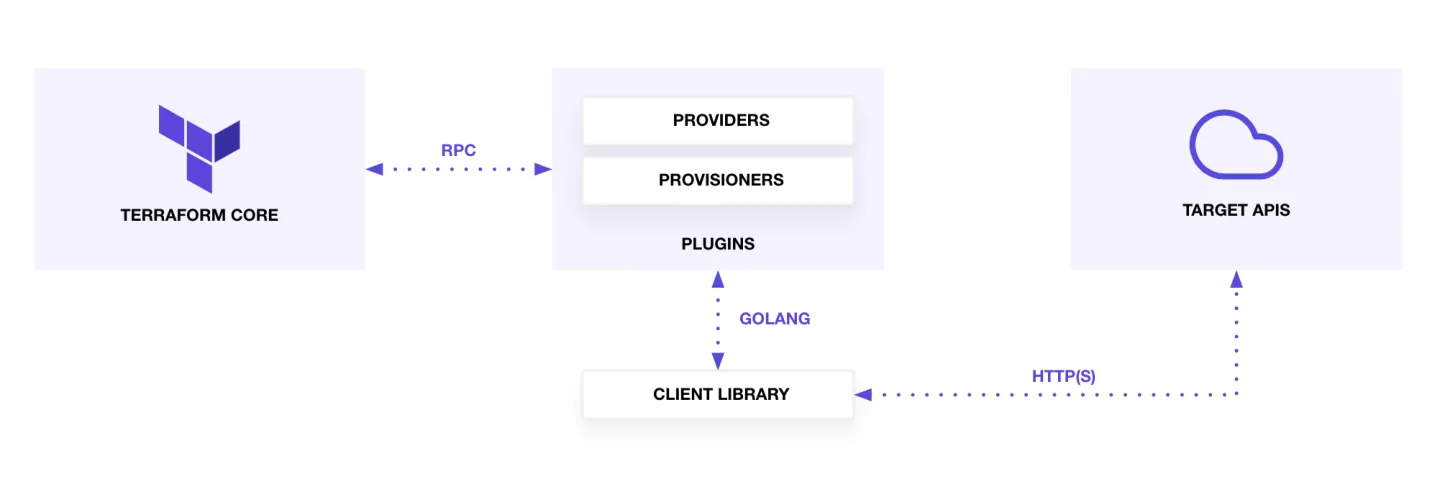
通常申请基础设施,我们需要向运维描述我们需要什么基础设施、什么规格,运维根据我们的描述去检查是否已经申请过这样的资源,有就会直接给我们使用基础设施的信息,没有再帮我们申请,然后告诉我们使用基础设施的信息,例如mysql的jdbc和用户名、密码。如果将描述代码化,基础设施的申请自动化,就能实现“基础设施即代码”。而terraform就是实现“将描述代码化”的工具软件。
很多企业内部为了不与云厂商绑定,避免上云容易下云难的尴尬,以及企业内部可能也会做私有云,或者封装一个混合云平台,因此不能直接用云厂商提供的provider。
Go sdk本地开发调试sdk依赖问题;关于复杂嵌套结构体的schema声明;状态死循环监听,以及terraform命令终止时如何终止死循环;资源创建接口的默认可选字段不填遇到的坑;HCL代码输入变量的复杂校验。
“部署即代码”即用代码描述一个应用的部署计划。KubeVela就是实现这一目标的平台,让我们可以编写一个符合OAM模型的yaml来描述应用的部署。
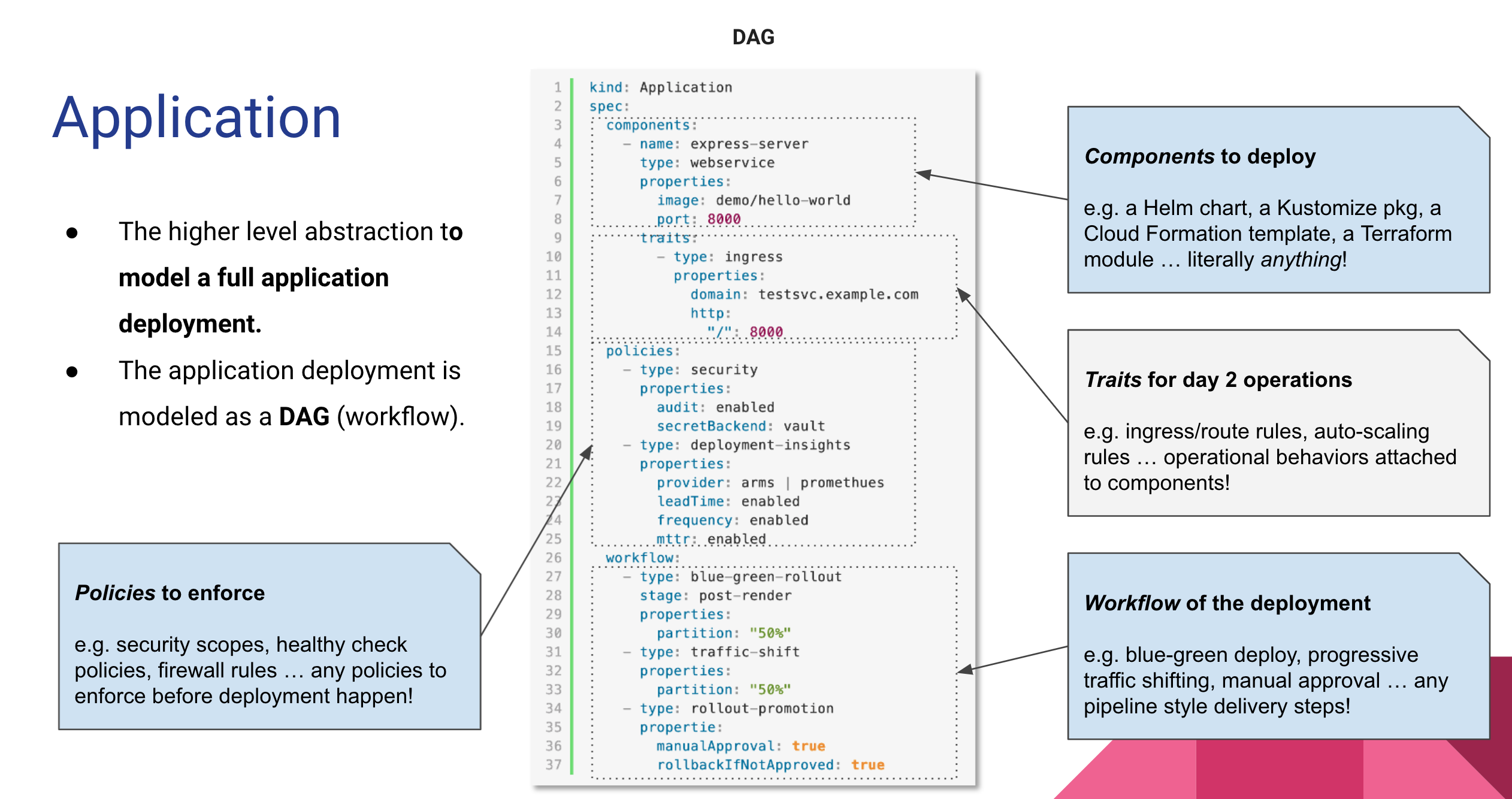
