![]()
本篇文章写于2019年12月29日,从公众号同步过来(博客搬家),本篇为原创文章。
Http全称为超文本传输协议,是一种无状态协议。即不会记录你上一次访问了什么。一应一答,一个请求一个响应,无需保持连接。
在不保持长连接的情况下,一次http请求响应的过程为,客户端与服务器建立一个socket连接,tcp协议完成三次握手,客户端开始发送请求,客户端同步阻塞等待,服务端接收到请求,处理请求并响应给客户端,接着断开连接,tcp完成四次挥手,一次请求响应结束。
Http协议的数据包与我们平常所见的一些协议或是自定义协议的数据包区别很大,没有数据包的开始标志,如魔数;没有数据包长度,也无法在解码之前计算出长度,只有请求body长度。http协议数据包的请求头并没有固定大小,请求头可以添加任意多个,通过换行符分割。
要解析出一个完整的http数据包,首先需要找到请求行,经过一步步探测得到,从请求行的后一行开始就是请求头,但请求头也没有固定长度,所以需要请求头后面需要加一个空行标志请求头的结束。请求头后面就是请求body,请求body是有长度的,解析完请求头之后可从请求头中获取到Context-Length,通过它拿到请求body的长度。Context-Length是必须的请求头参数,如果没有指定该请求头参数,则默认为0。如果长度指定并非body的真实长度,那么body就会解析出错。虽然body会解析出错,但已经能解析出这是一个http请求的数据包,所以服务端会响应出错信息,而不是当作没有接收到这个请求。
Http协议是使用ascii码字符集的,一个字符只会占用一个字节,因此url上不能出现中文字符,否则会被编码为十六进制表示。但请求body我们可以传输中文,因为body是根据Content-type请求头参数解析的,该参数描述body是一张图片还是一个表单,还是普通文本,还是json字符串等,且指定编码,默认为utf8。
基于netty分析http协议数据包解码过程
如果我们想自己基于Netty实现一个简单轻量级的http服务器,不使用netty提供的编解码支持,那么我们就必须要了解http协议。http协议定义的数据帧格式包括三部分:请求行、请求头(包括一个空白行),请求body。
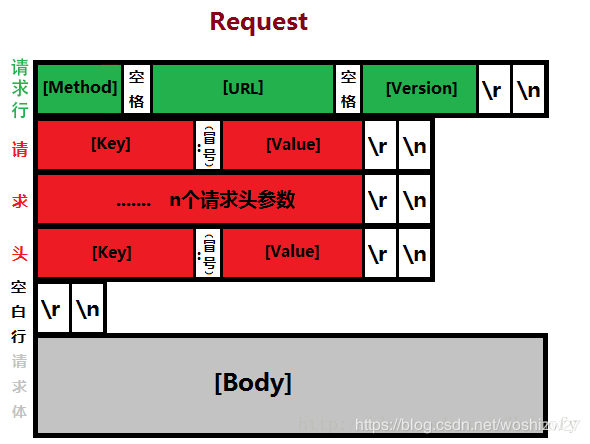
(从网上找的一张图,来自csdn博客)
今天我们来分析下netty是如何解析http协议数据包的。重点是分析HttpObjectDecoder类的decode方法的源码,http协议数据包的解码操作都是在该方法中完成的。
为了容易理解,我还是选择去掉了一部分代码。我还是坚持以让读者能看懂明白为目的,分析源码并不会分析到方方面面,更多的是带大家过一遍源码,对整个流程有一个初步的了解,更多的还是需要读者自己去看源码。
即便删减了一部分代码,代码依然很多,不过都写有注释,嫌代码长不想看也没关系,我还会将整个方法拆分为几个步骤分析。
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {
if (resetRequested) {
resetNow();
}
// 根据当前状态判断解码到哪了,每个case后面都没有break,所以是顺序执行case的。
switch (currentState) {
case SKIP_CONTROL_CHARS: {
// 跳过控制符和空白符,从第一个非控制符和空白符开始,如果返回false,
// 则认为没有找到数据包的,直接结束解码
if (!skipControlCharacters(buffer)) {
return;
}
// 将状态标志为读取请求行,下一步就是解码请求行
currentState = State.READ_INITIAL;
}
// 注意,没有break
case READ_INITIAL:
try {
// 从buffer中读取一行数据,遇到回车换行符为一行
// 如果读取不到,则结束
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
// 按" "空格符号分割字符串
String[] initialLine = splitInitialLine(line);
if (initialLine.length < 3) {
// 无效请求行,忽略,重置状态标志,结束解析
currentState = State.SKIP_CONTROL_CHARS;
return;
}
// 请求行解析正确,创建消息
message = createMessage(initialLine);
// 将状态设置为开始读取请求头
currentState = State.READ_HEADER;
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
// 没有break,会接着继续解析
case READ_HEADER:
try {
// 读取请求头
State nextState = readHeaders(buffer);
if (nextState == null) {
return;
}
currentState = nextState;
switch (nextState) {
case SKIP_CONTROL_CHARS:
// fast-path
// No content is expected.
