![]()
 Dubbo实战经验分享与源码分析 专栏收录该内容,点击查看专栏更多内容
Dubbo实战经验分享与源码分析 专栏收录该内容,点击查看专栏更多内容原创 吴就业 517 0 2019-12-30
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/198fb54b0b494498bc8034e71fbdf93c
作者:吴就业
链接:https://wujiuye.com/article/198fb54b0b494498bc8034e71fbdf93c
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
本篇文章写于2019年12月30日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
RPC协议即远程进程调用协议,自己的话理解就是,让两个进程之间的调用像同进程内调用一个函数那么简单。
Dubbo框架的传输层默认使用dubbo协议,这也是一种RPC远程通信协议。学习Dubbo,我们有必要了解dubbo协议长什么样,最好的办法就是从源码中寻找答案。
本篇将通过源码分析了解dubbo协议,以及了解dubbo协议数据包的解码过程。
dubbo协议数据包无论是请求数据包还是响应数据包,大体分为两部分,一部分是头部,一部分是body。头部的长度为16字节,这是固定的。而头部又可分为5个小部分:魔数 + 序列化标志和消息类型 + 状态码 + 序列化后的消息body的长度 + 请求id。
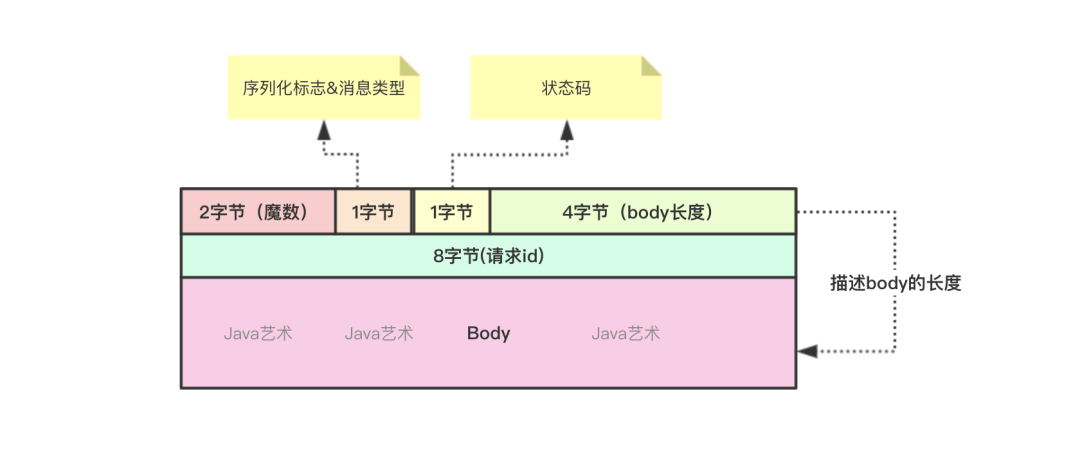
魔数是固定的,存储的是0xdabb,标志这是一个dubbo协议的请求或响应数据包;序列化标志就是序列化协议的id,每种序列化协议都对应一个id,比如hession2序列化协议的id是2;消息类型标志这是一个请求消息还是一个响应消息,以及是否事件类型的消息;请求id用于标识一次请求,客户端需要根据这个请求id识别一个响应是哪个请求的回复。
整个数据包非常的简单,而唯一算得上复杂一点的,就是第3个字节码。使用高3位标志一个消息类型,如第8位为0表示这是一个响应数据包,第8位为1表示这是一个请求数据包。低5位表示使用的序列化协议。
在发送消息时,先计算出序列化协议,比如hession2序列化协议的id为2,将序列化协议id‘或’上FLAG_REQUEST得到10000010;服务端只需要将该byte‘与’上10000000,结果为1则拿到消息类型为FLAG_REQUEST说明这是一个请求数据包,将byte‘与’上SERIALIZATION_MASK就能得到序列化协议的id。
protected static final byte FLAG_REQUEST = (byte) 0x80;//10000000
protected static final byte FLAG_TWOWAY = (byte) 0x40; //01000000
protected static final byte FLAG_EVENT = (byte) 0x20; //00100000
protected static final int SERIALIZATION_MASK = 0x1f; //00011111
可以看出,dubbo在努力的减少数据包的大小。与http协议的数据包相比,是不是感觉数据包小很多?当然,只是这样对比是没有意义的,假设一个接口调用,不需要任何参数,dubbo协议要描述请求哪个接口的哪个方法需要填写在body,http协议可以只在请求行上修改uri,那么此时,哪种协议的数据包更大,就需要通过抓包分析了。我的直觉告诉我,还是会比http协议的数据包小,因为http协议的请求头会比描述一个接口的某个方法的字符串更长。
dubbo协议的数据包解析过程会比http协议的请求效率高很多,因为dubbo协议不需要一行行探测是否是一个数据包的开始,只要找到魔术,就找到了一个数据包,按顺序读取16字节的数据就是请求头,根据请求头中的body长度就能拿到body,根据序列化算法就能解析body。
源码在dubbo-rpc模块的子模块dubbo-rpc-dubbo,主要分析的类:DubboCodec、ExchangeCodec。
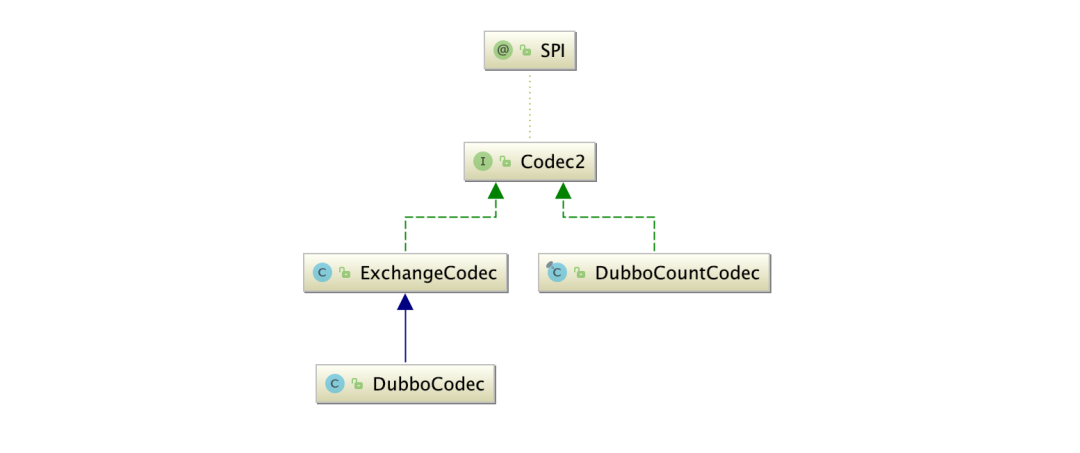
ExchangeCodec:负责编解码数据包DubboCodec:负责编解码body解码数据包入口在ExchangeCodec类的decode方法
@Override
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
int readable = buffer.readableBytes();
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];
buffer.readBytes(header);
return decode(channel, buffer, readable, header);
}
* 数据包头部长度:16byte
* 2byte魔数:0xdabb
* 1字节序列化标志|消息类型
* 1字节状态码
* 4byte数据包body长度
* 8byte请求id
* 请求body
*
* @param channel
* @param buffer
* @param readable
* @param header
* @return
* @throws IOException
*/
@Override
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// check magic number.检查魔数是否是数据包的开始
if (readable > 0 && header[0] != MAGIC_HIGH || readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
// 读取请求头
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, buffer, readable, header);
}
// check length. 检查读取到的字节长度是否大于请求头长度16字节码,如果不是,则等待接收到更多的字节再解析