KubeVela是面向混合云环境的应用交付控制面,不与任何云产商绑定。KubeVela通过提供插件扩展机制,打通了应用交付涉及的基础设施即代码-terraform等能力。编写一个符合OAM模型的application.yaml就能实现将应用部署起来,包括申请基础设施。实现了声明式部署,且一次编写,到处部署。
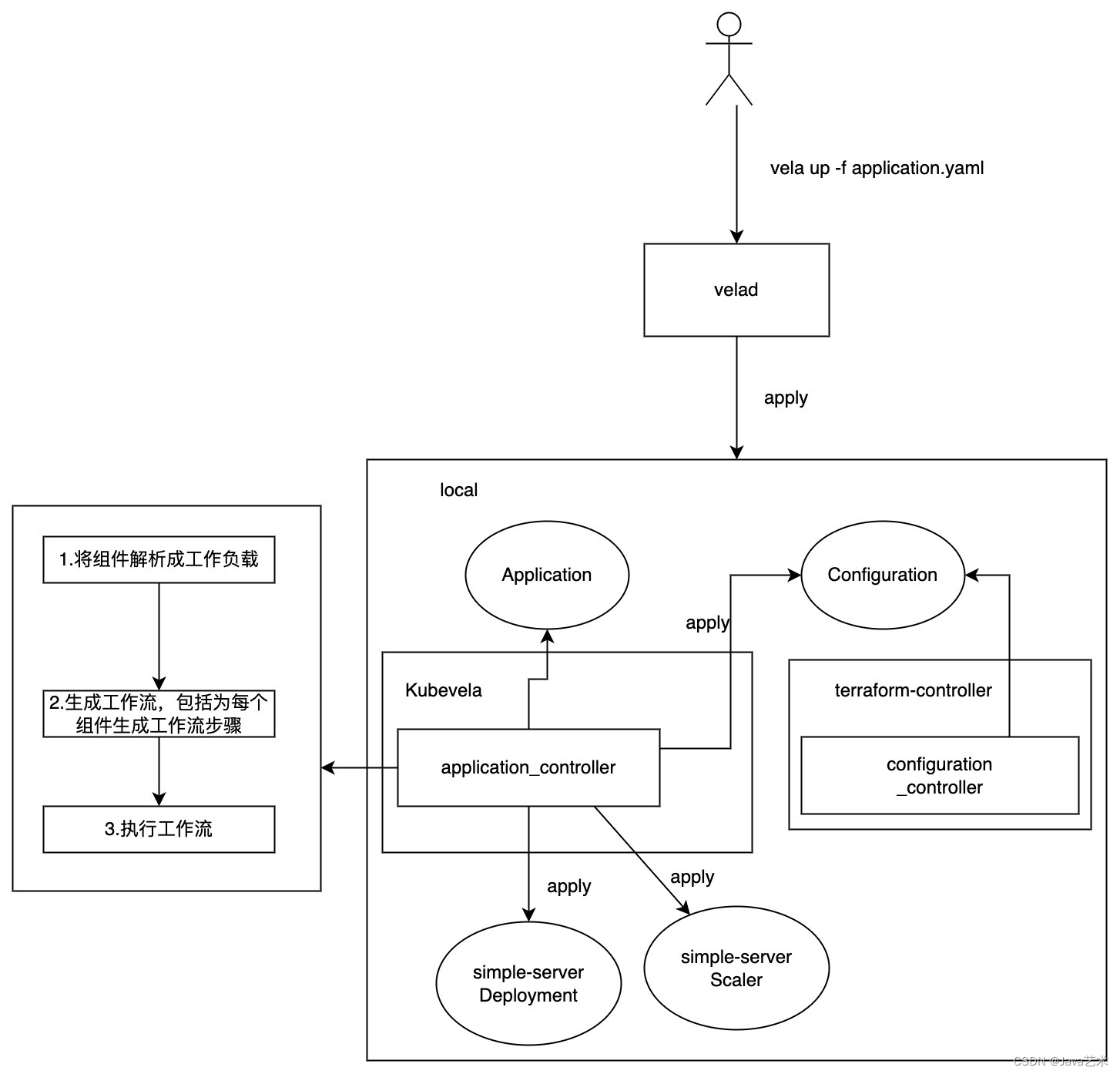
以一个简单的first-vela-app应用在kubevela上部署为例,介绍应用安装流程。
以使用阿里云的基础设施为例,理解KubeVela打通Terraform申请云资源。
通过前面的章节,我们已经学习了解terraform,并通过vpc资源例子,为私有云/混合云开发了terraform provider,这一节介绍如何将我们开发的mycloud terraform provider整合到kubevela控制平台上,以通过在application中声明一个kubevela组件的方式去申请基础设施资源。
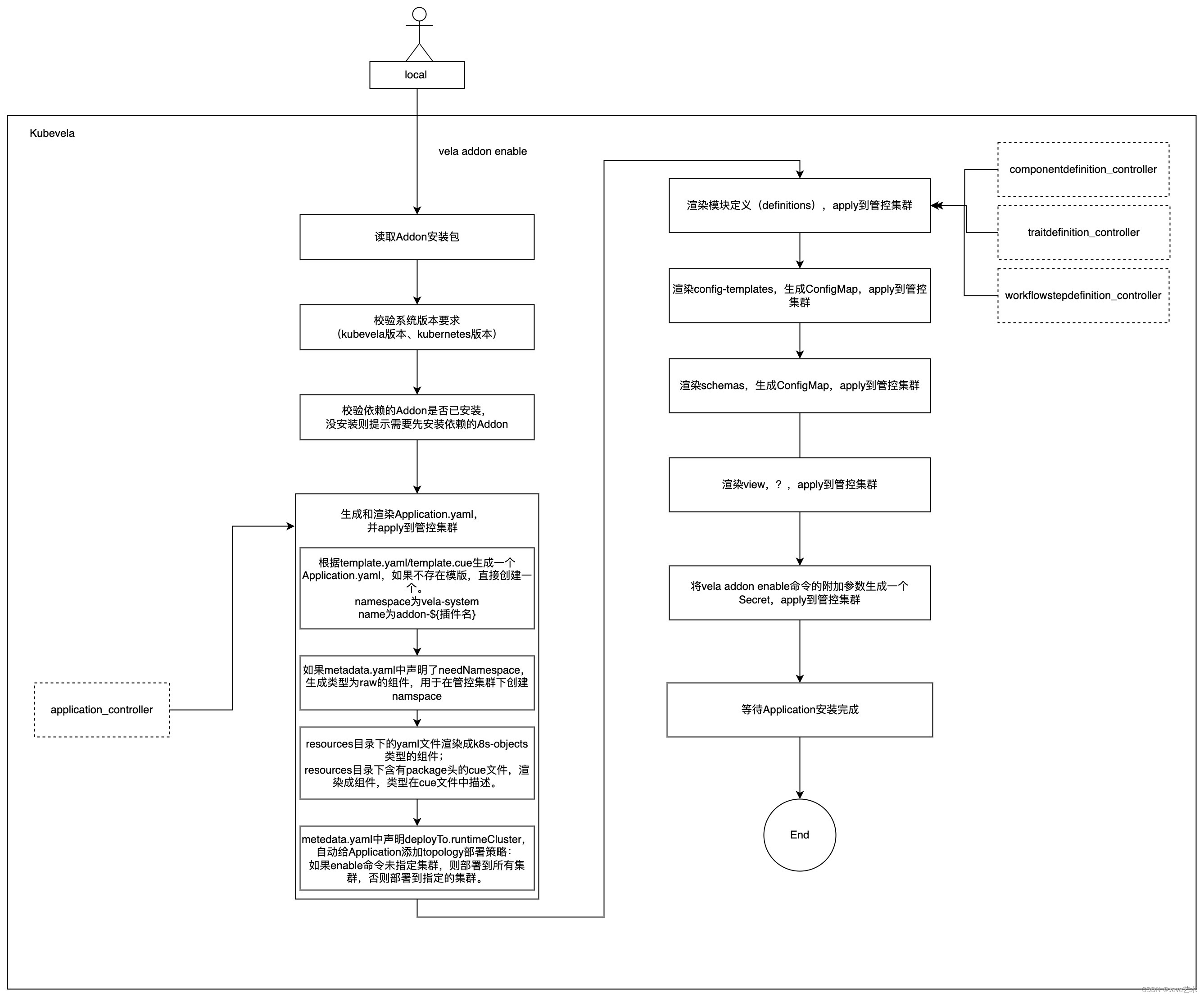
terraform插件的安装过程;terraform provider插件的安装过程。
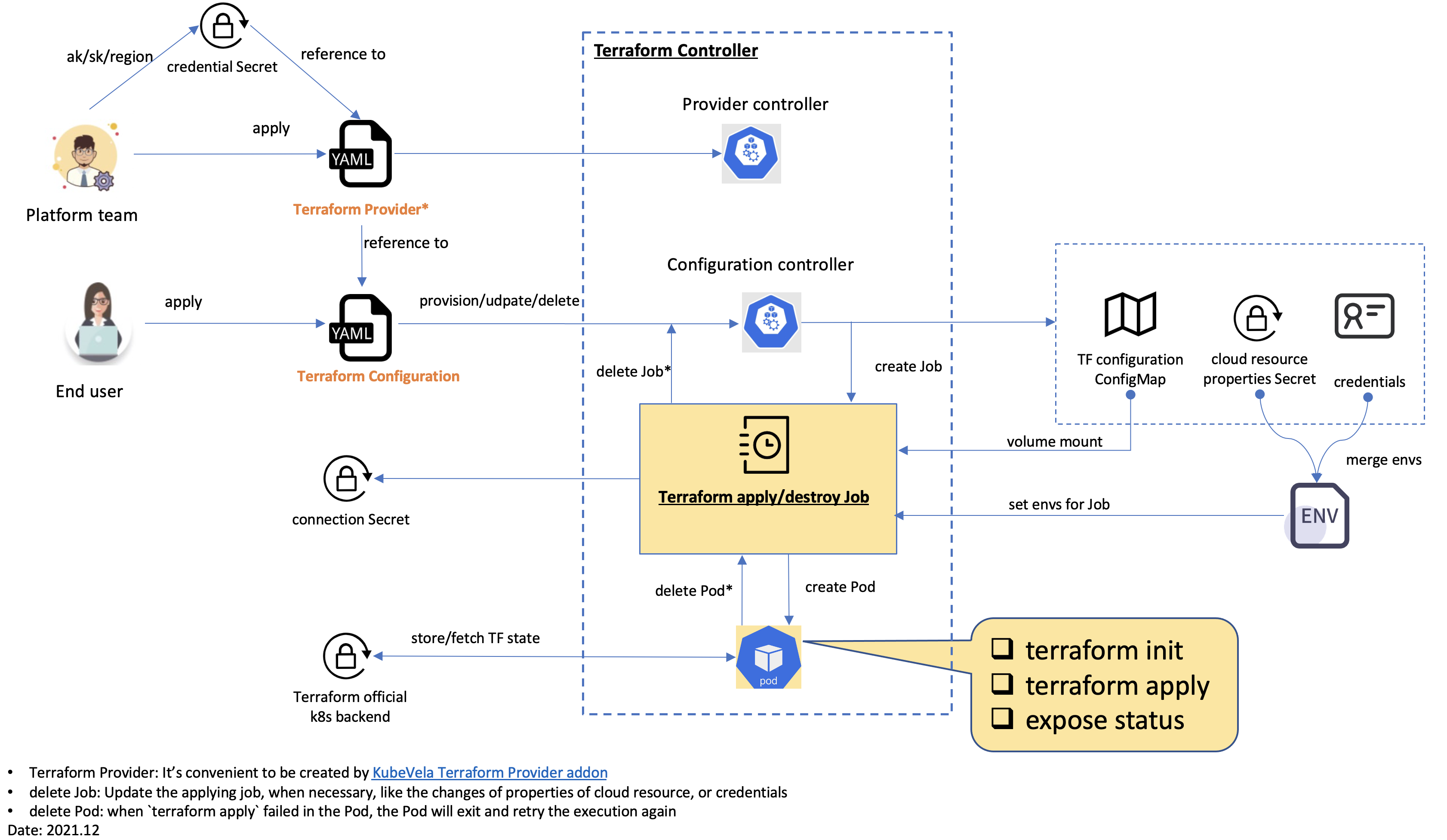
