![]()
 Java进阶高手 专栏收录该内容,点击查看专栏更多内容
Java进阶高手 专栏收录该内容,点击查看专栏更多内容原创 吴就业 472 0 2018-12-13
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/6c185b0716324669832f7d84f1c1b4af
作者:吴就业
链接:https://wujiuye.com/article/6c185b0716324669832f7d84f1c1b4af
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
看懂Java字节码首先得要了解栈桢和方法表,这两个知识点是比较重要的。另外了解这两个知识点还有助于指导Java性能调优工作。
java文件编译之后会生成class二进制文件,每个class文件都会存储一些字符串常量,除了我们在方法中,比如String s=“hello”中hello被存储在常量池之外,如类名、方法名、引用的其它类的类名和方法名等也都是存储在常量池中的,严格来说是常量 表,因为每一个常量都是一个结构体,最常见的就是CONSTANT_UTF8_info了,这个结构体就是存储utf8编码的字节串常量的。
这些不是本文的重点,重点是方法表,下面是我根据自己的理解总结画出来的图,依然那么丑,这是我的风格。
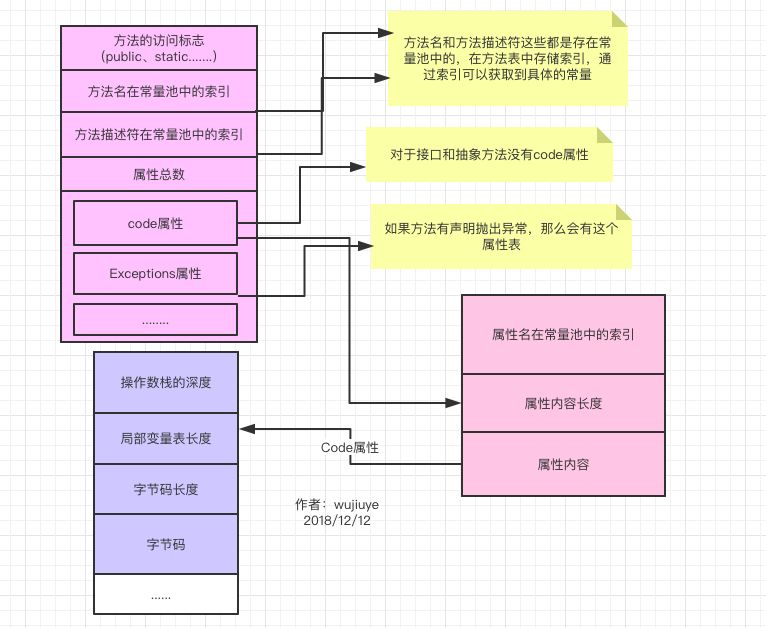
看不清楚可以点击图片放大看。每个方法表存储的内容无非就是方法的访问标志符(如public、private等)、方法名(只是存放一个索引)、方法描述符(如:”(Ljava/lang/String;)V”)、属性总数和属性。属性可以有多个,也可以没有。这里我只给出一个最常见的Code属性,因为这个属性存储了这个方法要执行的代码。对于接口中的方法,其编译后生成的方法表是没有Code属性的,因为接口中声明的方法不允许有方法体。
每个属性表的大小和存储的内容不一样,但是属性头都是一样的,即都会存储属性名索引、属性内容长度、属性内容(这是个结构体),所以每个属性表不同的内容就是属性内容。对于Code属性,其属性内容存储的是操作数栈的深度、局部变量表的长度、字节码长度、字节码等。所以这里理解操作数栈和局部变量表也很重要。首先是献上我的丑图。
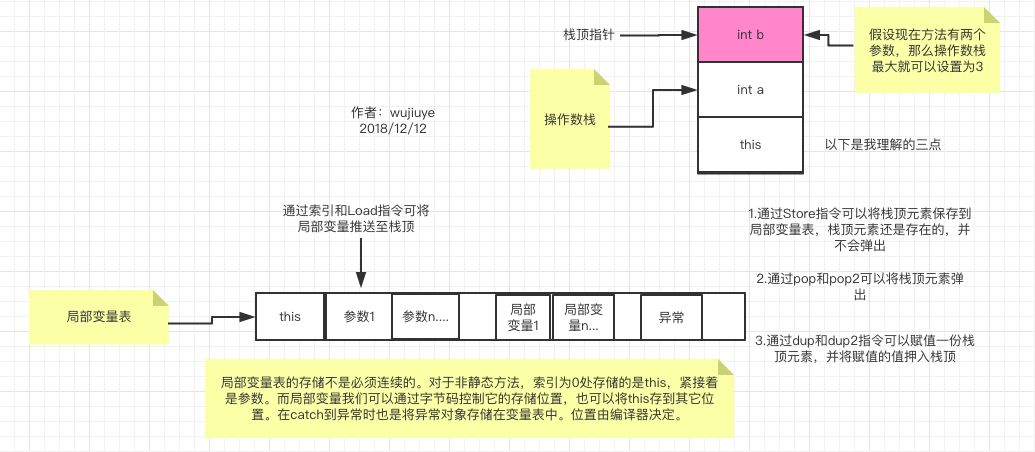
看不清楚点击图片放大看哈。局部变量表的长度和操作数栈的深度是在编译器编译的时候确定的,然后保存在class文件中对应的方法表的Code属性中的。那么这两个东东的作用是什么呢?以及编译器是如何帮我们确定大小的呢?首先,我们需要了解栈桢,然后再回过头来解决这两个问题。
