![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 641 0 2024-02-04
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/13bed766a9174e27bb2a95afcee5a790
作者:吴就业
链接:https://wujiuye.com/article/13bed766a9174e27bb2a95afcee5a790
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
之三:基于request的K8s目标负载感知调度器
本篇介绍的内容是scheduler-plugins框架的TargetLoadPacking插件,这是一个k8s调度框架的评分插件。TargetLoadPacking即目标负载调度器,用于控制节点的CPU利用率不超过目标值x%(例如65%),通过打分让所有cpu利用率超过x%的都不被选中。目标负载调度器只支持CPU。官方文档:https://github.com/kubernetes-sigs/scheduler-plugins/blob/master/kep/61-Trimaran-real-load-aware-scheduling/README.md。
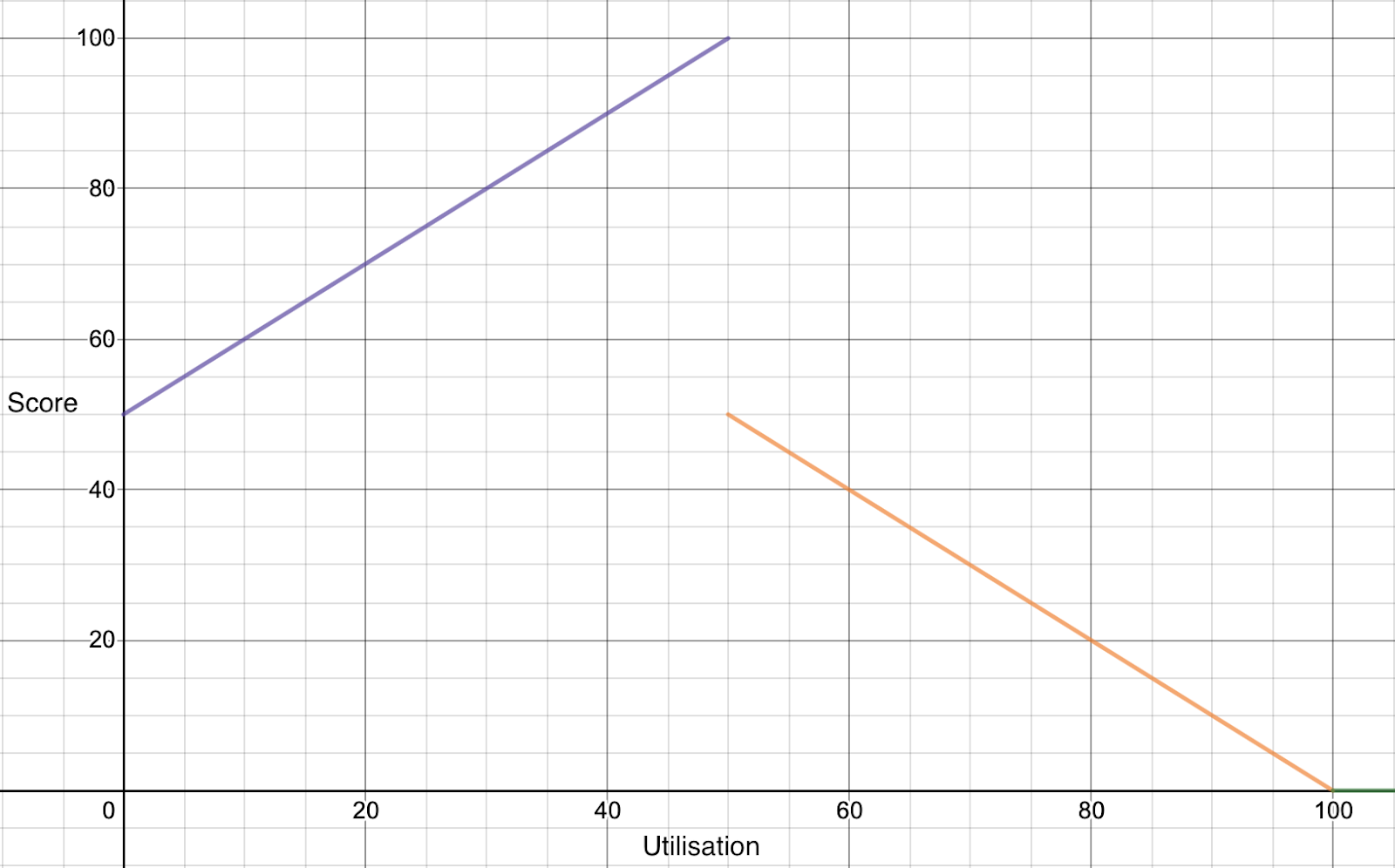
使用此插件结合LoadVariationRiskBalancing插件,可以保证在负载均衡调度的基础上,保证节点不会超负载,确保服务的稳定运行。成本的优化一定是建立在稳定性之上的。
同LoadVariationRiskBalancing插件的实验,由于官方的chart并不支持基于负载调度的几个插件,需要单独写Helm Chart。参考官方提供的as-a-second-scheduler这个Chart去改。scheduler-plugins包含Scheduler和Controller,基于负载调度的几个插件并不依赖Controller,因此Controller不需要部署,相关的yaml不需要写。
为访问metrics-api的相关资源授予权限(rbac)。
metrics-api-rbac.yaml:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: sched-plugins-metrics-api-reader-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: sched-plugins-metrics-api-reader-role
subjects:
- kind: ServiceAccount
name: {{ .Values.scheduler.name }}
namespace: {{ .Release.Namespace }}
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: sched-plugins-metrics-api-reader-role
rules:
- apiGroups:
- "metrics.k8s.io"
resources:
- PodMetrics
- NodeMetrics
verbs:
- get
- list
- watch
插件的配置: “TargetLoadPacking”,“LoadVariationRiskBalancing”,“LowRiskOverCommitment” 这三个不能一起使用,如果metricProvider使用KubernetesMetricsServer。会抛异常:panic: http: multiple registrations for /watcher。
这里只需验证TargetLoadPacking(目标负责调度插件),插件的配置如下,将目标负载配置为10%:
pluginConfig:
- name: TargetLoadPacking
args:
defaultRequests:
cpu: "1000m" # pod未配置request时
defaultRequestsMultiplier: "1" # 用于计算预测cpu利用率,一个允许超过request的突增系数
targetUtilization: 30 # 目标cpu利用率30%
metricProvider:
type: KubernetesMetricsServer
启用的插件给一个非常大的权重值,避免存在其它不知道的Score插件影响实验数据。(由于个人没有权限查看集群中启用了哪些Score插件。)
{{- if .Values.plugins.enabled }}
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: {{ .Release.Namespace }}
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: {{ .Values.scheduler.leaderElect }}
profiles:
# Compose all plugins in one profile
- schedulerName: {{ .Values.scheduler.name }}
plugins:
multiPoint:
enabled:
{{- range $.Values.plugins.enabled }}
- name: {{ title . }}
weight: 10000
{{- end }}
disabled:
{{- range $.Values.plugins.disabled }}
- name: {{ title . }}
{{- end }}
{{- if $.Values.pluginConfig }}
pluginConfig: {{ toYaml $.Values.pluginConfig | nindent 6 }}
{{- end }}
{{- end }}
将demo的Pod通过调用接口模拟cpu使用率到30%。
curl "http://127.0.0.1:8080/cpu?usage=30"
第一次实验发现数据跟插件描述的效果不一致,研究代码发现计算预测节点cpu使用率不是用pod的实时负载数据,而是用Pod的request和limit,并且如果Pod配置了limit,那么就会实验limit。官网的说法是,使用当前Pod的总CPU限制而不是请求,可以获得更强的预期利用率上限。但是,如果取limit的话,由于limit配置都会很大,直接>100%了,所以导致所有node的score计算结果都为0,最终看到的就是这个插件压根不生效。