erraform-controller是一个专门负责terraform一类的组件"安装"的Operator,通过打包成helm,再封装成kubevela的Addon,由kubevela安装到管控集群,为其它terraform provider插件提供模块定义支持。
kubevela安装一个Application的过程,就是执行工作流上的每个步骤的过程,并且当我们未配置工作流,kubevela会自动为组件的部署生成一个工作流步骤。
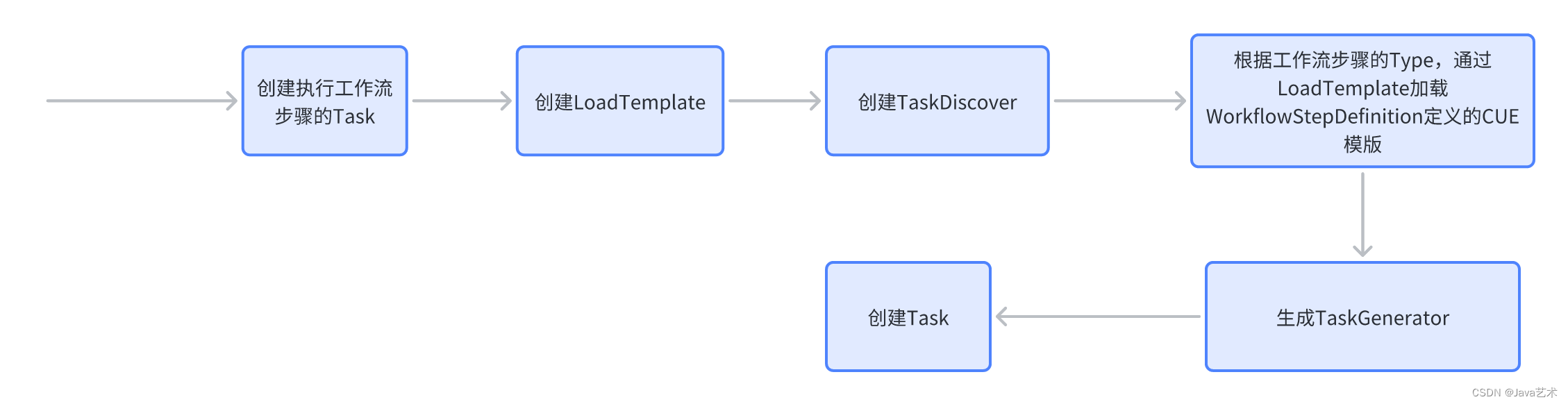
terraformProvider、multiclusterProvider、oamProvider、configprovider、kube这些provider的Install方法注册了很多操作处理方法。这些方法就是提供给CUE中调用的方法。

如何Debug Terraform Controller;如何让Configuration可以指向私有仓库;为云资源编写ComponentDefinition;验证流程是否跑通。
我们基于KubeVela开发的云原生应用交付平台,提供如初始化基础设施导入、中间件部署共用基础设施等相关能力的测试,需要依赖基础设施。虽然terraform是面向公司内部的混合云平台,但是测试都要跨部门配置效率太低了,而且这种模式无法支持持续测试。