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
case READ_CHUNK_SIZE:
if (!chunkedSupported) {
throw new IllegalArgumentException("Chunked messages not supported");
}
// Chunked encoding - generate HttpMessage first. HttpChunks will follow.
out.add(message);
return;
default:
/**
* <a href="https://tools.ietf.org/html/rfc7230#p-3.3.3">RFC 7230, 3.3.3</a> states that if a
* request does not have either a transfer-encoding or a content-length header then the message body
* length is 0. However for a response the body length is the number of octets received prior to the
* server closing the connection. So we treat this as variable length chunked encoding.
*/
// 读取content-length获取body长度
long contentLength = contentLength();
if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {
out.add(message);
out.add(LastHttpContent.EMPTY_LAST_CONTENT);
resetNow();
return;
}
assert nextState == State.READ_FIXED_LENGTH_CONTENT || nextState == State.READ_VARIABLE_LENGTH_CONTENT;
out.add(message);
if (nextState == State.READ_FIXED_LENGTH_CONTENT) {
// chunkSize will be decreased as the READ_FIXED_LENGTH_CONTENT state reads data chunk by chunk.
chunkSize = contentLength;
}
// We return here, this forces decode to be called again where we will decode the content
return;
}
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
case READ_FIXED_LENGTH_CONTENT: {
// 读取固定长度的body
int readLimit = buffer.readableBytes();
// Check if the buffer is readable first as we use the readable byte count
// to create the HttpChunk. This is needed as otherwise we may end up with
// create a HttpChunk instance that contains an empty buffer and so is
// handled like it is the last HttpChunk.
//
// See https://github.com/netty/netty/issues/433
if (readLimit == 0) {
return;
}
int toRead = Math.min(readLimit, maxChunkSize);
if (toRead > chunkSize) {
toRead = (int) chunkSize;
}
ByteBuf content = buffer.readRetainedSlice(toRead);
chunkSize -= toRead;
if (chunkSize == 0) {
// Read all content.
out.add(new DefaultLastHttpContent(content, validateHeaders));
resetNow();
} else {
out.add(new DefaultHttpContent(content));
}
return;
}
case BAD_MESSAGE: {
// 消息解析失败,丢弃buffer中的内容
buffer.skipBytes(buffer.readableBytes());
break;
}
}
}
整个方法由一个swith语句控制执行步骤,条件是currentState,currentState初始值为SKIP_CONTROL_CHARS。仔细看你会发现,很多case后面并没有break,意味着,正常情况下,每个case都会按顺序走一遍,如果case条件满足,则会执行case的逻辑,如果条件不满足,则继续匹配下一个case。
currentState可取值为(有删减):
SKIP_CONTROL_CHARS:初始化状态;READ_INITIAL:读取请求行;READ_HEADER:读取请求头;READ_FIXED_LENGTH_CONTENT:读取固定长度的请求body;BAD_MESSAGE:无效消息,不符合http协议的一个数据包。
第一步,找到http协议数据包的开始
case SKIP_CONTROL_CHARS: {
// 跳过控制符和空白符,从第一个非控制符和空白符开始,如果返回false,
// 则认为没有找到数据包的,直接结束解码
if (!skipControlCharacters(buffer)) {
return;
}
// 将状态标志为读取请求行,下一步就是解码请求行
currentState = State.READ_INITIAL;
}
SKIP_CONTROL_CHARS: 跳过控制符和空白符,从第一个非控制符、空白符的字符开始,如果当前接收到的整个buffer都没有一个非控制符、空白符的字符,则不做解析,并且buffer的读索引会被设置为写索引,也就是标志为当前buffer中的数据都读过了。