所有我们需要改掉算法,不取limit,而是取request,当然,后期如果真实实验的话,应该是取Pod的实时指标,而不是request(如果request很接近真实值的话,可以直接用request)。
// PredictUtilisation Predict utilization for a container based on its requests/limits
func PredictUtilisation(container *v1.Container) int64 {
//if _, ok := container.Resources.Limits[v1.ResourceCPU]; ok {
// return container.Resources.Limits.Cpu().MilliValue()
//} else
if _, ok := container.Resources.Requests[v1.ResourceCPU]; ok {
// 如果request能够非常接近真实情况的话,requestsMultiplier配置为1或者1.2这样就可以。
return int64(math.Round(float64(container.Resources.Requests.Cpu().MilliValue()) * requestsMultiplier))
} else {
return requestsMilliCores
}
}
继续实验后,发现实际负载很高的node反而评分更高,研究代码发现,由于用于实验的几个节点还部署了一些默认的Pod,它们的request值都很高,影响了实验的准确性。所以通过namespace把集群已经部署的pod过滤掉,提升实验数据的可靠性。
for _, info := range pl.eventHandler.ScheduledPodsCache[nodeName] {
// 做实验跳过
if info.Pod.Namespace != "default" {
continue
}
// 这里面的逻辑是循环获取已经部署在这个node上的pod的cpu request.
}
当前节点的负载情况,主要关注CPU。
wujiuye@wujiuyedeMacBook-Pro cloud_native % kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-521b9803-71zk 341m 36% 1074Mi 38%
gke-nebula-test-cluster-default-pool-521b9803-ncck 57m 6% 1144Mi 40%
gke-nebula-test-cluster-default-pool-521b9803-r408 88m 9% 1455Mi 51%
给go-web-demo添加副本数后,查看调度插件打印的日记,预测的CPU使用率和计算的得分如下。注:预测的CPU利用率是根据request预测和节点当前利用率计算得出,不等于真实利用率,只有request接近真实值,这个预测才准确。
71zk: 预测cpu使用率为22.05%,分值为81。
I0119 06:04:35.421210 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-6r9r4" cpuUsage=100
I0119 06:04:35.421257 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuUtilMillis=341 cpuCapMillis=2000
I0119 06:04:35.421284 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" missingCPUUtilMillis=0
I0119 06:04:35.421315 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" predictedCPUUsage=22.05 hostTargetUtilizationPercent=30
I0119 06:04:35.421352 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" score=81
r408:预测cpu使用率为9.4%,分值为52。
I0119 06:04:35.421407 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-6r9r4" cpuUsage=100
I0119 06:04:35.421435 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuUtilMillis=88.00000000000001 cpuCapMillis=2000
I0119 06:04:35.421471 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" missingCPUUtilMillis=0
I0119 06:04:35.421495 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" predictedCPUUsage=9.4 hostTargetUtilizationPercent=30
I0119 06:04:35.421527 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" score=52
ncck:预测cpu使用率为7.45%,分值为47。
I0119 06:04:35.421212 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-6r9r4" cpuUsage=100
I0119 06:04:35.421586 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuUtilMillis=49 cpuCapMillis=2000
I0119 06:04:35.421618 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" missingCPUUtilMillis=0
