![]()
 云原生实战笔记 专栏收录该内容,点击查看专栏更多内容
云原生实战笔记 专栏收录该内容,点击查看专栏更多内容原创 吴就业 544 0 2024-05-11
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/41dac1afe27d47b2b9396468f8395d19
作者:吴就业
链接:https://wujiuye.com/article/41dac1afe27d47b2b9396468f8395d19
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
在前一篇文章“在google cloud上使用gke集群,如何自己部署autoscaler实现节点的自动扩缩容(四):低负载自动缩容与重调度”中,我们验证了autoscaler的低阈值缩容策略,确实可以用来实现我们的重调度需求,避免系统运行久了,会出现一些弹性节点的使用率非常低,导致资源被浪费的情况。
但其实我们忽略了一点,autoscaler是根据部署在节点上的所有Pod声明的requests来计算资源使用率的,这个并不能反应真实情况。

比如说,其中有一些Pod实际负载超过了requests,但并不没有超limits,属于合理的值内,如果按requests来算,可能使用率为50%,但按实际负载算,使用率已经80%了,这个时候是不应该将这个节点缩减的。
又比如说,其中有一些Pod的实际负载低于requests很多,如果按requests来算,可能使用率为70%,但按实际负载算,使用率可能只有30%,这个时候应该尝试将这个节点上的Pod驱逐到其它节点上,然后缩减该节点。
这是原来autoscaler实现的逻辑:(cluster-autoscaler/core/scaledown/eligibility/eligibility.go#unremovableReasonAndNodeUtilization)
ignoreDaemonSetsUtilization, err := c.configGetter.GetIgnoreDaemonSetsUtilization(nodeGroup)
if err != nil {
klog.Warningf("Couldn't retrieve `IgnoreDaemonSetsUtilization` option for node %v: %v", node.Name, err)
return simulator.UnexpectedError, nil
}
gpuConfig := context.CloudProvider.GetNodeGpuConfig(node)
utilInfo, err := utilization.Calculate(nodeInfo, ignoreDaemonSetsUtilization, context.IgnoreMirrorPodsUtilization, gpuConfig, timestamp)
if err != nil {
klog.Warningf("Failed to calculate utilization for %s: %v", node.Name, err)
}
其中utilization.Calculate是计算节点资源的使用率。
func Calculate(nodeInfo *schedulerframework.NodeInfo, skipDaemonSetPods, skipMirrorPods bool, gpuConfig *cloudprovider.GpuConfig, currentTime time.Time) (utilInfo Info, err error) {
if gpuConfig != nil {
......
}
// 计算cpu
cpu, err := CalculateUtilizationOfResource(nodeInfo, apiv1.ResourceCPU, skipDaemonSetPods, skipMirrorPods, currentTime)
if err != nil {
return Info{}, err
}
// 计算内存
mem, err := CalculateUtilizationOfResource(nodeInfo, apiv1.ResourceMemory, skipDaemonSetPods, skipMirrorPods, currentTime)
if err != nil {
return Info{}, err
}
// 选择最大的
utilization := Info{CpuUtil: cpu, MemUtil: mem}
if cpu > mem {
utilization.ResourceName = apiv1.ResourceCPU
utilization.Utilization = cpu
} else {
utilization.ResourceName = apiv1.ResourceMemory
utilization.Utilization = mem
}
return utilization, nil
}
CalculateUtilizationOfResource方法的实现就是计算部署在节点上的所有pod的requests总和,再除以节点的Allocatable,得到资源的使用率。当然还有是否排除DaemonSet的Pod的逻辑。 下面是简化后的CalculateUtilizationOfResource方法:
func CalculateUtilizationOfResource(nodeInfo *schedulerframework.NodeInfo, resourceName apiv1.ResourceName, skipDaemonSetPods, skipMirrorPods bool, currentTime time.Time) (float64, error) {
nodeAllocatable, found := nodeInfo.Node().Status.Allocatable[resourceName]
....
podsRequest := resource.MustParse("0")
// 遍历节点上的所有Pod
for _, podInfo := range nodeInfo.Pods {
requestedResourceList := resourcehelper.PodRequests(podInfo.Pod, opts)
resourceValue := requestedResourceList[resourceName]
.......