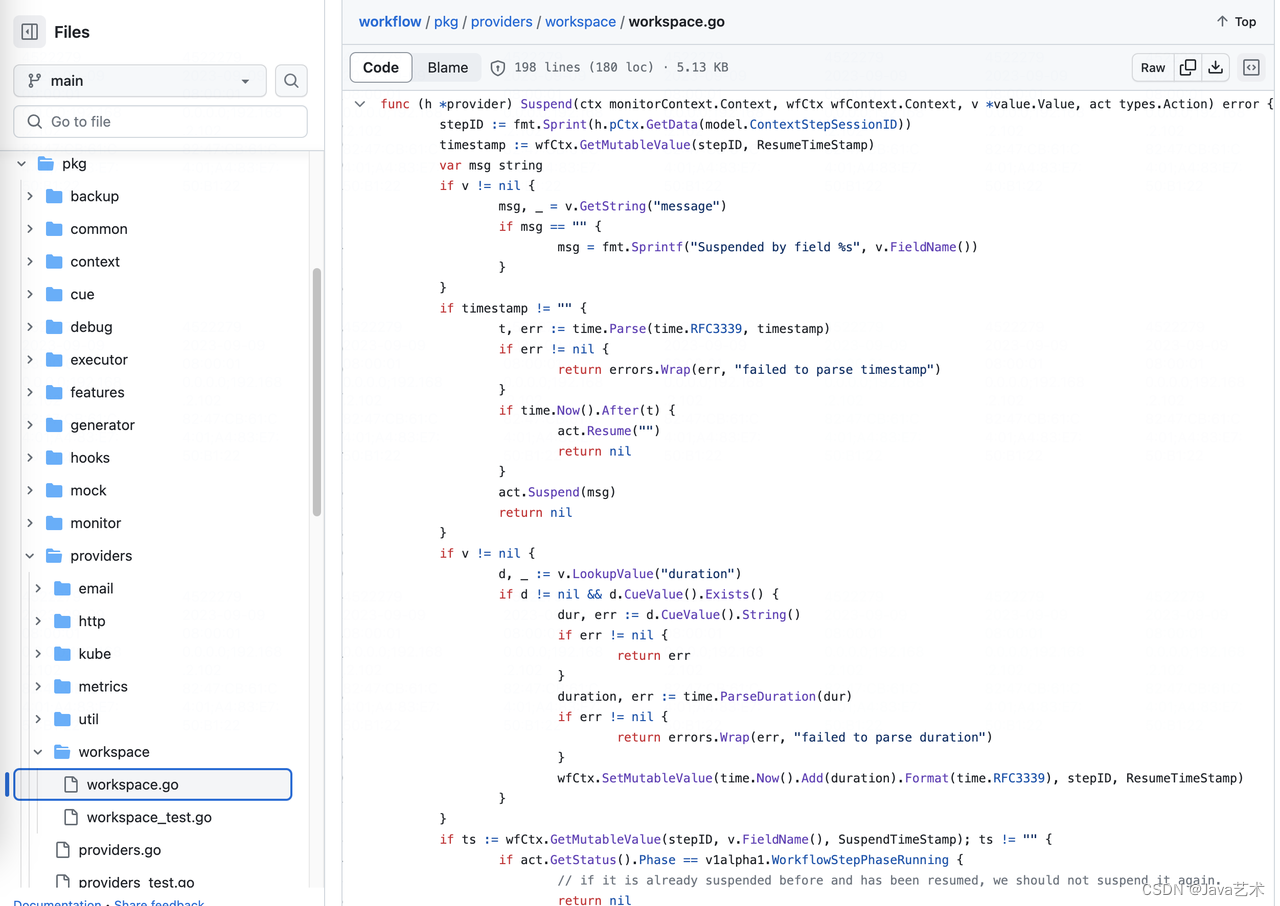
官方提供的工作流步骤有限,另外,对于自研的PaaS平台,我们需要借助工作流步骤实现一些例如存量项目基础设施导入、项目环境初始化、平台组件共享基础设施需要解决的差异对比审核、基础设施漂移等。
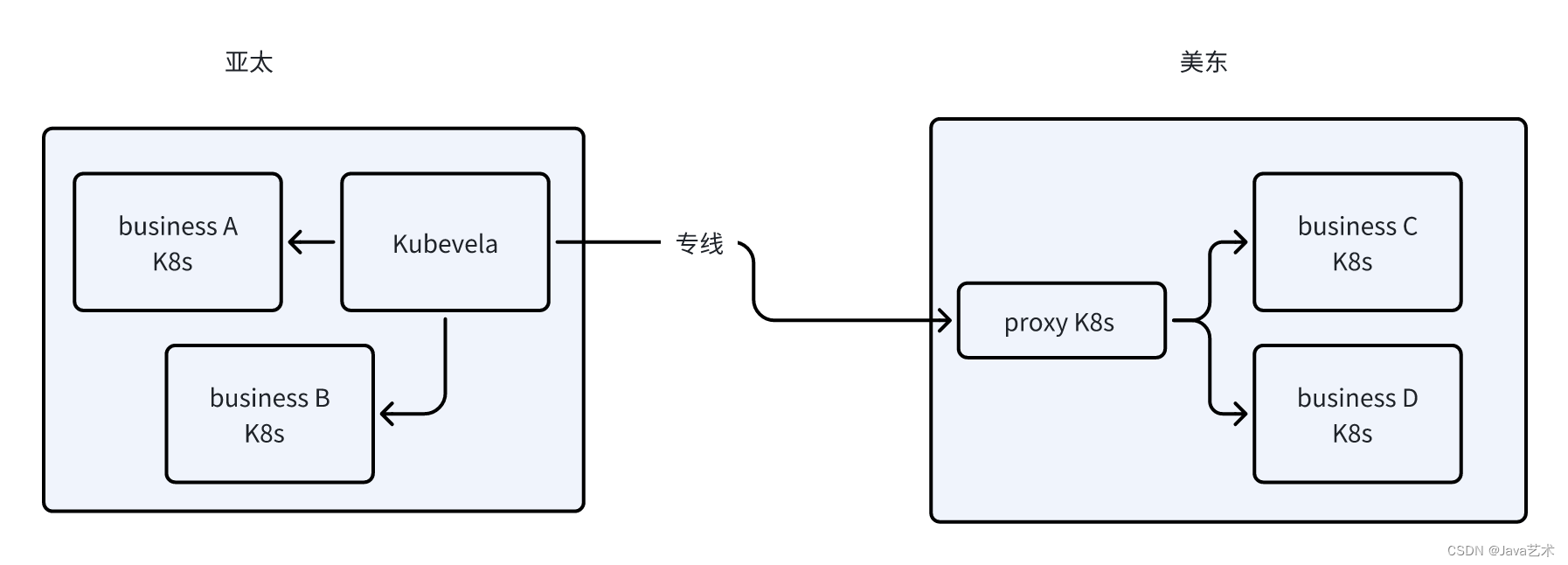
随着公司全球化战略的布局,业务呈点状分布在亚太、美东、欧洲等多个地域,云原生kubevela在跨地域多集群管控方面也遇到网络上的互通问题。
由于我们的使用场景是将基础设施资源定义成KubeVela的组件,一个terraform “module”对应的就是一个kubevela的组件,对应terraform-controller的一个Configuration资源。因此导入的最小粒度是组件,即一个terraform “module”。
KubeVela于2020年年底开源,距离现在还未满三年时间,是一个非常年轻的产物。KubeVela是非常创新的产物,如OAM模型的抽象设计。所以也并未成熟,除了官方文档,找不到更多资料,在使用过程中,我们也遇到各种大大小小的问题。