I0119 06:04:35.421642 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" predictedCPUUsage=7.45 hostTargetUtilizationPercent=30
I0119 06:04:35.421674 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" score=47
最终选择的节点是ncck,选择了得分最低的节点。
I0119 06:04:35.421959 1 default_binder.go:53] "Attempting to bind pod to node" pod="default/go-web-demo-56b6c86796-6r9r4" node="gke-nebula-test-cluster-default-pool-521b9803-ncck"
继续增加1个节点。
71zk: 预测cpu使用率为22.05%,分值为81。
I0119 06:12:31.296693 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-sqhmg" cpuUsage=100
I0119 06:12:31.296829 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuUtilMillis=341 cpuCapMillis=2000
I0119 06:12:31.296874 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" missingCPUUtilMillis=0
I0119 06:12:31.296903 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" predictedCPUUsage=22.05 hostTargetUtilizationPercent=30
I0119 06:12:31.296934 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" score=81
ncck:预测cpu使用率为9.4%,分值为52。
I0119 06:12:31.296693 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-sqhmg" cpuUsage=100
I0119 06:12:31.297023 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuUtilMillis=49 cpuCapMillis=2000
I0119 06:12:31.297054 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" missingCPUUtilMillis=0
I0119 06:12:31.297103 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" predictedCPUUsage=7.45 hostTargetUtilizationPercent=30
I0119 06:12:31.297136 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" score=47
r408:预测cpu使用率为7.45%,分值为47。
I0119 06:12:31.296760 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-sqhmg" cpuUsage=100
I0119 06:12:31.297176 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuUtilMillis=86 cpuCapMillis=2000
I0119 06:12:31.297202 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" missingCPUUtilMillis=0
I0119 06:12:31.297227 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" predictedCPUUsage=9.3 hostTargetUtilizationPercent=30
I0119 06:12:31.297259 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" score=52
最终选择的节点是71zk,这次是选择了得分最高的节点。
I0119 06:12:31.297547 1 default_binder.go:53] "Attempting to bind pod to node" pod="default/go-web-demo-56b6c86796-sqhmg" node="gke-nebula-test-cluster-default-pool-521b9803-71zk"
这个数据感觉明显有问题,猜测是有其它评分插件影响,可能未禁用或者漏禁用哪些插件。
一个简单的办法,就是给这个插件配置一个非常高的权重,例如配置为10000。修改后重新实验。
当前节点情况:
wujiuye@wujiuyedeMacBook-Pro cloud_native % kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-521b9803-71zk 340m 36% 1081Mi 38%
gke-nebula-test-cluster-default-pool-521b9803-ncck 49m 5% 1143Mi 40%
gke-nebula-test-cluster-default-pool-521b9803-r408 92m 9% 1448Mi 51%
71zk: 节点当前cpu已使用342m,预测cpu使用率为32.1%,分值为29。当前节点部署了两个go-web-demo的Pod,之前实验留下的,然后删除了sqhmg这个Pod触发了这次Pod的调度,所以这次调度结束后,该节点只剩下6xslf这个Pod。
I0119 06:41:36.553966 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-f2cpg" cpuUsage=100