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// get data length. 从请求头中获取数据包长度
int len = Bytes.bytes2int(header, 12);
checkPayload(channel, len);
// 如果当前读取的字节长度少于body长度+请求头长度,则继续等待接收到一个完整的数据包
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// limit input stream.
// 根据长度截取一个完整的数据包
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
return decodeBody(channel, is, header);
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is);
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
}
decode方法首先从buffer中读取固定长度的请求头,检查请求头的前两个字节是否是0xdabb,如果不是,则循环探测找出0xdabb,这是解决粘包问题,如前一个数据包解析出错遗留下的一部分字节数据,需要去掉这部分脏数据。
接着检查当前buffer的长度是否少于请求头的长度,少于则数据包不完整,需要等待接收更多的字节数据再解析。否则从请求头中获取body长度,如果body长度加上请求头长度大于当前buffer的长度,则数据包不完整,继续等待接收更多的字节数据再解析。
如果数据包检验通过,则根据body长度从buffer中读取body,调用decodeBody继续解码数据包。子类DubboCodec覆写了decodeBody方法,因此我们需要分析DubboCodec的decodeBody方法。
@Override
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
// 获取消息类型与序列化协议id
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
// 获取请求id
long id = Bytes.bytes2long(header, 4);
if ((flag & FLAG_REQUEST) == 0) {
// 解码响应数据包(客户端)
Response res = new Response(id);
if ((flag & FLAG_EVENT) != 0) {
res.setEvent(true);
}
// 获取响应状态码
byte status = header[3];
res.setStatus(status);
try {
if (status == Response.OK) {
Object data;
// 心跳包
if (res.isHeartbeat()) {
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
data = decodeHeartbeatData(channel, in);
}
// 事件
else if (res.isEvent()) {
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
data = decodeEventData(channel, in);
}
// 正常请求响应
else {
DecodeableRpcResult result;
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
result.decode();
} else {
result = new DecodeableRpcResult(channel, res,
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
}
res.setResult(data);
} else {
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
res.setErrorMessage(in.readUTF());
}
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode response failed: " + t.getMessage(), t);
}
res.setStatus(Response.CLIENT_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
return res;
} else {
// 解码请求数据包
Request req = new Request(id);
req.setVersion(Version.getProtocolVersion());
req.setTwoWay((flag & FLAG_TWOWAY) != 0);
if ((flag & FLAG_EVENT) != 0) {
req.setEvent(true);
}
try {
Object data;
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
// 心跳包
if (req.isHeartbeat()) {
data = decodeHeartbeatData(channel, in);
}
// 事件
else if (req.isEvent()) {
data = decodeEventData(channel, in);
}
// 正常请求
else {
DecodeableRpcInvocation inv;
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
inv = new DecodeableRpcInvocation(channel, req, is, proto);
inv.decode();
} else {
inv = new DecodeableRpcInvocation(channel, req,