由于方向的错误,我们第一阶段开发的云原生PaaS平台这个项目也迎来了终结。但我们换了个方向继续做云原生PaaS平台。
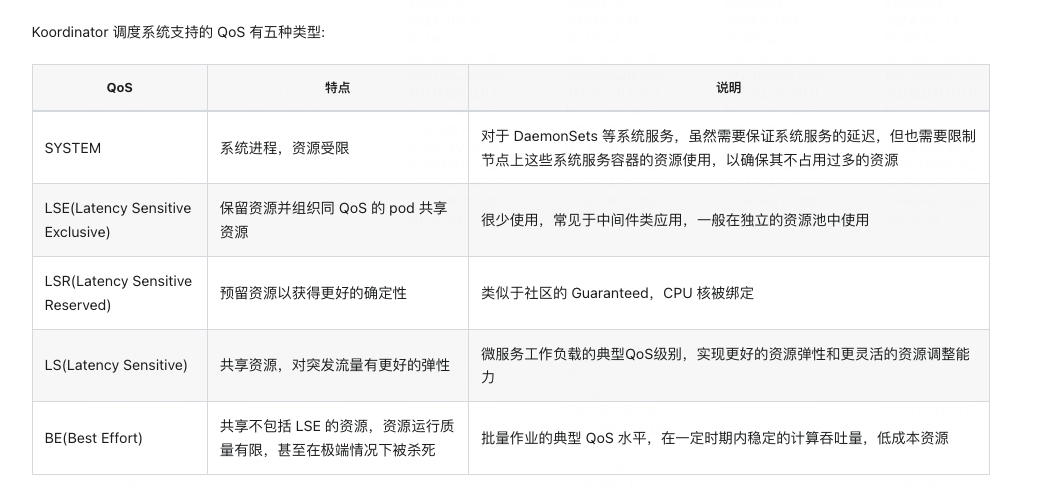
在降低增笑的大背景下,如何在保证稳定性的前提下,做到极致压缩k8s资源的使用,实现基础设施真正的按需付费,是我们云原生项目的目标之一。要实现如Railway这种产品的基础设施按实际使用付费,不能简单的使用云Serverless产品,因为这些产品都有最低限额的要求,例如阿里云最低限制要求Pod至少0.25cpu+0.5g内存,但其实大多数应用这个配额都用不到,大量的时间cpu负载几乎为0,内存消耗可能也就几十M(Java应用除外),大量的低使用率的Pod会造成资源的浪费。
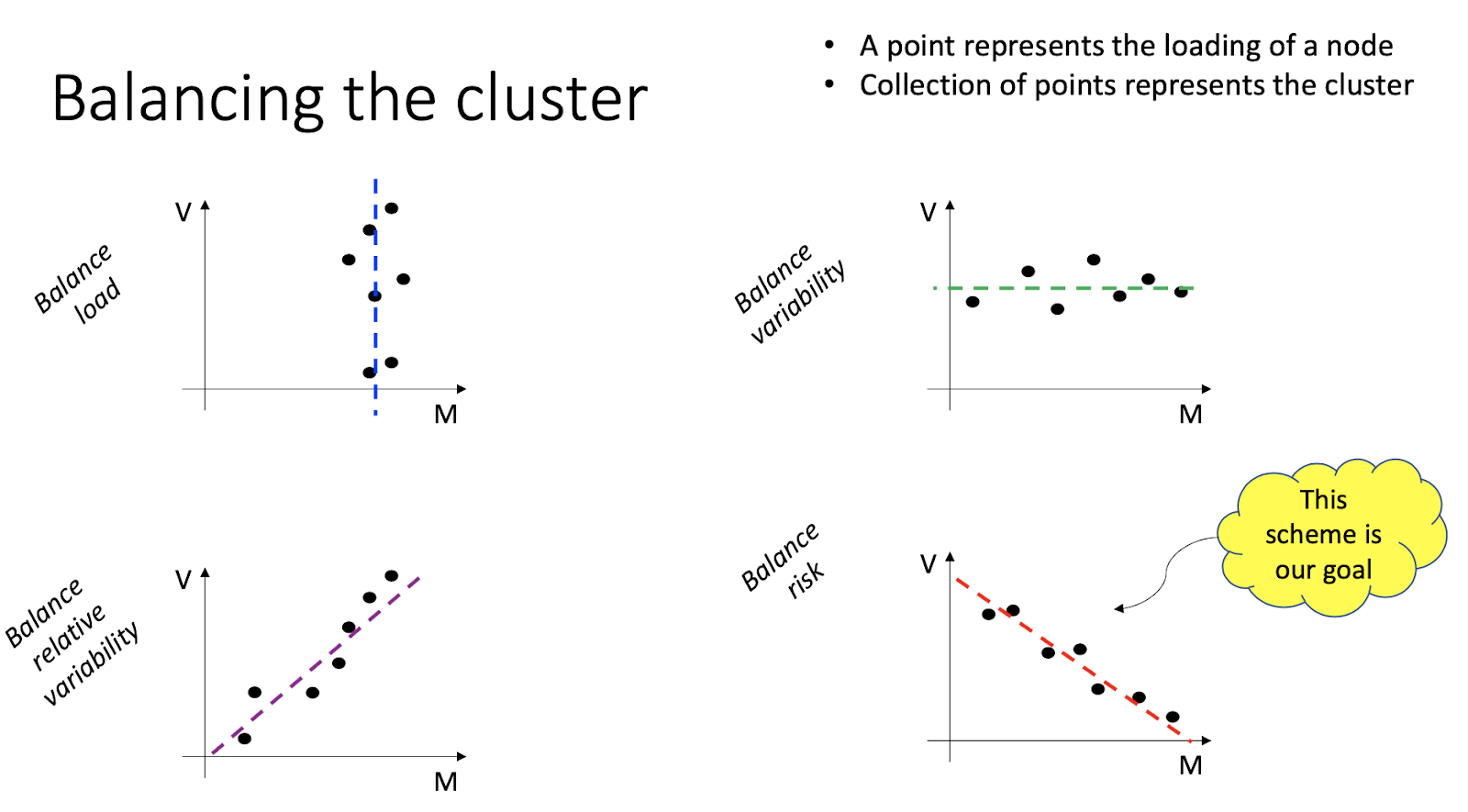
本篇介绍的内容是scheduler-plugins框架的LoadVariationRiskBalancing插件,这是一个k8s调度框架的评分插件,基于request、均值和标准差的K8s负载感知调度器。 我们通过实验去理解和验证该插件实现的负载感知均衡调度算法。
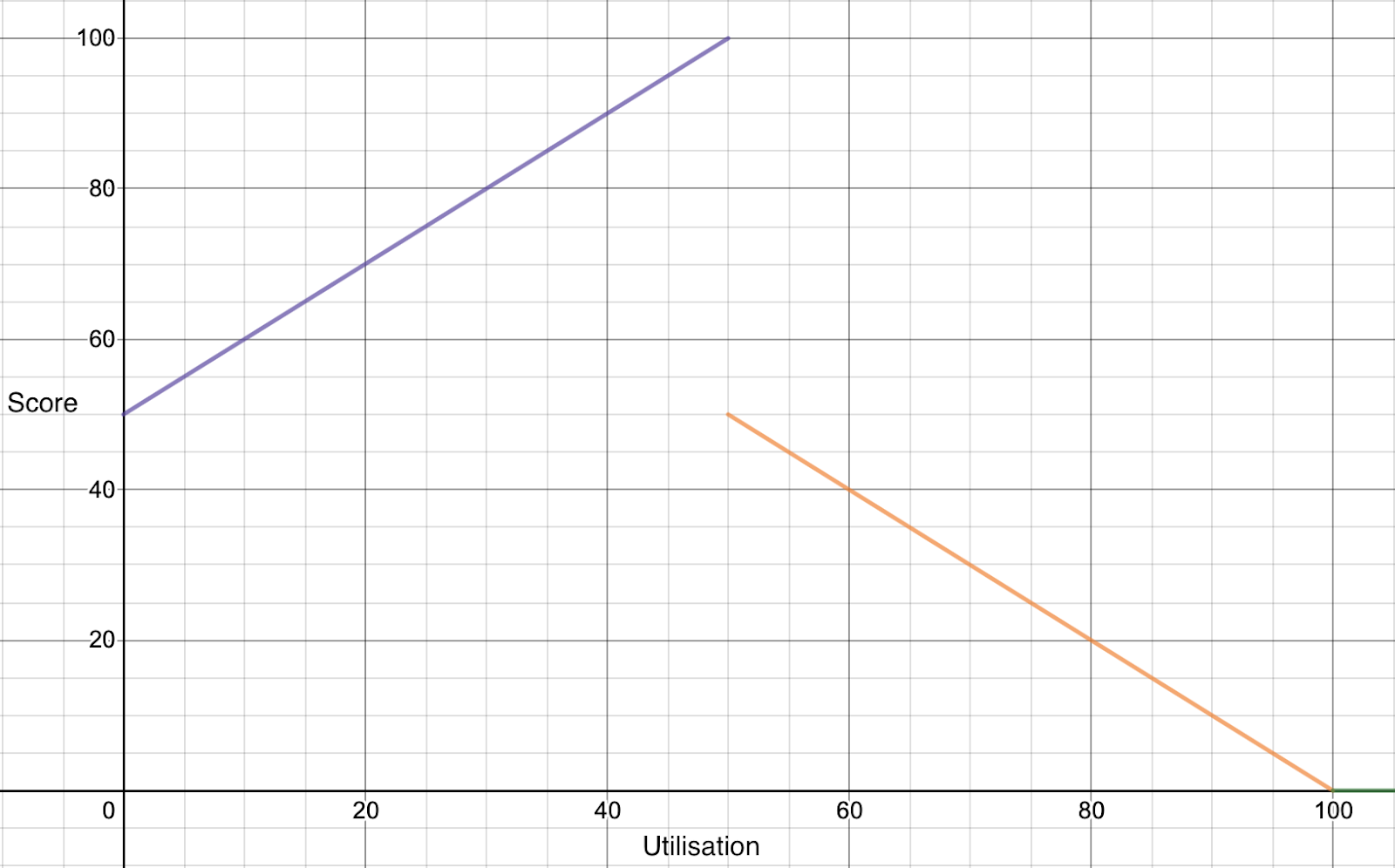