I0119 06:41:36.554085 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuUtilMillis=342 cpuCapMillis=2000
I0119 06:41:36.554200 1 targetloadpacking.go:167] "Missing utilization for pod" podName="go-web-demo-56b6c86796-6xslf" missingCPUUtilMillis=100
I0119 06:41:36.554379 1 targetloadpacking.go:167] "Missing utilization for pod" podName="go-web-demo-56b6c86796-sqhmg" missingCPUUtilMillis=200
I0119 06:41:36.554233 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-f2cpg" cpuUsage=100
I0119 06:41:36.554629 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" missingCPUUtilMillis=200
I0119 06:41:36.554799 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" predictedCPUUsage=32.1 hostTargetUtilizationPercent=30
I0119 06:41:36.554993 1 targetloadpacking.go:183] "Penalised score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" penalisedScore=29
r408:节点当前cpu已使用90m,预测cpu使用率为9.5,分值为52。当前节点未部署任何go-web-demo的Pod。
I0119 06:41:36.554598 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuUtilMillis=90 cpuCapMillis=2000
I0119 06:41:36.555053 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" missingCPUUtilMillis=0
I0119 06:41:36.555087 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" predictedCPUUsage=9.5 hostTargetUtilizationPercent=30
I0119 06:41:36.555163 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" score=52
ncck:节点当前cpu已使用64m,预测cpu使用率为18.2,分值为72。当前节点部署了一个go-web-demo,上次实验留下的。然后这个节点还部署了调度器插件本身,因为也是在default这个namespace,被一起算进去了。
I0119 06:41:36.553987 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-f2cpg" cpuUsage=100
I0119 06:41:36.555259 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuUtilMillis=64 cpuCapMillis=2000
I0119 06:41:36.555294 1 targetloadpacking.go:167] "Missing utilization for pod" podName="go-web-demo-56b6c86796-6r9r4" missingCPUUtilMillis=100
I0119 06:41:36.555341 1 targetloadpacking.go:167] "Missing utilization for pod" podName="scheduler-plugins-scheduler-855c6b8777-7nrnr" missingCPUUtilMillis=200
I0119 06:41:36.555372 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" missingCPUUtilMillis=200
I0119 06:41:36.555463 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" predictedCPUUsage=18.2 hostTargetUtilizationPercent=30
I0119 06:41:36.555552 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" score=72
这次的评分就正常了。然后最终选择的节点是ncck,得分最高,没有问题。
继续扩容1个节点。
71zk: 当前节点cpu已使用358m,预测cpu使用率为32.9%,分值为29。当前节点部署了一个go-web-demo的Pod(6xslf)。
I0119 07:14:19.205037 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-phb48" cpuUsage=100
I0119 07:14:19.205115 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuUtilMillis=358 cpuCapMillis=2000
I0119 07:14:19.205170 1 targetloadpacking.go:167] "Missing utilization for pod" podName="go-web-demo-56b6c86796-6xslf" missingCPUUtilMillis=100
