![]()
 Java进阶高手 专栏收录该内容,点击查看专栏更多内容
Java进阶高手 专栏收录该内容,点击查看专栏更多内容原创 吴就业 494 0 2019-12-18
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/6cfeada4c752471ea783fd2791f65dad
作者:吴就业
链接:https://wujiuye.com/article/6cfeada4c752471ea783fd2791f65dad
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
本篇文章写于2019年12月18日,从公众号手工同步过来(博客搬家),本篇为原创文章。
已经有那么多作者写ThreadLocal的源码分析,我还是想写下这篇,换个思路去分析。
平时分析源码都是从ThreadLocal的get与set方法入口开始,这是我们分析源码的一个步骤一点也没错。不过我觉得,ThreadLocal更适合按看源码的步骤反方向分析,让未读过源码的朋友更易于理解。因此,我将从Thread的一个字段threadLocals开始分析。
创建一个线程都是通过new Thread创建的,使用线程池也不例外,但不代表Thread的字段就是线程安全的,它也是一个普通的对象,也是分配在堆中。通过start0这个native方法将其与一个系统线程绑定,仅此而已,它不代表Java虚拟机栈,只是一个继承Object的实例。
public class Thread{
public synchronized void start() {
start0();
}
private native void start0();
}
为何ThreadLocal只允许一个线程写入一个对象,同一个线程中调用同一个ThreadLocal的set方法多次写入记录,前面写入的数据会被后面的覆盖,而Thread却要用一个Map来存储?
public class ThreadLocal<T>{
public set(T value){
.......
createMap(t, value);
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
}
Thread的threadLocals字段初始化赋值是在ThreadLocal中完成的,当调用ThreadLocal的set方法写入数据时,如果当前线程的Thread实例的threadLocals字段为空,才开始赋值。ThreadLocalMap的构造方法要求传入一个Key-Value,而ThreadLocal在创建ThreadLocalMap时,传入的Key是this,说明ThreadLocalMap的key类型是ThreadLocal。因为整个项目中不可能只有一个ThreadLocal,每个ThreadLocal都可以给一个线程写入一个value,要区分不同ThreadLocal就需要Map来存储。
比如一个Spring项目,处理事务也是用的ThreadLocal,Dubbo的RpcContext也是用的ThreadLocal,处理一个请求通常都是在一个线程中去完成的,假设处理一个请求即用到Dubbo发起rpc调用,又用到事务注解操作数据库,那么至少就存在两个ThreadLocal 往一个线程Thread实例的threadLocals字段写数据。