本篇介绍的内容是scheduler-plugins框架的TargetLoadPacking插件,这是一个k8s调度框架的评分插件。TargetLoadPacking即目标负载调度器,用于控制节点的CPU利用率不超过目标值x%(例如65%),通过打分让所有cpu利用率超过x%的都不被选中。目标负载调度器只支持CPU。

验证gce的自动缩容时机以及扩容需要的时长:扩容一个节点需要等待多长时间,一个节点在没有Pod的情况下多久后会回收。结合scheduler-plugins框架验证。由于scheduler-plugins只是在Score阶段对节点打分,并未在其它阶段阻止Pod调度到分数为0的Node上,例如基于目标负载感知调度,当所有Node的负载都达到目标负载后,即便节点的requests满足Pod所需,是否能走扩容节点,而不是硬塞到现有节点上。
不会影响到默认调度器,只会影响到scheduler-plugins调度器本身。默认调度器不会因为自定义调度器的配置而改变。
超卖其实就是赌徒思想,堵的就是概率。一个节点上的个别Pod异常突增的概率都很小,同时很多Pod一起异常突增的概率更小。
不禁感叹,k8s这个底座设计的太牛了,我们不仅可以通过CRD + 控制器做扩展,还可以自定义APIService去做扩展。k8s,牛啊!