I0119 07:14:19.205240 1 targetloadpacking.go:167] "Missing utilization for pod" podName="scheduler-plugins-scheduler-855c6b8777-q7dqc" missingCPUUtilMillis=200
I0119 07:14:19.205306 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" missingCPUUtilMillis=200
I0119 07:14:19.205392 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" predictedCPUUsage=32.9 hostTargetUtilizationPercent=30
I0119 07:14:19.205466 1 targetloadpacking.go:183] "Penalised score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" penalisedScore=29
r408:节点当前cpu已使用83m,预测cpu使用率为9.15,分值为51。当前节点未部署任何go-web-demo的Pod。
I0119 07:14:19.206181 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuUtilMillis=83 cpuCapMillis=2000
I0119 07:14:19.206246 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" missingCPUUtilMillis=0
I0119 07:14:19.206331 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" predictedCPUUsage=9.15 hostTargetUtilizationPercent=30
I0119 07:14:19.206416 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" score=51
ncck:节点当前cpu已使用49m,预测cpu使用率为17.45,分值为71。当前节点部署了两个go-web-demo(6r9r4、f2cpg)。
I0119 07:14:19.205563 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-phb48" cpuUsage=100
I0119 07:14:19.205642 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuUtilMillis=49 cpuCapMillis=2000
I0119 07:14:19.205725 1 targetloadpacking.go:167] "Missing utilization for pod" podName="go-web-demo-56b6c86796-6r9r4" missingCPUUtilMillis=100
I0119 07:14:19.205791 1 targetloadpacking.go:167] "Missing utilization for pod" podName="go-web-demo-56b6c86796-f2cpg" missingCPUUtilMillis=200
I0119 07:14:19.205872 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" missingCPUUtilMillis=200
I0119 07:14:19.205949 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" predictedCPUUsage=17.45 hostTargetUtilizationPercent=30
I0119 07:14:19.206024 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" score=71
最终选择得分最高的节点,节点为ncck。
I0119 07:14:19.206869 1 default_binder.go:53] "Attempting to bind pod to node" pod="default/go-web-demo-56b6c86796-phb48" node="gke-nebula-test-cluster-default-pool-521b9803-ncck"
当前节点和demo pod的部署情况。
节点cpu使用情况:
wujiuye@wujiuyedeMacBook-Pro cloud_native % kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-nebula-test-cluster-default-pool-521b9803-71zk 345m 36% 1138Mi 40%
gke-nebula-test-cluster-default-pool-521b9803-ncck 45m 4% 1187Mi 42%
gke-nebula-test-cluster-default-pool-521b9803-r408 82m 8% 1457Mi 51%
可以遇见的是,下一个pod还是会调度到ncck节点,因为该节点当前cpu使用最低。
继续扩容节点1个。
ncck节点:
I0119 07:25:29.272443 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-p6zqv" cpuUsage=100
I0119 07:25:29.272687 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuUtilMillis=47 cpuCapMillis=2000
I0119 07:25:29.272732 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" missingCPUUtilMillis=0
I0119 07:25:29.272759 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" predictedCPUUsage=7.35 hostTargetUtilizationPercent=30