// 累加
podsRequest.Add(resourceValue)
}
// 计算使用率。 ()
return float64(podsRequest.MilliValue()) / float64(nodeAllocatable.MilliValue()), nil
}
autoscaler提供这种低阈值缩容策略并不能满足我们的需求,容易导致误伤。但我们可以通过改成用节点的实时负载来计算使用率,就能达到我们的目的-重调度。
只需要将开头的代码注释掉,改成下面这样:
//ignoreDaemonSetsUtilization, err := c.configGetter.GetIgnoreDaemonSetsUtilization(nodeGroup)
//if err != nil {
// klog.Warningf("Couldn't retrieve `IgnoreDaemonSetsUtilization` option for node %v: %v", node.Name, err)
// return simulator.UnexpectedError, nil
//}
//
//gpuConfig := context.CloudProvider.GetNodeGpuConfig(node)
//utilInfo, err := utilization.Calculate(nodeInfo, ignoreDaemonSetsUtilization, context.IgnoreMirrorPodsUtilization, gpuConfig, timestamp)
//if err != nil {
// klog.Warningf("Failed to calculate utilization for %s: %v", node.Name, err)
//}
nodeMetrics, err := getNodeResourceUsage(context.ClientSet.(*kubernetes.Clientset).RESTClient(), node.Name)
if err != nil {
klog.Warningf("Failed to get node metrics for %s: %v", node.Name, err)
}
utilInfo := calculateUsageUtil(nodeInfo, nodeMetrics)
其中getNodeResourceUsage方法和calculateUsageUtil方法的实现如下,我们通过Metrics API拿节点的实时指标数据。
func getNodeResourceUsage(cli rest.Interface, nodeName string) (*metricsv1beata1.NodeMetrics, error) {
req := cli.Get().RequestURI("/apis/metrics.k8s.io/v1beta1/nodes/" + nodeName).Do(context2.TODO())
nodeMetrics := &metricsv1beata1.NodeMetrics{}
return nodeMetrics, req.Into(nodeMetrics)
}
func calculateUsageUtil(nodeInfo *schedulerframework.NodeInfo, nodeMetrics *metricsv1beata1.NodeMetrics) utilization.Info {
nodeCPUCapMillis := float64(nodeInfo.Node().Status.Allocatable.Cpu().MilliValue())
cpuUsage := float64(nodeMetrics.Usage.Cpu().MilliValue()) / nodeCPUCapMillis
nodeMemoryCapBytes := float64(nodeInfo.Node().Status.Allocatable.Memory().Value())
memoryUsage := float64(nodeMetrics.Usage.Memory().Value()) / nodeMemoryCapBytes
klog.V(1).Infof("calculate node [%s] res usage util. cpu-cap %f cpu-usage %.2f memory-cap %f memory-usage %.2f",
nodeInfo.Node().Name, nodeCPUCapMillis, cpuUsage, nodeMemoryCapBytes, memoryUsage)
info := utilization.Info{CpuUtil: cpuUsage, MemUtil: memoryUsage}
if cpuUsage > memoryUsage {
info.ResourceName = apiv1.ResourceCPU
info.Utilization = cpuUsage
} else {
info.ResourceName = apiv1.ResourceMemory
info.Utilization = memoryUsage
}
return info
}
下面是本地debug的日志输出截图:

我们逐行了解下这份日志:
节点gke-autoscaler-cluster-test-group-9cb4eb39-bktq计算cpu使用率为6%,内存使用率为36%。
I0511 10:40:24.920484 77156 eligibility.go:216] calculate node [gke-autoscaler-cluster-test-group-9cb4eb39-bktq] res usage util. cpu-cap 940.000000 cpu-usage 0.06 memory-cap 2942287872.000000 memory-usage 0.36
取cpu和内存使用率的最大值,最大值是内存的使用率:36%。低于触发缩容的阈值,所以这个节点将会被autoscaler尝试缩减。
I0511 10:40:24.920644 77156 klogx.go:87] Node gke-autoscaler-cluster-test-group-9cb4eb39-bktq - memory requested is 36.0968% of allocatable
另一个节点是gke-autoscaler-cluster-test-group-9cb4eb39-l2pw,cpu使用率为107%,内存使用率为38%,取最大值为107%,由于高于阈值,所以该节点不满足低阈值缩容条件。