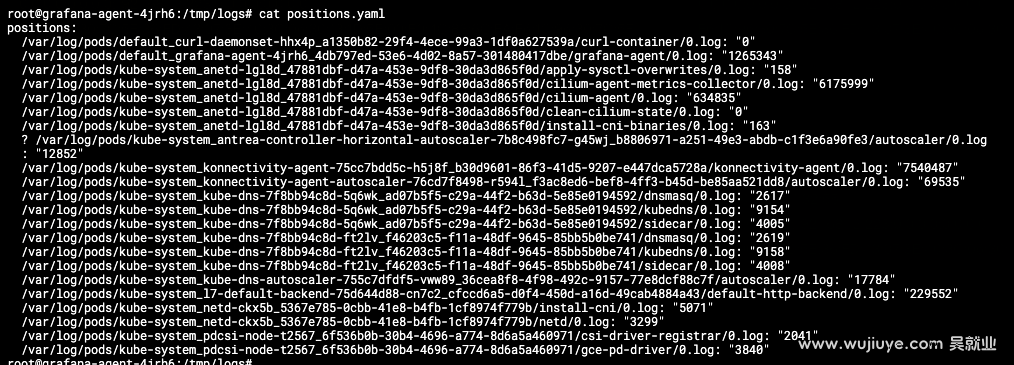
本篇是作者在云原生PaaS平台项目中实战可观测能力做的技术调研,将关键技术知识点讲透,涉及:如何获取Pod的标准输出(stdout)日志、如何使用Grafana Agent收集日志(附配置案例讲解)、如何将日志上传Grafana Loki。
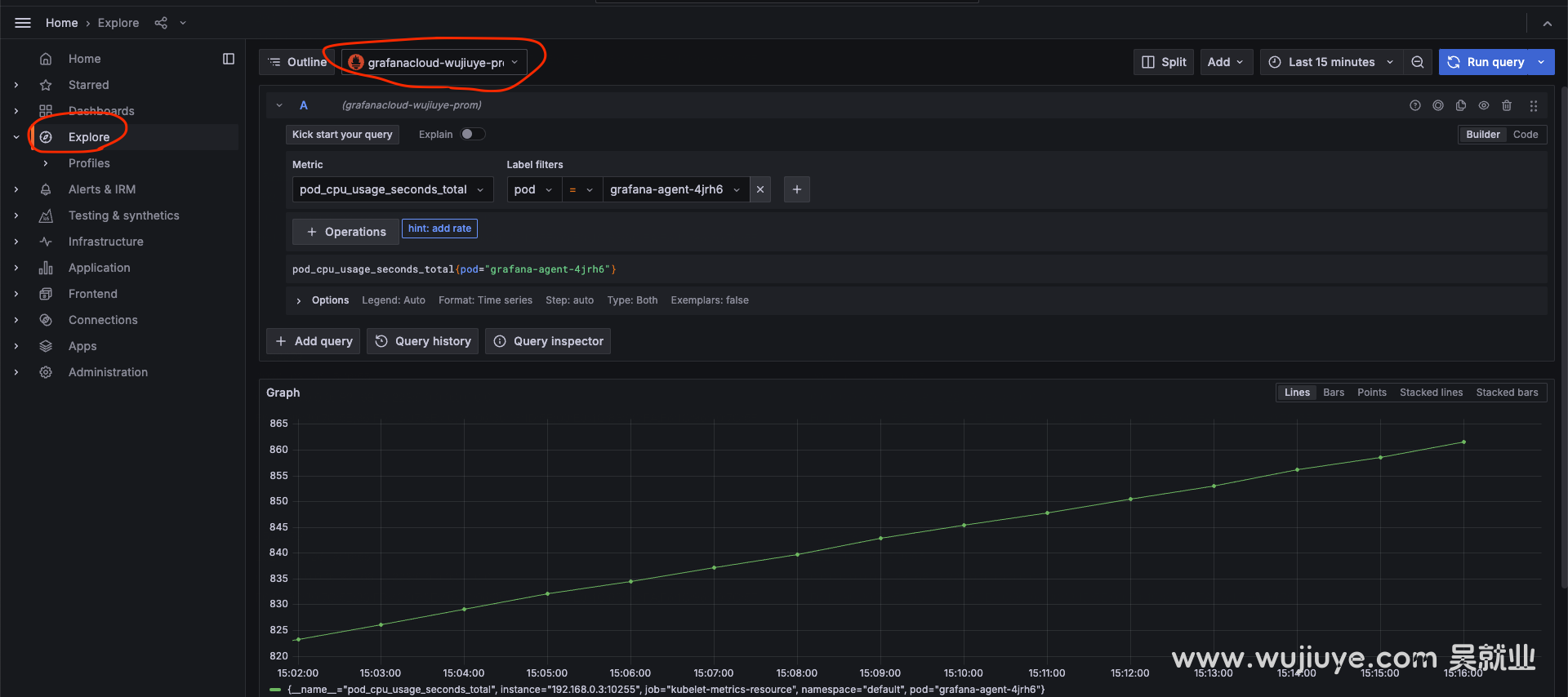
本篇是作者在云原生PaaS平台项目中实战可观测能力做的技术调研,将关键技术知识点讲透,涉及:如何获取Pod的cpu和内存指标、使用Grafana Agent收集指标、上传到Prometheus。
通常指标和日志收集这两者是一起的,可观测即离不开指标,也离不开日记。当两者都需要的时候,就没必要部署两个DaemonSet了。本篇将两者结合成一个完整的案例,大家可以直接拿去部署使用。
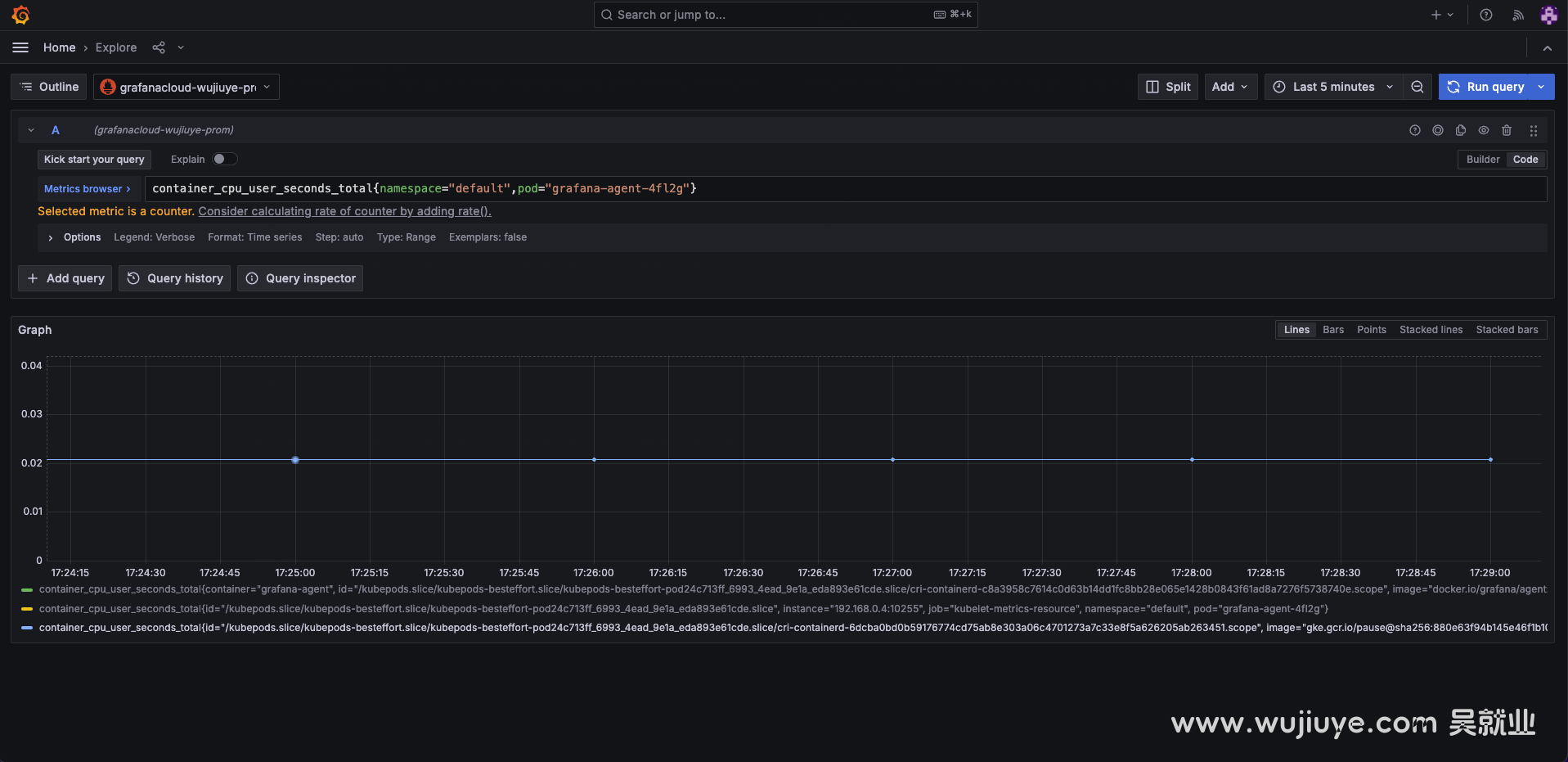
前面《如何获取Pod的CPU和内存指标,使用Grafana Agent收集指标,上传到Prometheus》这篇介绍的指标获取只拿到了cpu使用率,怎么转成cpu使用量呢?