I0119 07:25:29.272457 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-p6zqv" cpuUsage=100
I0119 07:25:29.272787 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" score=47
r408节点:
I0119 07:25:29.272806 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuUtilMillis=84 cpuCapMillis=2000
I0119 07:25:29.272864 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" missingCPUUtilMillis=0
I0119 07:25:29.272962 1 targetloadpacking.go:177] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" predictedCPUUsage=9.2 hostTargetUtilizationPercent=30
I0119 07:25:29.273055 1 targetloadpacking.go:189] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" score=51
71zk节点:
I0119 07:25:29.272570 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-p6zqv" cpuUsage=100
I0119 07:25:29.273242 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuUtilMillis=345 cpuCapMillis=2000
I0119 07:25:29.273369 1 targetloadpacking.go:171] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" missingCPUUtilMillis=0
这次翻车了,选择了cpu负载最高的节点,但从日记看,这几个节点都没有go-web-demo的Pod参与计算。
从代码来看,可能的原因是Pod的指标过期没更新。
for _, info := range pl.eventHandler.ScheduledPodsCache[nodeName] {
// 做实验用
if info.Pod.Namespace != "default" {
continue
}
// If the time stamp of the scheduled pod is outside fetched metrics window, or it is within metrics reporting interval seconds, we predict util.
// Note that the second condition doesn't guarantee metrics for that pod are not reported yet as the 0 <= t <= 2*metricsAgentReportingIntervalSeconds
// t = metricsAgentReportingIntervalSeconds is taken as average case and it doesn't hurt us much if we are
// counting metrics twice in case actual t is less than metricsAgentReportingIntervalSeconds
if info.Timestamp.Unix() > allMetrics.Window.End || info.Timestamp.Unix() <= allMetrics.Window.End &&
(allMetrics.Window.End-info.Timestamp.Unix()) < metricsAgentReportingIntervalSeconds {
for _, container := range info.Pod.Spec.Containers {
missingCPUUtilMillis += PredictUtilisation(&container)
}
missingCPUUtilMillis += info.Pod.Spec.Overhead.Cpu().MilliValue()
klog.V(6).InfoS("Missing utilization for pod", "podName", info.Pod.Name, "missingCPUUtilMillis", missingCPUUtilMillis)
}
}
这个Timestamp在每次更新pod的时候更新,是插件刚启动的时候会全量的拿一次所有的Pod,之后通过Informer去监听Pod的更新,除了Pod的新增删除,Pod的更新只会在Pod飘到其它Node的情况才会更新这个Timestamp。
然后就是还有一个定时任务,每5分钟会将Timestamp+1分钟还小于当前时间的Pod缓存删除(也可能不删除保留,但是数据还是过期的)。这就导致插件启动,过几分钟后,基本缓存就是空的了。
实在没理解,这么明显的bug也不可能,由于搞不清楚原因。先注释掉这个条件继续实验。
for _, info := range pl.eventHandler.ScheduledPodsCache[nodeName] {
// 做实验用
if info.Pod.Namespace != "default" {
continue
}
klog.V(6).InfoS("", "timestamp", info.Timestamp, "pod", info.Pod.Name)
// If the time stamp of the scheduled pod is outside fetched metrics window, or it is within metrics reporting interval seconds, we predict util.