/**
* 从当前接收到的buffer中,找到一个http数据包的开始
*
* @param buffer
* @return
*/
private static boolean skipControlCharacters(ByteBuf buffer) {
boolean skiped = false;
final int wIdx = buffer.writerIndex();
int rIdx = buffer.readerIndex();
// 遍历buffer
while (wIdx > rIdx) {
int c = buffer.getUnsignedByte(rIdx++);
// 从第一个非IOS控制字符,且非space(空白符)字符开始,认为这是一个数据包的开始
// isISOControl:判断字符是否是控制字符,如换行、回车等,对应assii码的0x00~0x1f与0x7f~0x9f区间的字符
// isWhitespace:方法用于判断指定字符是否为空白字符,空白符包含:空格、tab 键、换行符。
// 空白符并不是只有空格符、tab 键和换行符这三种,
// 转义序列中就以下四种符号会被判定为 true 结果:
// 1、\\t(在文中该处插入一个 tab 键)
// 2、\\n(在文中该处换行)、
// 3、\\r(在文中该处插入回车)、
// 4、\\f(在文中该处插入换页符)
if (!Character.isISOControl(c) && !Character.isWhitespace(c)) {
// 回退一下读索引
rIdx--;
skiped = true;
break;
}
}
// 重置读索引为数据包的开始位置
buffer.readerIndex(rIdx);
return skiped;
}
如果正常,则会将currentState设置为READ_INITIAL,接着走case READ_INITIAL步骤,读取请求行。
第二步,读取请求行
case READ_INITIAL:
try {
// 从buffer中读取一行数据,遇到回车换行符为一行
// 如果读取不到,则结束
AppendableCharSequence line = lineParser.parse(buffer);
if (line == null) {
return;
}
// 按" "空格符号分割字符串
String[] initialLine = splitInitialLine(line);
if (initialLine.length < 3) {
// 无效请求行,忽略,重置状态标志,结束解析
currentState = State.SKIP_CONTROL_CHARS;
return;
}
// 请求行解析正确,创建消息
message = createMessage(initialLine);
// 将状态设置为开始读取请求头
currentState = State.READ_HEADER;
} catch (Exception e) {
out.add(invalidMessage(buffer, e));
return;
}
// 没有break,会接着继续解析
READ_INITIAL:从buffer中读取一行数据,遇到回车换行符为一行。根据空格" "符切割字符串为数组,判断请求行分割后的数组长度是否为3,不是就认为这不是一个http协议数据包的请求行,将状态重置为初始状态。如果是,则创建一个HttpMessage 对象,并将currentState设置为READ_HEADER,下一步读取解析请求头。
注意,解析过程中,从buffer中读取数据,会将buffer的readindex索引移动,所以读取过的消息内容将不会被再次读取。如果当前读取的一行数据不是一个http协议数据包的请求行,则下一次不会再读取到这一行,而是从下一行开始读取。
createMessage方法是子类HttpRequestDecoder实现的方法。
@Override
protected HttpMessage createMessage(String[] initialLine) throws Exception {
return new DefaultHttpRequest(
HttpVersion.valueOf(initialLine[2]),
HttpMethod.valueOf(initialLine[0]), initialLine[1], validateHeaders);
}
创建一个DefaultHttpRequest对象,DefaultHttpRequest的构造方法
public DefaultHttpRequest(HttpVersion httpVersion, HttpMethod method, String uri, boolean validateHeaders) {
}
第一个参数:http协议的版本信息;
第二个参数:请求方法,即GET、POST等;
第三个参数:uri,如/api/user/login。
我用Wireshark随便捉的一个http请求数据包:
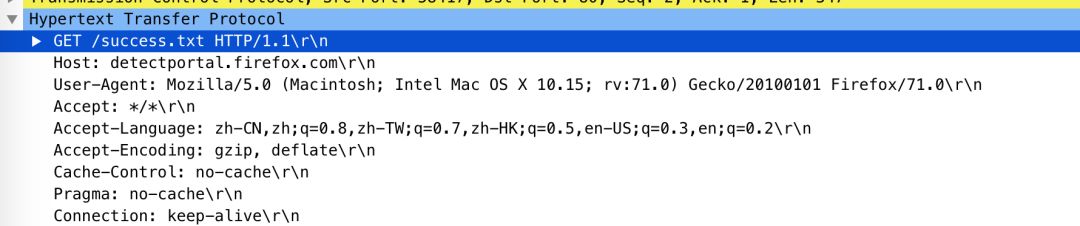
请求行为:GET /success.txt HTTP/1.1,按空格分割之后,字符串数组为
initialLine[0] = 'GET'
initialLine[1] = '/success.txt'
initialLine[2] = 'HTTP/1.1'
所以,在这个例子中,创建的DefaultHttpRequest对象,传递的httpVersion参数的值为HTTP/1.1,method为GET,uri为/success.txt。
第三步,读取请求头
case READ_HEADER:
try {
// 读取请求头
State nextState = readHeaders(buffer);
if (nextState == null) {
return;
}
currentState = nextState;
具体实现读取请求头的逻辑在readHeaders方法中完成。当readHeaders方法返回下一步的状态码为空,则说明读取请求头出错,结束解码。否则将currentState设置为readHeaders方法返回的状态码。以我们开发中常见的请求api接口为例,正常情况下readHeaders方法返回的将是READ_FIXED_LENGTH_CONTENT。
private State readHeaders(ByteBuf buffer) {