在了解栈桢之前,先对java虚拟机有个总体的认知,因为栈桢是java虚拟机栈的内容,所以也得先知道java虚拟机栈是什么鬼。下面请允许我根据我的个人理解秀张丑图,站稳,没事,翻不了车。
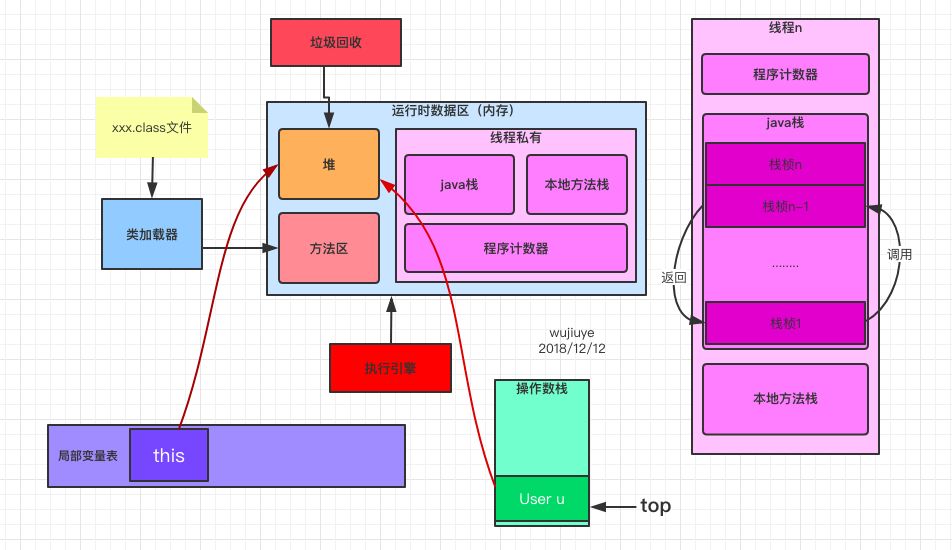
画这个图我的本意只是为了引出“栈桢”,因为本篇重点不是介绍java虚拟机全部内容。从图中可以看出,与栈桢相关的是java虚拟机栈,即图中java栈,这是线程私有的,生命周期和线程一致,描述的是Java方法执行的内存模型,即每个方法在执行时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口(有些博客写的是返回地址)等信息。每一个方法从调用直至执行结束,就对应着一个栈帧从虚拟机栈(图中的java栈)中入栈到出栈的过程。“栈中有栈”。
也顺带介绍下程序计数器所扮演的角色。简单的来说吧,我们使用javap -c指令打印出来的字节码会带有“行号”,从0开始,而程序计数器就是保存下一条要执行的指令的“行号”,保存的是当前栈桢(方法)的行号。当一个栈桢返回时,需要将程序计数器恢复到上一个栈桢执行到的下一条指令的“行号”。
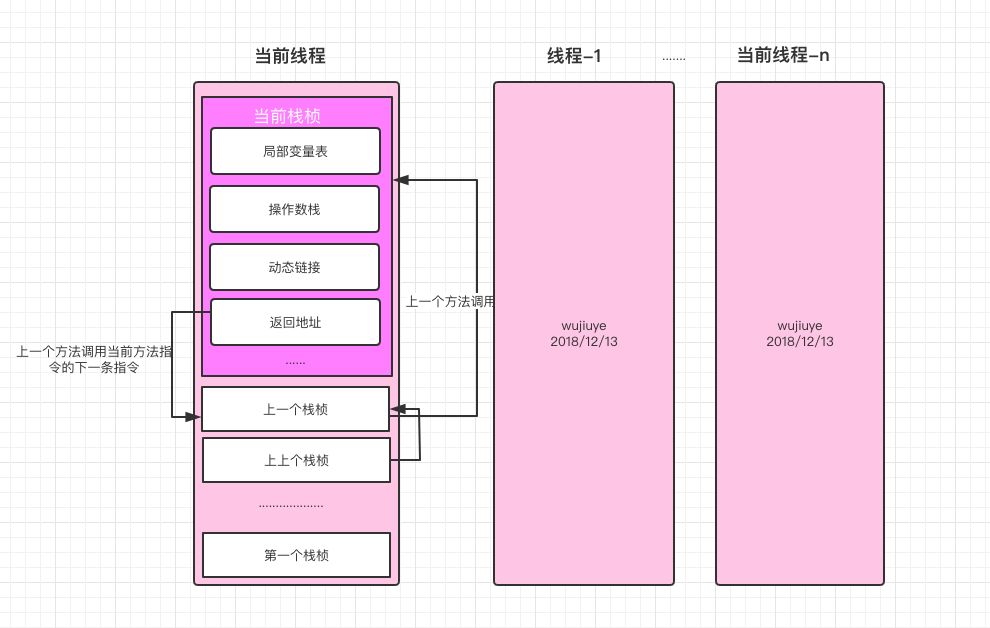
光听理论肯定很难理解,所以我要配上我的丑图来说明。先跟我念一遍理论。java虚拟机栈是线程私有的(每个线程都有自己的方法执行栈,没毛病),它描述的是java方法执行的内存模型(JMM?不扯这个)。每个方法在开始执行之前会先创建一个栈桢,用于存储局部变量表、操作数栈、动态链接、方法返回地址等信息。前面两个“局部变量表”、“操作数栈”好理解吧?这不是刚说完嘛。至于动态链接我这里就不说了,而方法返回地址也很好理解,我换一段说吧。
而方法地址简单点说,用80386汇编来理解就是记录上一个方法跳转到当前方法的那条指令的下一条指令程序计数器的值PC,而栈桢也是一样要保护好上一个方法执行到的位置的,当当前方法执行完成返回时就能接着上个方法的下条指令继续执行了。但是这里并不只是保存一个程序计数器值那么简单,上一个方法调用当前方法之前为了调用当前方法执行完成之后能够继续执行,那么肯定是要对上一个方法的现场进行保护的,就是保存上一个方法当前操作数栈内容、本地变量表存储的当前内容,当当前方法返回时,需要将这些内容恢复,同时如果方法有返回值,也会将返回值放入到上一个方法(调用它的那个方法)的操作数栈的栈顶。对于这里只是我的个人理解,不能说全对,但也八九不离十吧。
一个线程中的方法调用链可能会很长,即有很多的栈桢。对于一个当前活动的线程中,只有位于线程栈顶的栈桢才是有效的(通俗点就是当前执行的方法嘛),称为当前栈桢。(为了简单我就省去java栈中的程序计数器等内容了)