I0511 10:40:25.120816 77156 eligibility.go:216] calculate node [gke-autoscaler-cluster-test-group-9cb4eb39-l2pw] res usage util. cpu-cap 940.000000 cpu-usage 1.07 memory-cap 2942287872.000000 memory-usage 0.38
I0511 10:40:25.120928 77156 eligibility.go:174] Node gke-autoscaler-cluster-test-group-9cb4eb39-l2pw unremovable: cpu requested (107.234% of allocatable) is above the scale-down utilization threshold
接着是模拟将节点gke-autoscaler-cluster-test-group-9cb4eb39-bktq缩减,autoscaler想要尝试把gke-autoscaler-cluster-test-group-9cb4eb39-bktq节点的pod调度到gke-autoscaler-cluster-test-group-9cb4eb39-l2pw节点上,调用了我们自定义的过滤插件target_usage_filter_plugin,过滤插件计算gke-autoscaler-cluster-test-group-9cb4eb39-l2pw这个节点的cpu和内存使用率,由于cpu使用率为108%,所以过滤插件拒绝了将pod调度到这个节点上。
I0511 10:40:25.121039 77156 cluster.go:156] Simulating node gke-autoscaler-cluster-test-group-9cb4eb39-bktq removal
I0511 10:40:25.320570 77156 target_usage_filter_plugin.go:47] node gke-autoscaler-cluster-test-group-9cb4eb39-l2pw metrics cpu=1008 memory=1104760832
I0511 10:40:25.320663 77156 target_usage_filter_plugin.go:52] node gke-autoscaler-cluster-test-group-9cb4eb39-l2pw cpu usage 1.08. log by pod default/go-web-demo-748c879db5-2bq9m
过滤插件的代码实现如下:
var _ framework.FilterPlugin = &TargetUsageFilterPlugin{}
const (
Name = "TargetUsage"
)
func NewTargetUsageFilterPlugin(obj runtime.Object, handle framework.Handle) (framework.Plugin, error) {
return &TargetUsageFilterPlugin{
cli: handle.ClientSet().(*kubernetes.Clientset),
}, nil
}
type TargetUsageFilterPlugin struct {
cli *kubernetes.Clientset
}
func (c *TargetUsageFilterPlugin) Name() string {
return Name
}
func (c *TargetUsageFilterPlugin) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if strings.HasPrefix(nodeInfo.Node().Name, "template") { // Mock节点只判断规格是否满足即可
if pod.Spec.Containers[0].Resources.Requests.Cpu().MilliValue() < nodeInfo.Node().Status.Allocatable.Cpu().MilliValue() {
return framework.NewStatus(framework.Success, "")
}
return framework.NewStatus(framework.Unschedulable, "Node specification error.")
}
req := c.cli.RESTClient().Get().RequestURI("/apis/metrics.k8s.io/v1beta1/nodes/" + nodeInfo.Node().Name).Do(ctx)
nodeMetrics := &metricsv1beata1.NodeMetrics{}
if err := req.Into(nodeMetrics); err != nil {
return framework.NewStatus(framework.Unschedulable, "Req metrics error.")
}
klog.V(1).Infof("node %s metrics cpu=%d memory=%d", nodeInfo.Node().Name,
nodeMetrics.Usage.Cpu().MilliValue(), nodeMetrics.Usage.Memory().Value())
nodeCPUCapMillis := float64(nodeInfo.Node().Status.Allocatable.Cpu().MilliValue())
cpuUsage := float64(nodeMetrics.Usage.Cpu().MilliValue()+pod.Spec.Containers[0].Resources.Requests.Cpu().MilliValue()) / nodeCPUCapMillis
klog.V(1).Infof("node %s cpu usage %.2f. log by pod %s/%s", nodeInfo.Node().Name, cpuUsage, pod.Namespace, pod.Name)
if cpuUsage > 0.45 {
return framework.NewStatus(framework.Unschedulable, "The CPU reaches the threshold.")