final HttpMessage message = this.message;
final HttpHeaders headers = message.headers();
// 从buffer中继续读取一行
AppendableCharSequence line = headerParser.parse(buffer);
if (line == null) {
return null;
}
// line的长度为0有两种情况:
// 1、当前buffer已经读取完了
// 2、遇到空行,即只有回车换行符的一行
if (line.length() > 0) {
// 循环读取解析请求头,直到遇到空行
do {
char firstChar = line.charAt(0);
// 非正常情况
if (name != null && (firstChar == ' ' || firstChar == '\\t')) {
//please do not make one line from below code
//as it breaks +XX:OptimizeStringConcat optimization
String trimmedLine = line.toString().trim();
String valueStr = String.valueOf(value);
value = valueStr + ' ' + trimmedLine;
}
// 第一次循环,name为null
else {
// 添加到请求头
if (name != null) {
headers.add(name, value);
}
// 分割一行字符,获取到name:value
splitHeader(line);
}
// 继续读取解析下一行
line = headerParser.parse(buffer);
if (line == null) {
return null;
}
} while (line.length() > 0);
}
// 读到最后一行空行,则结束读取解析,接着还要将空行的前一行name:value添加到请求头
if (name != null) {
headers.add(name, value);
}
// 重置name、value
name = null;
value = null;
State nextState;
if (isContentAlwaysEmpty(message)) {
HttpUtil.setTransferEncodingChunked(message, false);
nextState = State.SKIP_CONTROL_CHARS;
} else if (HttpUtil.isTransferEncodingChunked(message)) {
nextState = State.READ_CHUNK_SIZE;
} else if (contentLength() >= 0) {
// 从请求头中获取content-length,如果大于0,则将下一步解析状态设置为READ_FIXED_LENGTH_CONTENT
// 即读取固定长度的content.
nextState = State.READ_FIXED_LENGTH_CONTENT;
} else {
nextState = State.READ_VARIABLE_LENGTH_CONTENT;
}
return nextState;
}
简单理解,循环按顺序从buffer中读取一行字符串,不打算分析具体的读取过程,无非就是遇到\\r\\n回车换行符为一行。将读取的一行记录按:分割为name:value,并设置到当前创建的DefaultHttpRequest的请求头中。http协议规则请求头与请求body之间必须存在一个空行,只有\\r\\n的一行,因为请求头并没有固定的长度,所以需要用一个空行标志请求头的结束。
contentLength方法则是从已经解析出来的请求头中获取Content-Length参数,这个参数是标志请求body的长度的,如果请求头中没有这个参数,则根据RFC 7230, 3.3.3的约定,content-length的值为0。如果content-length大于0,则说明请求body有内容。比如我们调用接口时,传递的json字符串。解析完请求头,并且content-length大于0时,返回READ_FIXED_LENGTH_CONTENT,所以下一步就是解析请求body。
第四步,读取请求body
case READ_FIXED_LENGTH_CONTENT: {
// 读取固定长度的body
int readLimit = buffer.readableBytes();
......
if (readLimit == 0) {
return;
}
int toRead = Math.min(readLimit, maxChunkSize);
if (toRead > chunkSize) {
toRead = (int) chunkSize;
}
ByteBuf content = buffer.readRetainedSlice(toRead);
chunkSize -= toRead;
if (chunkSize == 0) {
// Read all content.
out.add(new DefaultLastHttpContent(content, validateHeaders));
resetNow();
} else {
out.add(new DefaultHttpContent(content));
}
return;
}
从buffer中读取指定长度的内容,在我们忽略Transfer-Encoding: chunked的情况下,chunkSize就是1,所以会创建一个DefaultLastHttpContent,标志着一个http协议的请求数据包解码完成。
这里并未看到解析请求body的过程,因为当前并不需要解析,只需要拿到一个完整的http协议请求数据包即可。因为只有应用程序需要知道body是什么。就用api接口来说,body是一个json字符串的时候,只有api服务知道将这个json解析成什么,也只有api服务会去用到这个json。但需要请求头标志body的类型,如Content-Type:application/json。
如果加入Transfer-Encoding: chunked,那么解析的步骤将会复杂很多,所以我选择将这部分内容去掉。网上似乎也有http协议的数据包编解码工具包,感兴趣可以去搜索一下。