ThreadLocalMap的key作用就是区分同一个线程Thread对象中不同ThreadLocal写入的数据,实现数据隔离。Thread与ThreadLocalMap、ThreadLocal三者的关系如下图所示。
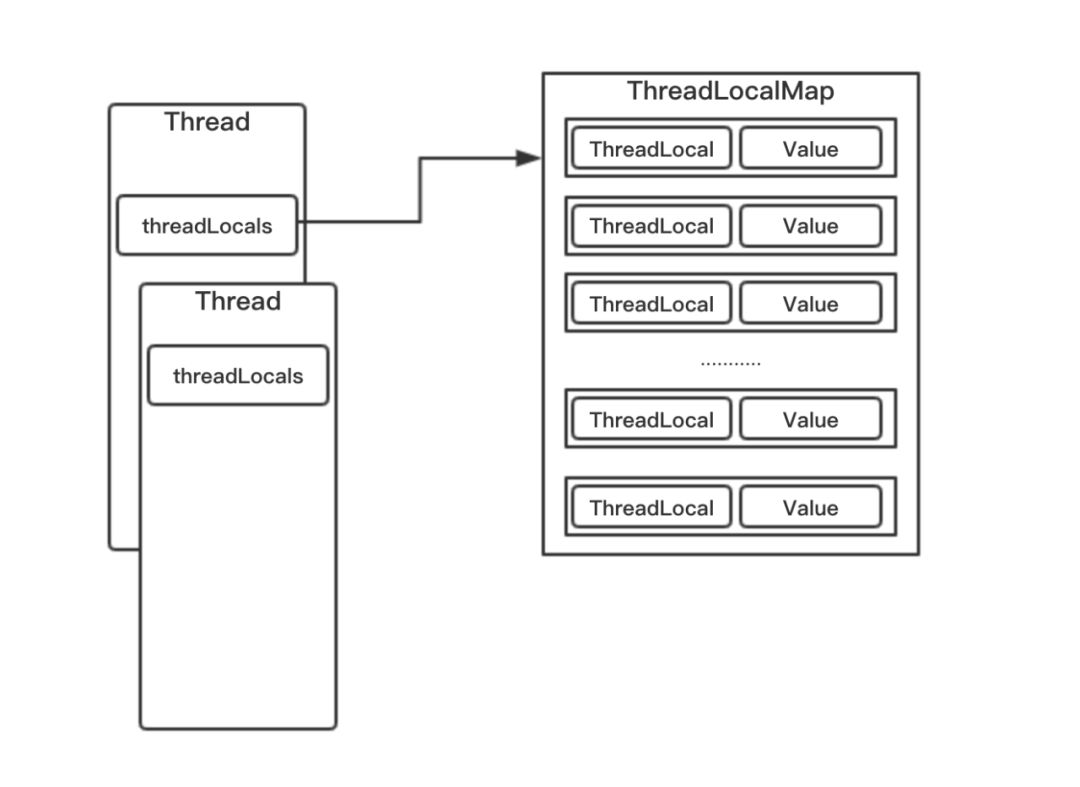
ThreadLocal中的ThreadLocalMap并非Java.util包下的HashMap,而是ThreadLocal定义的一个静态内部类。与HashMap的实现不同,ThreadLocalMap使用开放定址法解决Hash冲突,是一个简单的Map实现。
ThreadLocal是如何把数据存放到Thread实例的threadLocals字段中的呢。此时再看ThreadLocal的set方法。
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
set方法中,通过调用Thread.currentThread方法获取到当前线程的Thread实例,再调用getMap方法拿到Thread实例的threadLocals字段,类型为ThreadLocalMap。
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
getMap方法直接获取Thread对象的threadLocals字段,拿到当前线程的ThreadLocalMap,最后就是将当前ThreadLocal作为key,往Map里面写数据。读的过程也是一样的,先获取当线程的Thread实例,拿到Thread的threadLocals,将当前ThreadLocal作为key,就可以取到数据了。把源码分析的顺序反过来是不是更容易理解呢?
为什么用Thread对象的threadLocals变量存储数据就能实现线程安全?其实并非线程安全,而是线程隔离,每个线程都只能访问自己Thread,threadLocals被声明为包内可访问,阻止了外部获取threadLocal,且ThreadLocalMap是ThreadLocal的内部类,也是包内可访问。当只有一个线程能访问这个变量时,这个变量就是线程安全的。而threadLocals只有Thread自身能访问,也就无需控制线程安全。
我们可以使用反射打破ThreadLocal的线程安全,代码如下。
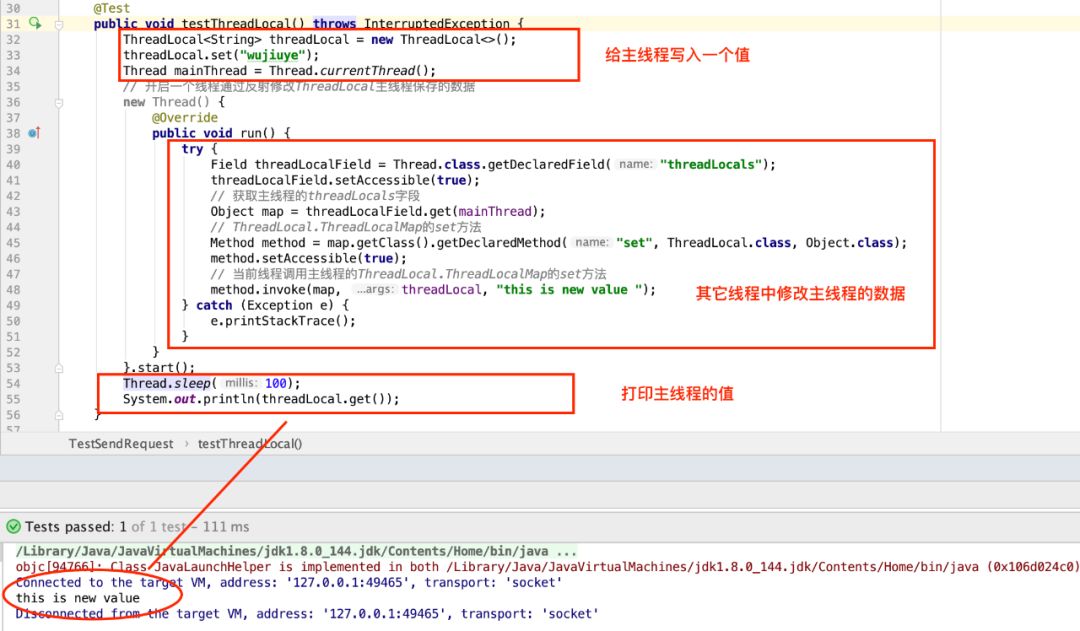
例子中,在主线程创建ThreadLocal,并调用set方法写入一个字符串,那么这个字符串便是存放在主线程的Thread实例的threadLocals中的,key就是该ThreadLocal。之后开启一个线程,通过反射获取主线程的Thread实例的threadLocals,但由于这个ThreadLocalMap是包私有的,只能继续通过反射调用set方法,key还是同一个ThreadLocal,值改为一个新的字符串。主线程等待子线程结束后再调用这个ThreadLocal的get。
结果显示,主线程从这个ThreadLocal中拿到的就已经不再是之前的字符串了。如果多个线程去修改,依然存在线程安全问题。
ThreadLocal的内存泄漏问题又是如何理解?