new UnsafeByteArrayInputStream(readMessageData(is)), proto);
}
data = inv;
}
req.setData(data);
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode request failed: " + t.getMessage(), t);
}
// bad request
req.setBroken(true);
req.setData(t);
}
return req;
}
}
decodeBody方法虽然很长,但很简单。从请求头中获取到消息类型与序列化协议id、请求id。根据消息类型判断这是一个请求数据包还是响应数据包。如果flag & FLAG_REQUEST = FLAG_REQUEST,表示这是一个请求数据包,否则就是一个响应数据包。
响应数据包:创建Response对象,设置响应是否事件类型,如果flag & FLAG_EVENT = FLAG_EVENT,则说明此响应还是一个事件。响应数据包要求有状态码,请求头的第四个字节。根据响应状态码解码响应的data,响应数据包也分三种类型,分别是心跳包、事件响应、正常的请求响应。这里不讨论事件类型与心跳包。
请求数据包:与解码响应数据包一样,根据请求id创建一个Request对象,根据请求头的事件类型标志设置是否event,最大的区别是请求数据包不使用请求头的第四个字节。根据从请求头获取的序列化协议id调用CodecSupport.deserialize方法解码body。
public static ObjectInput deserialize(URL url, InputStream is, byte proto) throws IOException {
// 根据序列化标志获取序列化器
Serialization s = getSerialization(url, proto);
return s.deserialize(url, is);
}
public static Serialization getSerialization(URL url, Byte id) throws IOException {
Serialization serialization = getSerializationById(id);
// 从url获取序列器名称,默认为hession2
String serializationName = url.getParameter(Constants.SERIALIZATION_KEY, Constants.DEFAULT_REMOTING_SERIALIZATION);
// 为了安全起见,检查从网络传递的“序列化id”是否与此端的id匹配(仅对JDK序列化生效)
if (serialization == null
|| ((id == JAVA_SERIALIZATION_ID || id == NATIVE_JAVA_SERIALIZATION_ID || id == COMPACTED_JAVA_SERIALIZATION_ID)
&& !(serializationName.equals(ID_SERIALIZATIONNAME_MAP.get(id))))) {
throw new IOException("Unexpected serialization id:" + id + " received from network, please check if the peer send the right id.");
}
return serialization;
}
根据序列化协议id获取Serialization,调用Serialization的deserialize方法完成反序列化操作,序列化和反序列是我们最熟悉不过的,常用的api接口开发使用的就是json协议的序列化与反序列,而dubbo提供了很多种序列化协议的支持,如json、hession2。dubbo会为每种序列化协议分配一个id,使用map做映射,通过id拿到Serialization序列化器。
/**
* id-序列化器 映射
*/
private static Map<Byte, Serialization> ID_SERIALIZATION_MAP = new HashMap<Byte, Serialization>();
dubbo协议的数据包解码流程相比http协议的数据包解码流程简单许多,编码过程没有分析完整,但其实就是解码的反向操作而已。看完http协议数据包的解码过程与dubbo协议数据包的解码过程,也了解到http协议的数据包和dubbo协议的数据包长啥样了,你觉得哪种协议的解码效率更高、对内存的使用消耗更少?
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
线上某服务一直运行很稳定,最近突然就`cpu`百分百,`rpc`远程调用全部失败,并走了`mock`逻辑。重启后,一个小时后问题又重现。于是`dump`线程栈信息,但不仔细看也看不出什么问题。于是就有了一番排查历程。
最近看书看到关于`volitale`关键字与`jmm`内存模型的介绍,这个知识点似乎看了好多次,背都能背下来了。但理论性的东西真的很容易忘记,看不到摸不着。于是乎,我上网搜索看底层机器指令的实现,发现不少文章说可以看到`java`编译后的汇编代码,于是了解到`jitwatch`这个工具,从名字上也能看出`jit`编译器监视的意思。
容器化部署就是一次配置到处使用,例如将安装nginx配置nginx这一系列工作制作成一个镜像,在服务器上通过docker拉取镜像并启动容器即可完成nginx的部署。
今天我们来分析下`netty`是如何解析`http`协议数据包的。重点是分析`HttpObjectDecoder`类的`decode`方法的源码,`http`协议数据包的解码操作都是在该方法中完成的。
在前面分析Dubbo注册中心层源码的文章中,我们知道,服务的导出与引入由RegistryProtocol调度完成。对于服务提供者,服务是先导出再注册到注册中心;对于服务消费者,先将自己注册到注册中心,再订阅事件,由RegistryDirectory将所有服务提供者转为Invoker。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。