// Note that the second condition doesn't guarantee metrics for that pod are not reported yet as the 0 <= t <= 2*metricsAgentReportingIntervalSeconds
// t = metricsAgentReportingIntervalSeconds is taken as average case and it doesn't hurt us much if we are
// counting metrics twice in case actual t is less than metricsAgentReportingIntervalSeconds
//if info.Timestamp.Unix() > allMetrics.Window.End || info.Timestamp.Unix() <= allMetrics.Window.End &&
// (allMetrics.Window.End-info.Timestamp.Unix()) < metricsAgentReportingIntervalSeconds {
for _, container := range info.Pod.Spec.Containers {
missingCPUUtilMillis += PredictUtilisation(&container)
}
missingCPUUtilMillis += info.Pod.Spec.Overhead.Cpu().MilliValue()
klog.V(6).InfoS("Missing utilization for pod", "podName", info.Pod.Name, "missingCPUUtilMillis", missingCPUUtilMillis)
//}
}
这次更新插件等待5分钟之后,再增加节点,验证节点的调度情况。
71zk节点:其中899pg这个Pod是本次实验删除重新调度到其它节点的demo Pod,所以71zk节点当前一共有两个demo的Pod。节点当前cpu使用342m,预测cpu使用率为32.1%,分值为29。
I0119 09:18:40.116007 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-gp5q9" cpuUsage=100
I0119 09:18:40.116173 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" cpuUtilMillis=342 cpuCapMillis=2000
I0119 09:18:40.116362 1 targetloadpacking.go:168] "Missing utilization for pod" podName="go-web-demo-56b6c86796-6xslf" missingCPUUtilMillis=100
I0119 09:18:40.116013 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-gp5q9" cpuUsage=100
I0119 09:18:40.116552 1 targetloadpacking.go:168] "Missing utilization for pod" podName="go-web-demo-56b6c86796-899pg" missingCPUUtilMillis=200
I0119 09:18:40.116622 1 targetloadpacking.go:172] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" missingCPUUtilMillis=200
I0119 09:18:40.116699 1 targetloadpacking.go:178] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" predictedCPUUsage=32.1 hostTargetUtilizationPercent=30
I0119 09:18:40.116782 1 targetloadpacking.go:184] "Penalised score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-71zk" penalisedScore=29
r408节点:r408当前未部署任何demo的pod节点。节点当前cpu使用86m,预测cpu使用率为9.3%,分值为52。
I0119 09:18:40.116093 1 targetloadpacking.go:125] "Predicted utilization for pod" podName="go-web-demo-56b6c86796-gp5q9" cpuUsage=100
I0119 09:18:40.116962 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" cpuUtilMillis=86 cpuCapMillis=2000
I0119 09:18:40.117044 1 targetloadpacking.go:172] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" missingCPUUtilMillis=0
I0119 09:18:40.117130 1 targetloadpacking.go:178] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" predictedCPUUsage=9.3 hostTargetUtilizationPercent=30
I0119 09:18:40.117221 1 targetloadpacking.go:190] "Score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-r408" score=52
ncck节点:当前部署了4个demo的pod节点,还有一个插件本身的Pod。节点当前cpu使用55m,预测cpu使用率为32.75%,分值为29。
