![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 486 0 2024-05-09
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/7f9313a716354c589ffc56b18966bc5b
作者:吴就业
链接:https://wujiuye.com/article/7f9313a716354c589ffc56b18966bc5b
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
根据autoscaler项目README文档的介绍,我们可以通过配置启动参数--scale-down-unneeded-time=30s,将默认的缩容等待时间从10分钟降低到30秒。
实验:将demo副本数先增大到扩容出两个节点,再缩到1个副本释放一个节点出来,以触发缩容。
第一次实验结论是不生效。原因是有其它Pod调度到了这个弹性节点。
先给节点添加污点,并将这些Pod驱逐再重新实验。
增加污点后进行第二次实验,缩容时间大于5分钟,参数不生效,但感觉是比10分钟少了。
增加--v=2打印更多日记,重新验证一次,发现以下日志:

意思是每个节点间隔5分钟再检测节点是否可以缩减。
通过代码了解到,我们可以通过unremovable-node-recheck-timeout=30s启动参数将默认的每个节点间隔5分钟再检测节点是否可以缩减改为30秒。
重启并配置unremovable-node-recheck-timeout=30s启动参数,进行第三次实验,发现以下日志:

从日记了解到,超30秒后,会进行模拟节点删除,模拟删除成功后才可以继续后续逻辑。
Simulating node xxx removal意思是模拟节点删除。
node xxx may be removed意思是通过模拟删除成功,可以删除。
模拟的逻辑代码如下:
// SimulateNodeRemoval simulates removing a node from the cluster to check
// whether it is possible to move its pods. Depending on
// the outcome, exactly one of (NodeToBeRemoved, UnremovableNode) will be
// populated in the return value, the other will be nil.
func (r *RemovalSimulator) SimulateNodeRemoval(
nodeName string,
destinationMap map[string]bool,
timestamp time.Time,
remainingPdbTracker pdb.RemainingPdbTracker,
) (*NodeToBeRemoved, *UnremovableNode) {
nodeInfo, err := r.clusterSnapshot.NodeInfos().Get(nodeName)
if err != nil {
klog.Errorf("Can't retrieve node %s from snapshot, err: %v", nodeName, err)
}
klog.V(2).Infof("Simulating node %s removal", nodeName)
podsToRemove, daemonSetPods, blockingPod, err := GetPodsToMove(nodeInfo, r.deleteOptions, r.drainabilityRules, r.listers, remainingPdbTracker, timestamp)
if err != nil {
klog.V(2).Infof("node %s cannot be removed: %v", nodeName, err)
if blockingPod != nil {
return nil, &UnremovableNode{Node: nodeInfo.Node(), Reason: BlockedByPod, BlockingPod: blockingPod}