图片看不清楚点击放大看,重要事情说三遍。这里栈桢又出现了这两个词“操作数栈”、“局部变量表”,但是这里才是真正的存在操作数栈和局部变量表,前面class文件结构中方法表的Code属性只不过是存储了对这两个东东的描述,描述要执行该方法时,栈桢中要给操作数栈分配多少槽位(slot),要给局部变量表(这是一个数组)分配多长,这些都是影响栈桢大小的因素。现在可以来解答前面的两个问题了。
局部变量表是一组变量的存储空间,用于存储方法参数和方法内部定义的局部变量。这句话不能理解吧?没关系,我有丑图。
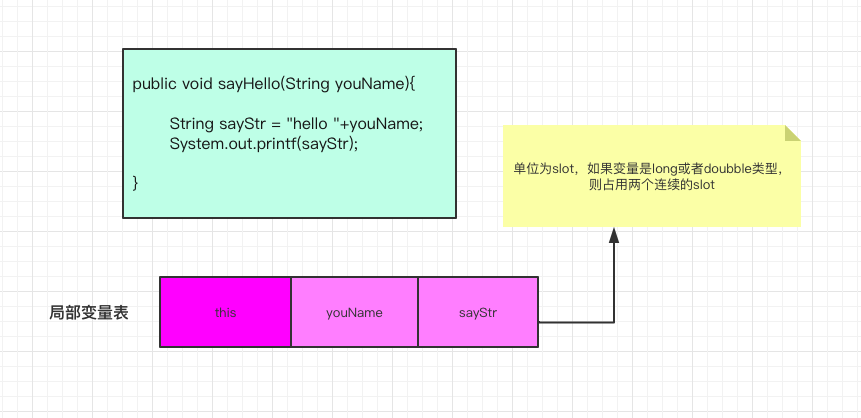
对于图中的sayHello方法,经过编译器编译之后会为我们设置max_locals的值为3,即局部变量表的长度为3,单位是slot。为什么是3?首先sayHello方法不是静态方法,所以我们在方法体内可以使用this,那么肯定就需要存储this了,所以局部变量表下标0处存储的就是this。接着编译器发现这个方法有一个参数,叫youName,是一个引用类型,也占一个slot,那么局部变量表下标为1处就是存储这个参数的值。然后方法体内定义了一个局部变量,叫sayStr,也是引用类型,那么编译器就指定了在运行过程中,将它存储在局部变量表下标为2的位置。
通过这个丑图的分析,你现在应该能回答前面的问题了吧?接着我再跟大家聊聊相关的字节码指令,因为前面我也给自己埋过坑,还在一篇文章最后写过一节“欠各位的aload_x的解释”的内容。现在我再来填一下这个坑。
关于load的指令有很多啊,对于数组的我就不说了,实在是太多了。就iload、lload、fload、dload、aload这几个就已经很多了,因为i、l、f、dload还有衍生版呢。
| # | 指令 | 说明 |
|---|---|---|
| 1 | iload | 将局部变量表中指定的一个int型变量推送到操作数栈顶 |
| 2 | lload | 将局部变量表中指定的一个long型变量推送到操作数栈顶 |
| 3 | fload | 将局部变量表中指定的一个float型变量推送到操作数栈顶 |
| 4 | dload | 将局部变量表中指定的一个double型变量推送到操作数栈顶 |
| 5 | aload | 将局部变量表中指定的一个引用型变量推送到操作数栈顶 |
其中iload是对int类型变量进行操作的,指定下标从局部变量表中将变量的值推送至栈顶,当下标少于3时,可以使用以下几条指令代替:iload_0将局部变量表中下标为0的int值推送至操作数栈顶,iload_1将局部变量表中下标为1的int值推送至操作数栈顶,iload_2将局部变量表中下标为2的int值推送至操作数栈顶,iload_3将局部变量表中下标为3的int值推送至操作数栈顶。当下标超过3的时候就需要使用iload了,我感觉好多余啊,为什么不直接给一条iload指令就行了呢,这可能是有其它方面的考虑吧,并竟存在就有它的理由。其它的lload_x、fload_x、dload_x也是一样的,我就不多说了。