}
nodeMemoryCapBytes := float64(nodeInfo.Node().Status.Allocatable.Memory().Value())
memoryUsage := float64(nodeMetrics.Usage.Memory().Value()+pod.Spec.Containers[0].Resources.Requests.Memory().Value()) / nodeMemoryCapBytes
klog.V(1).Infof("node %s memory usage %.2f. log by pod %s/%s", nodeInfo.Node().Name, memoryUsage, pod.Namespace, pod.Name)
if memoryUsage >= 0.75 {
return framework.NewStatus(framework.Unschedulable, "The memory reaches the threshold.")
}
return framework.NewStatus(framework.Success, "")
}
最后由于没有其它节点可以让节点gke-autoscaler-cluster-test-group-9cb4eb39-bktq上的Pod调度过去,所以gke-autoscaler-cluster-test-group-9cb4eb39-bktq节点并不能被缩减。
I0511 10:40:25.320712 77156 klogx.go:87] failed to find place for default/go-web-demo-748c879db5-2bq9m: cannot put pod go-web-demo-748c879db5-2bq9m on any node
I0511 10:40:25.320769 77156 cluster.go:171] node gke-autoscaler-cluster-test-group-9cb4eb39-bktq is not suitable for removal: can reschedule only 0 out of 1 pods
现在,我们将gke-autoscaler-cluster-test-group-9cb4eb39-l2pw这个节点的cpu使用率降低下来,验证是否gke-autoscaler-cluster-test-group-9cb4eb39-bktq节点是否正常缩减。

debug日志输出:
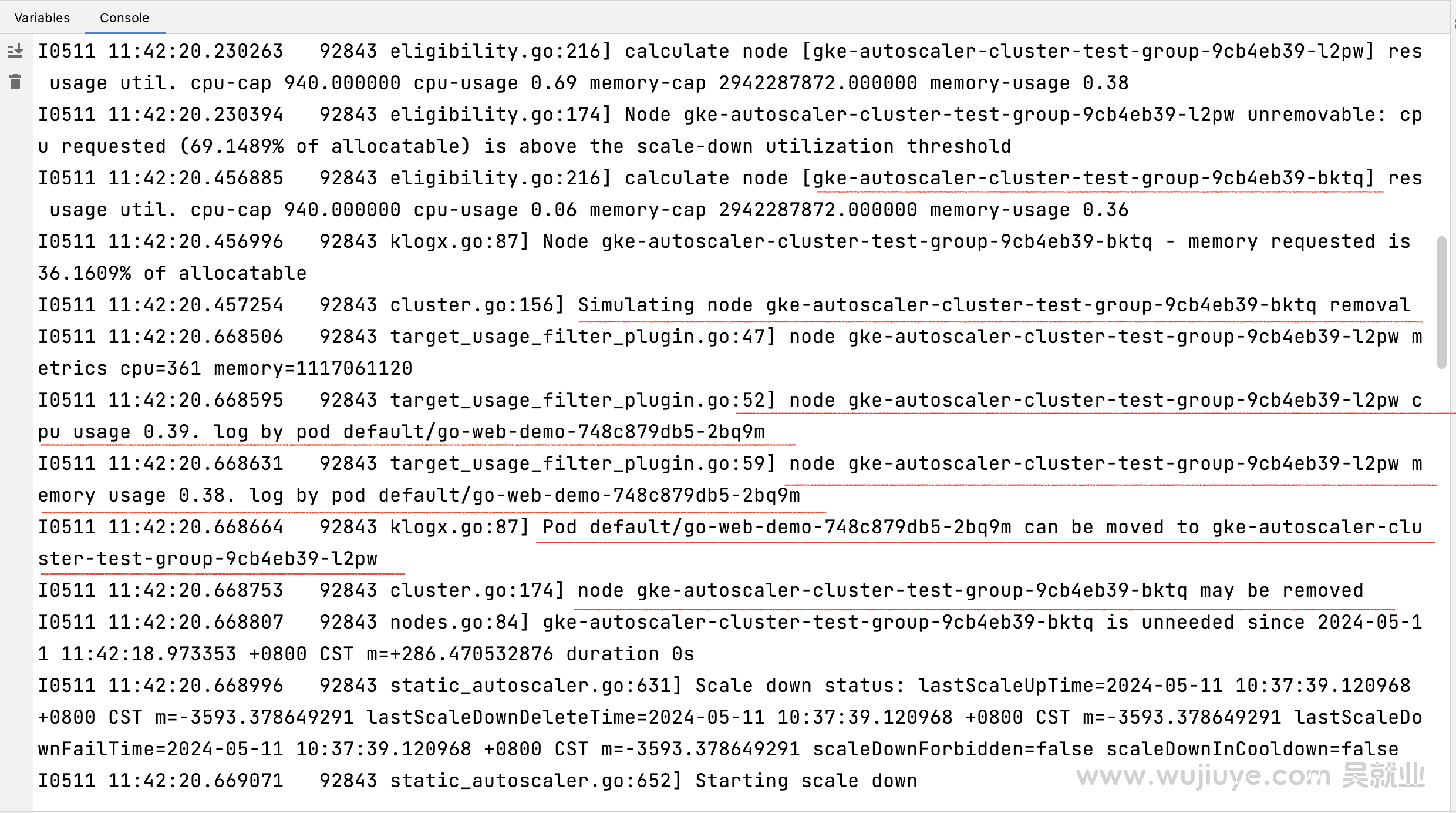
图中画线的日志意思是:bktq节点的cpu和内存使用率低于缩容阈值(--scale-down-utilization-threshold=0.5),所以触发了模拟缩容的逻辑。由于l2pw节点的cpu使用率低于0.45和内存使用率低于0.75,所以bktq节点上的pod go-web-demo-748c879db5-2bq9m可以调度到l2pw这个节点上,bktq模拟缩容成功,可以被删除。后面就是执行了缩容逻辑。
这块逻辑会影响到空节点不会被缩容。
因为autoscaler是先判断获取低负载的节点作为缩容候选节点,而是否空节点(除了DaemonSet的Pod没有其它Pod在这个节点上)是从低负载候选节点中进一步过滤的。如果一个空节点由于上面部署了很多的DaemonSet导致节点的负载高于阈值(scale-down-utilization-threshold),那么低负载候选节点就不会包含这个空节点,导致这个空节点不会进入后续是否空节点的逻辑判断,所以不会被缩减。