1、Thread的threadLocals字段的生命周期与Thread相同,而一般为能复用Thread,都会用线程池管理,所以Thread的生命周期可能就是整个应用的生命周期。
2、Thread的threadLocals字段的类型为ThreadLocalMap,该Map的Key类型是ThreadLocal,是个弱引用。
// key通过Entry::get获取持有的ThreadLocal引用
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
与其说ThreadLocalMap是一个Map,不如说是一个数组。组数元素的类型为ThreadLocalMap.Entry,在插入元素时,根据元素持有的弱引用对象计算出要插入的数组下标。
如果在一个类中声明一个ThreadLocal类型的字段,假如这个类的实例是非单例的,在web应用中每处理一个请求都会创建一个实例,那么该实例在处理完请求之后会被回收,但是他的字段ThreadLocal却没有被回收。因为它还被Thread的threadLocals引用。
Entry继承WeakReference,持有ThreadLocal的弱引用,当ThreadLocal被回收时,Entry持有的ThreadLocal也会被回收,但是Entry没有被回收啊。为了解决这个问题,ThreadLocalMap每次扩容时,都会扫描清除掉一些持有ThreadLocal已经被回收的Entry,为了高效,并不会扫描整个数组,只扫描log(n)个下标的元素。这也会导致写入数度变慢。
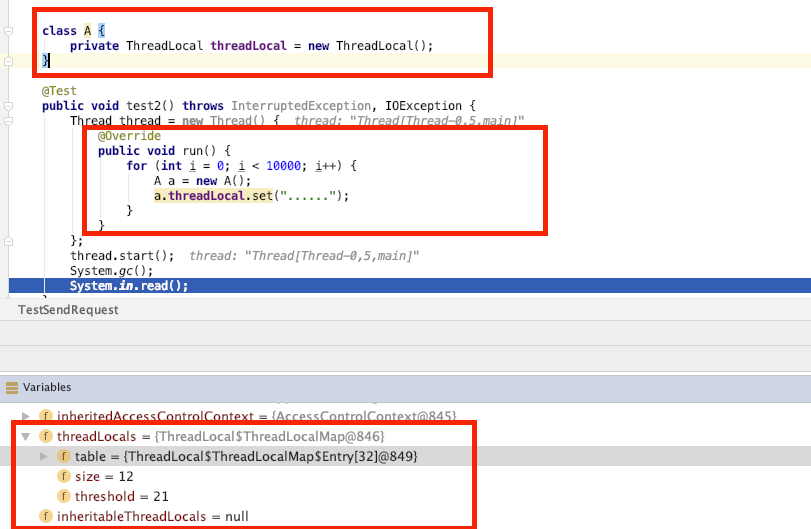
解决内存泄漏最好的办法就是在任务结束之前调用remove方法移除,比如在接收请求时加个try -finally移除。将ThreadLocal设置为静态变量。Spring应用中,如果bean是单例的,可以不用声明为静态变量。
关于ThreadLocalMap的set方法与扩容时扫描清除Entry的逻辑,可以去看下源码的实现。ThreadLocalMap只用一个数组存储Entry,只要将对应的数组下标赋值为null,就不会有别的地方引用到该Entry,下次垃圾回收时自然会被回收。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
容器化部署就是一次配置到处使用,例如将安装nginx配置nginx这一系列工作制作成一个镜像,在服务器上通过docker拉取镜像并启动容器即可完成nginx的部署。
Dubbo框架的传输层默认使用dubbo协议,这也是一种RPC远程通信协议。学习Dubbo,我们有必要了解dubbo协议长什么样,最好的办法就是从源码中寻找答案。
今天我们来分析下`netty`是如何解析`http`协议数据包的。重点是分析`HttpObjectDecoder`类的`decode`方法的源码,`http`协议数据包的解码操作都是在该方法中完成的。
在前面分析Dubbo注册中心层源码的文章中,我们知道,服务的导出与引入由RegistryProtocol调度完成。对于服务提供者,服务是先导出再注册到注册中心;对于服务消费者,先将自己注册到注册中心,再订阅事件,由RegistryDirectory将所有服务提供者转为Invoker。
本篇继续分析服务提供者发起一个远程RPC调用的全过程,也是跳过信息交换层和传输层,但发起请求的逻辑会复杂些,包括负载均衡和失败重试的过程,以及当消费端配置与每个服务提供端保持多个长连接时的处理逻辑。
由于我在实际项目中并未使用Redis作为服务注册中心,所以一直没有关注这个话题。那么,使用Redis作为服务注册中心有哪些缺点,希望本篇文章能给你答案。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。