对应的,有load就有store,即有加载就有存储。
| # | 指令 | 说明 |
|---|---|---|
| 1 | istore | 将操作数栈顶int型元素存储到局部变量表中指定的位置 |
| 2 | lstore | 将操作数栈顶long型元素存储到局部变量表中指定的位置 |
| 3 | fstore | 将操作数栈顶float型元素存储到局部变量表中指定的位置 |
| 4 | dstore | 将操作数栈顶double型元素存储到局部变量表中指定的位置 |
| 5 | astore | 将操作数栈顶一个引用型元素存储到局部变量表中指定的位置 |
其中istore是对int类型变量进行操作的,将操作数栈顶int类型值存储到局部变量表中指定的位置(注意这些指令是对当前栈顶元素操作),当指定存储到局部变量表的下标少于3时,可以使用以下几条指令代替:istore_0将当前栈顶int值存储到局部变量表中下标为0的位置,istore_1将当前栈顶int值存储到局部变量表中下标为0的位置,istore_2将当前栈顶int值存储到局部变量表中下标为0的位置,istore_3将当前栈顶int值存储到局部变量表中下标为0的位置。当下标超过3的时候就需要使用istore了。其它的lload_x、fload_x、dload_x也是一样的,我就不多说了。注意的是,store指令也会有出栈操作,就是将栈顶元素弹出,再存储到局部变量表的,这个你可以自己去验证,写一个加法运行方法,执行多个数相加,然后javap看max_stacks分配值是多大,再看字节码你就明白了。
如果是操作int、long、double、float类型的常量,那么会有相应的指令,比如int类型的:iconst_0将int型的0推送至栈顶,iconst_1将int型的1推送至栈顶,iconst_2将int型的2推送至栈顶,iconst_3将int型的3推送至栈顶,当大于3时就需要使用bipush指令来操作了(-128~127)。
操作数栈是一个后入先出的栈结构。栈我们都学过吧,记得以前上数据结构与算法的时候老师就让我们自己写过栈,当时我就用泛型写过一个通用的栈。栈的大小一般都是固定的,特殊使用情况除外。同样操作数栈是存在于栈桢中的,class文件结构的方法表中Code属性的max_stacks只是用来描述执行这个方法时应该为这个操作数栈分配多大的槽位。一般类型都是1一个slot大小,long和double占用连续的两个slot,在hotspot虚拟机中一个slot为32位大小,即4个byte。
当一个方法刚开始执行时操作数栈是空的,在方法执行过程中会有各种字节码指令向操作数栈中写入和提取内容,无非就是前面讲的load和store指令,当然还有dup指令和pop指令。当调用一个方法如果有返回结果时,调用结束后此时栈顶就是存储返回结果。