因此这里还需要做个判断,如果是空节点,直接返回负载0。
var utilInfo utilization.Info
if isEmptyNode(nodeInfo) {
utilInfo = utilization.Info{
ResourceName: apiv1.ResourceCPU,
Utilization: 0,
}
klog.V(4).Infof("%s is empty node, ignore node real-time metrics.", node.Name)
} else {
nodeMetrics, err := getNodeResourceUsage(context.ClientSet.(*kubernetes.Clientset).RESTClient(), node.Name)
if err != nil {
klog.Warningf("Failed to get node metrics for %s: %v", node.Name, err)
}
utilInfo = calculateUsageUtil(nodeInfo, nodeMetrics)
}
是否空节点的判断:
func isEmptyNode(nodeInfo *schedulerframework.NodeInfo) bool {
for _, podInfo := range nodeInfo.Pods {
pod := podInfo.Pod
if !pod_util.IsDaemonSetPod(pod) {
return false
}
}
return true
}
如果要进一步优化,应该优化实际负载的计算逻辑,将实际负载减去这些DaemonSet的Pod的实时负载,可通过Metrics API获取一个Pod的实时负载。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
我们在自己部署autoscaler到gke集群中的时候遇到了403的问题,这个问题后来我们自己部署gcp-filestore-csi-driver的时候也遇到了。
在gcp平台上,使用gke服务,创建一个k8s集群,若想在本地能够通过kubectl命令或者可视化工具访问到集群,需要通过gcloud命令获取访问集群的证书。
基于开源的autoscaler二次开发,通过自部署autoscaler来替代GKE提供的节点自动扩缩容能力,获取更好的扩展性和更灵活的配置。主要增强以下特性:支持目标负载扩容、更快的缩容速度、支持低负载自动缩容-重调度。
低负载自动缩容节点的这个特性还是非常有必要的,能够避免资源的过渡浪费。因为随着时间的推移,集群中势必会出现非常多的弹性节点利用率很低的情况。
autoscaler,想要缩短空闲节点被回收的时间,需要同时考虑三个启动参数的配置:scale-down-unneeded-time、unremovable-node-recheck-timeout、scale-down-delay-after-add。
想要让autoscaler支持自定义调度器触发节点扩展,有两种方案。一是autoscaler支持自定义调度器的过滤器插件,二是autoscaler取消check逻辑。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。