I0119 09:18:40.117063 1 targetloadpacking.go:148] "Calculating CPU utilization and capacity" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" cpuUtilMillis=55 cpuCapMillis=2000
I0119 09:18:40.117430 1 targetloadpacking.go:168] "Missing utilization for pod" podName="go-web-demo-56b6c86796-6r9r4" missingCPUUtilMillis=100
I0119 09:18:40.117597 1 targetloadpacking.go:168] "Missing utilization for pod" podName="go-web-demo-56b6c86796-f2cpg" missingCPUUtilMillis=200
I0119 09:18:40.117769 1 targetloadpacking.go:168] "Missing utilization for pod" podName="go-web-demo-56b6c86796-phb48" missingCPUUtilMillis=300
I0119 09:18:40.117945 1 targetloadpacking.go:168] "Missing utilization for pod" podName="scheduler-plugins-scheduler-855c6b8777-hg2vj" missingCPUUtilMillis=400
I0119 09:18:40.118114 1 targetloadpacking.go:168] "Missing utilization for pod" podName="go-web-demo-56b6c86796-l578q" missingCPUUtilMillis=500
I0119 09:18:40.118200 1 targetloadpacking.go:172] "Missing utilization for node" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" missingCPUUtilMillis=500
I0119 09:18:40.118290 1 targetloadpacking.go:178] "Predicted CPU usage" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" predictedCPUUsage=32.75 hostTargetUtilizationPercent=30
I0119 09:18:40.118320 1 targetloadpacking.go:184] "Penalised score for host" nodeName="gke-nebula-test-cluster-default-pool-521b9803-ncck" penalisedScore=29
最终选择得分最高的r408节点,符合预期。
I0119 09:18:40.118872 1 default_binder.go:53] "Attempting to bind pod to node" pod="default/go-web-demo-56b6c86796-gp5q9" node="gke-nebula-test-cluster-default-pool-521b9803-r408"
TargetLoadPacking插件能够实现目标负载调度,但基于request预测的cpu使用率不准确,要确保TargetLoadPacking插件达到效果,request的值就必须要接近真实情况。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
Serverless帮助我们实现了自动扩缩容,但要实现真正的按需付费,就要使用弹性的物理节点,例如AWS的Fargate,使用EKS将Pod调度到Fargate上。这也注定了不会有固定的Node去运行Pod,因此在Node上以DaemonSet部署日记收集容器的方案就走不通了。
云原生的优势在于利用Serverless技术优化基础设施成本,要求应用启动速度快且内存占用低。然而,Java应用在自动弹性扩缩容和内存消耗方面存在问题。文章以部署个人项目的视角,通过比较小明使用Go语言和小聪使用Java语言开发的博客系统的部署情况,展示了Java的启动速度慢和内存占用大的不适应性。
验证gce的自动缩容时机以及扩容需要的时长:扩容一个节点需要等待多长时间,一个节点在没有Pod的情况下多久后会回收。结合scheduler-plugins框架验证。由于scheduler-plugins只是在Score阶段对节点打分,并未在其它阶段阻止Pod调度到分数为0的Node上,例如基于目标负载感知调度,当所有Node的负载都达到目标负载后,即便节点的requests满足Pod所需,是否能走扩容节点,而不是硬塞到现有节点上。
本篇介绍的内容是scheduler-plugins框架的LoadVariationRiskBalancing插件,这是一个k8s调度框架的评分插件,基于request、均值和标准差的K8s负载感知调度器。 我们通过实验去理解和验证该插件实现的负载感知均衡调度算法。
在降低增笑的大背景下,如何在保证稳定性的前提下,做到极致压缩k8s资源的使用,实现基础设施真正的按需付费,是我们云原生项目的目标之一。要实现如Railway这种产品的基础设施按实际使用付费,不能简单的使用云Serverless产品,因为这些产品都有最低限额的要求,例如阿里云最低限制要求Pod至少0.25cpu+0.5g内存,但其实大多数应用这个配额都用不到,大量的时间cpu负载几乎为0,内存消耗可能也就几十M(Java应用除外),大量的低使用率的Pod会造成资源的浪费。
我们在做云原生调度技术调研的时候,为了做实验获取一些数据,需要编写一个demo,支持动态模拟cup使用率和内存使用,所以用go开发了这么一个web程序。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。