public int add(int a,int b){
int s = 100;
return a+s+b;
}
上面这个方法你觉得编译器会为我们指定多大的操作数栈?我来分配的话我就给2,知道为什么是2吗,来分析代码。首先执行第一行代码的时候,将int型常量100存储到局部变量表中,这时候没有用到操作数栈,操作数栈还是空的;接着执行第二行代码的时候,是将a入栈,然后将s入栈,刚好栈大小可以存放这两个变量,然后将这两个变量的值累加,将结果存入栈顶,此时操作数栈就只有a+s后的结果,因为是将a和s出栈后再加的。最后将b入栈,然后累加放回栈顶。所以整个方法执行下来,栈大小为2就够用了。来看下这个方法编译后的字节码就知道对不对了。
public int add(int, int);
descriptor: (II)I
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=3
0: bipush 100
2: istore_3
3: iload_1
4: iload_3
5: iadd
6: iload_2
7: iadd
8: ireturn
没有错吧,stack=2。如果还不明白,那我再给你讲讲这个iadd指令。首先iadd指令需要两个参数,所以前面有两条iload指令,第一条就是将a的值推送至栈顶,第二条就是将s的值推送至栈顶,然后才执行iadd。iadd是将栈顶两个元素执行相加并将结果压入栈顶,你看不到栈顶的两个元素出栈的过程是因为iadd执行已经帮做这个事情了,这不是汇编一条指令只做一件事情,所以执行完成之前栈顶已经是空的了,然后执行完后再将结果推送到栈顶,此时栈顶就只有一个元素了,最后再执行一次iadd的时候只需要将b推送至栈顶就可以了,所以也就为什么stack只需要2了。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
本篇介绍了笔者在一个业务场景下,通过各种优化手动都无法降低查询耗时的情况下,选择将表拆分多个,并使用Sharding-JDBC实现分表的查询,并介绍如何在已经实现了多数据源的项目中支持Sharding-JDBC数据源。
我使用浏览器的开发者功能,找到api,确实服务器返回给浏览器的结果是空数据。然后我顺藤摸瓜找到了这个api的代码,结果发现又是使用的内存缓存。本篇介绍如何借助JHat的强大功能查看内存缓存是否是空的。
ConcurrentHashMap 在1.7中 实现线程安全是通过锁住Segment对象的。而在1.8 中则是针对首个节点(table[hash(key)]取得的链接或红黑树的首个节点)进行加锁操作。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。