}
return nil, &UnremovableNode{Node: nodeInfo.Node(), Reason: UnexpectedError}
}
err = r.withForkedSnapshot(func() error {
return r.findPlaceFor(nodeName, podsToRemove, destinationMap, timestamp)
})
if err != nil {
klog.V(2).Infof("node %s is not suitable for removal: %v", nodeName, err)
return nil, &UnremovableNode{Node: nodeInfo.Node(), Reason: NoPlaceToMovePods}
}
klog.V(2).Infof("node %s may be removed", nodeName)
return &NodeToBeRemoved{
Node: nodeInfo.Node(),
PodsToReschedule: podsToRemove,
DaemonSetPods: daemonSetPods,
}, nil
}
但是从日记看并没有然后了,应该是缺少了一些日记,我们将日记输出级别改为--v=4,再获取一次日记。

这组日记刷了非常多,从代码了解到,日记最后一行输出的scaleDownInCooldown=true表示缩容还在冷却中,所以并没有去缩容。当scaleDownInCooldown=false后,才会执行缩容逻辑。
这是最后scaleDownInCooldown=false的日志。
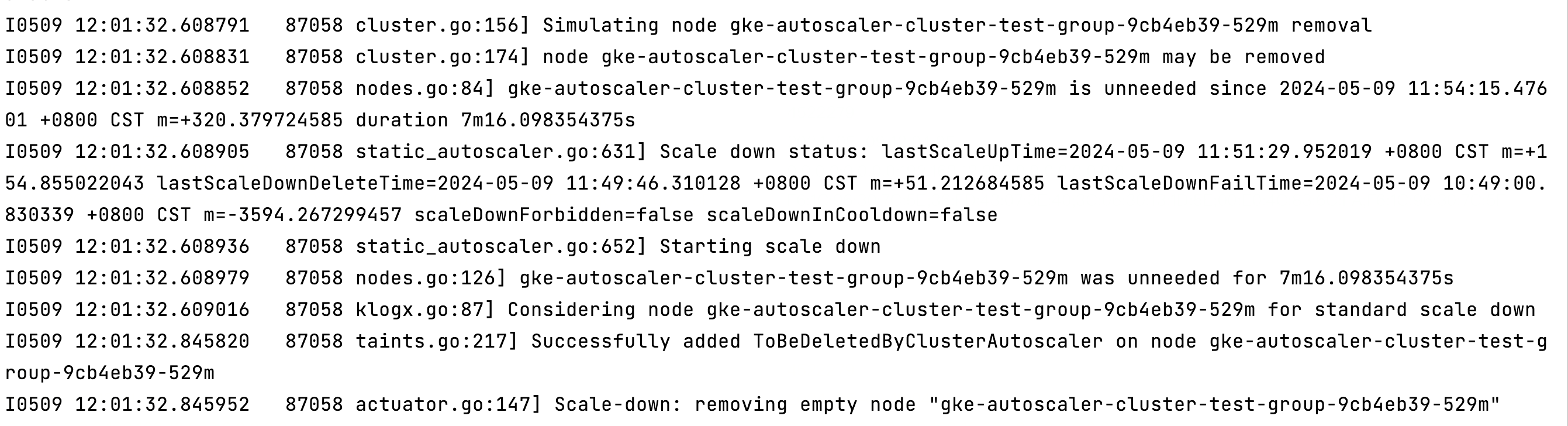
对应的代码是:
scaleDownInCooldown := a.isScaleDownInCooldown(currentTime, scaleDownCandidates)
......
if scaleDownInCooldown {
scaleDownStatus.Result = scaledownstatus.ScaleDownInCooldown
} else {
klog.V(4).Infof("Starting scale down")
.....
}
其中isScaleDownInCooldown方法的逻辑如下:
func (a *StaticAutoscaler) isScaleDownInCooldown(currentTime time.Time, scaleDownCandidates []*apiv1.Node) bool {
scaleDownInCooldown := a.processorCallbacks.disableScaleDownForLoop || len(scaleDownCandidates) == 0
if a.ScaleDownDelayTypeLocal {
return scaleDownInCooldown
}
return scaleDownInCooldown ||
a.lastScaleUpTime.Add(a.ScaleDownDelayAfterAdd).After(currentTime) ||
a.lastScaleDownFailTime.Add(a.ScaleDownDelayAfterFailure).After(currentTime) ||
a.lastScaleDownDeleteTime.Add(a.ScaleDownDelayAfterDelete).After(currentTime)
}
通过debug我们发现是a.lastScaleUpTime.Add(a.ScaleDownDelayAfterAdd).After(currentTime)这个条件返回了true。ScaleDownDelayAfterAdd 是设置从最后一次扩容到缩容的最小间隔时间,也就是缩容冷却时间。
lastScaleUpTime在扩容成功后会更新,代码如下。
if scaleUpStatus.Result == status.ScaleUpSuccessful {
a.lastScaleUpTime = currentTime
// No scale down in this iteration.