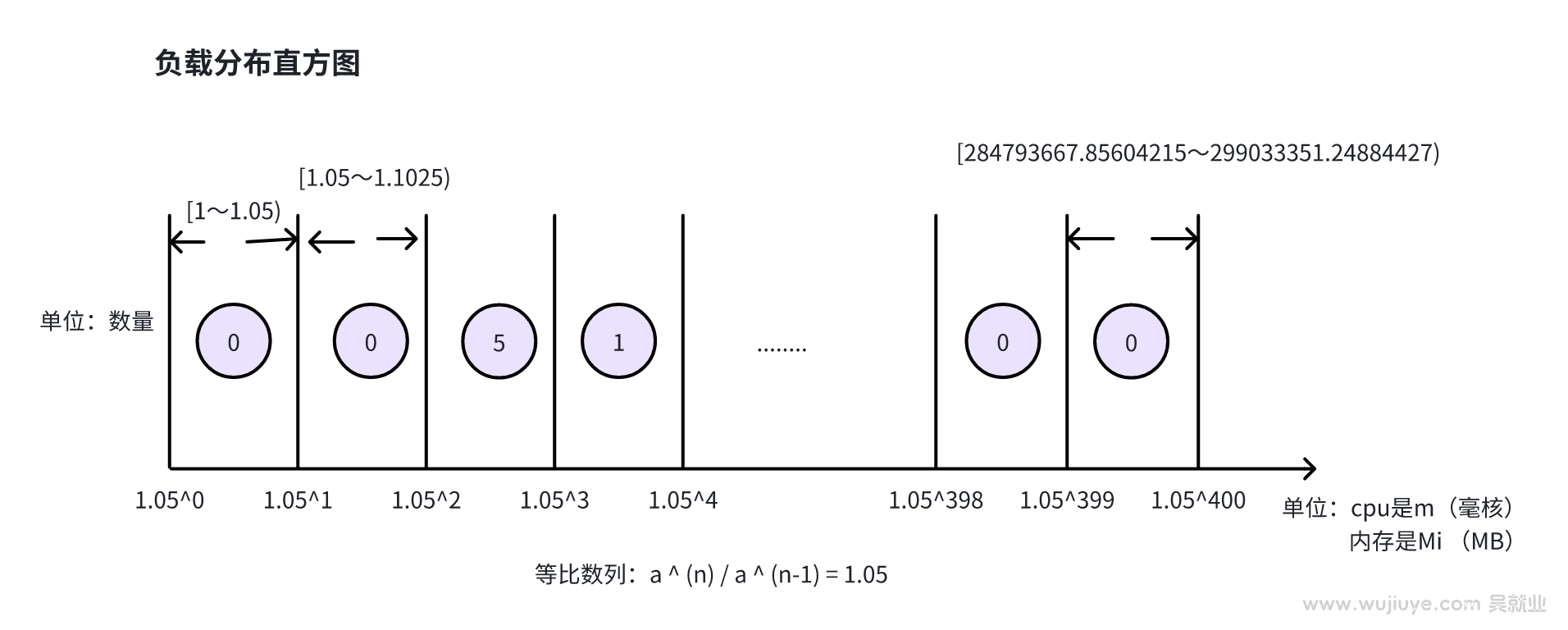
本篇简单描述(Autopilot: workload autoscaling at Google)论文中描述的资源request预测算法,不需要理解论文中那复杂的数学公式。
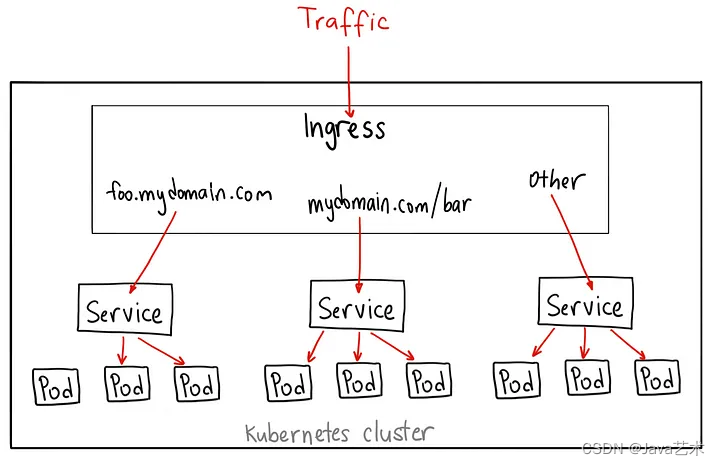
apiserver是k8s的另一种扩展机制,相比CRD,它更为灵活。本篇以实战为主,介绍如何实现一个简单的apiserver。
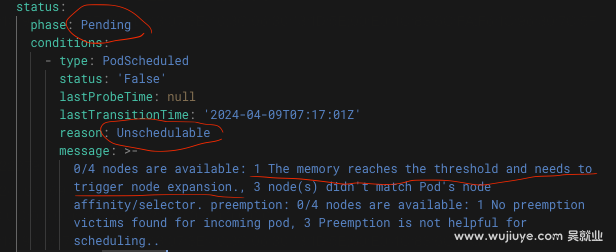
我们使用自定义的调度器来调度pod,有自定义的Filter插件。Autoscaler在执行扩容之前,会调用Filter插件,尝试是不是真的没有node满足调度这个pod再去扩容。而默认情况下,Autoscaler拿的是默认的Filter插件,拿不到我们自定义的Filter插件,所以没有走我们的Filter逻辑,所以不会扩容。

在google cloud上使用gke集群,gke已经集成autoscaler,通过在控制台创建节点池点击开启自动扩缩容就可以,那么为什么还要自己部署呢?怎么本地让autoscaler成功跑起来呢?
想要让autoscaler支持自定义调度器触发节点扩展,有两种方案。一是autoscaler支持自定义调度器的过滤器插件,二是autoscaler取消check逻辑。
autoscaler,想要缩短空闲节点被回收的时间,需要同时考虑三个启动参数的配置:scale-down-unneeded-time、unremovable-node-recheck-timeout、scale-down-delay-after-add。
低负载自动缩容节点的这个特性还是非常有必要的,能够避免资源的过渡浪费。因为随着时间的推移,集群中势必会出现非常多的弹性节点利用率很低的情况。

但其实我们忽略了一点,autoscaler是根据部署在节点上的所有Pod声明的requests来计算资源使用率的,这个并不能反应真实情况。
基于开源的autoscaler二次开发,通过自部署autoscaler来替代GKE提供的节点自动扩缩容能力,获取更好的扩展性和更灵活的配置。主要增强以下特性:支持目标负载扩容、更快的缩容速度、支持低负载自动缩容-重调度。
持久卷是什么时候创建的,是什么时候挂载的,是怎么创建怎么挂载的?
CSI驱动必不可少的几个组件:csi-provisioner、controller组件、csi-node-driver-registrar、node组件,controller组件和node组件就是需要我们开发的,其实就是实现几个gRPC接口。
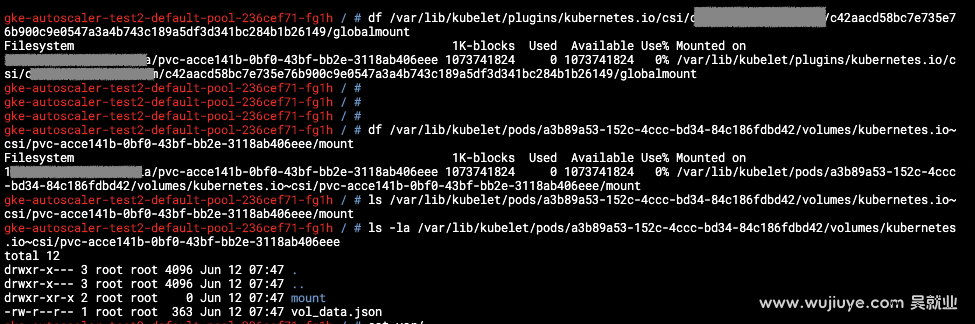
基于自定义的csi驱动,通过实验串联理解真个csi的工作流程。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。