scaleDownStatus.Result = scaledownstatus.ScaleDownInCooldown
return true, nil
}
由于是做实验,所以我们都是扩容节点出来一分钟左右就触发缩容了。
这个缩容冷却逻辑我认为是合理的,避免了刚扩容就缩容、缩了之后又马上扩容的情况出现,这个时间默认是10分钟。
为了验证修改缩容时长是否生效,我们可以通过配置--scale-down-delay-after-add=30s启动参数来缩短这个缩容冷却时间到30秒。配置后,进行第四次实验。
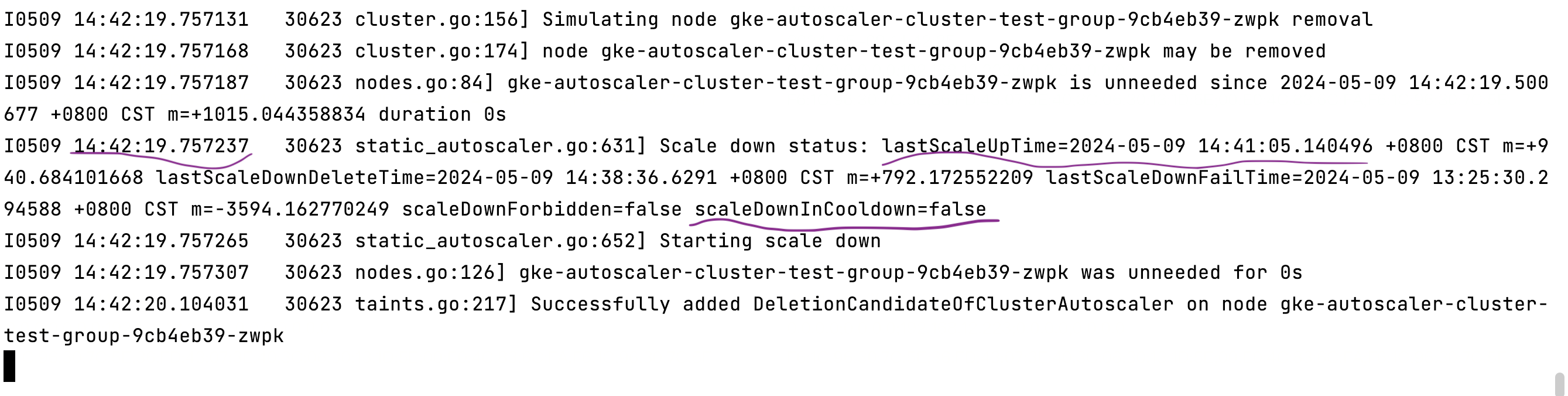
这次实现成功。
总结:想要缩短空闲节点被回收的时间,需要同时考虑三个启动参数的配置:
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
基于开源的autoscaler二次开发,通过自部署autoscaler来替代GKE提供的节点自动扩缩容能力,获取更好的扩展性和更灵活的配置。主要增强以下特性:支持目标负载扩容、更快的缩容速度、支持低负载自动缩容-重调度。
但其实我们忽略了一点,autoscaler是根据部署在节点上的所有Pod声明的requests来计算资源使用率的,这个并不能反应真实情况。
低负载自动缩容节点的这个特性还是非常有必要的,能够避免资源的过渡浪费。因为随着时间的推移,集群中势必会出现非常多的弹性节点利用率很低的情况。
想要让autoscaler支持自定义调度器触发节点扩展,有两种方案。一是autoscaler支持自定义调度器的过滤器插件,二是autoscaler取消check逻辑。
在google cloud上使用gke集群,gke已经集成autoscaler,通过在控制台创建节点池点击开启自动扩缩容就可以,那么为什么还要自己部署呢?怎么本地让autoscaler成功跑起来呢?
helm在获取values.yaml文件中配置的值时,由于没有对应一个结构体来反序列化yaml,只能使用map来接收,例如map[string]interface{}。可能是将interface{}尝试转成数字,能够转换成功helm就误以为我们需要的是数字了。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。