![]()
分表并不是为了装逼,而是业务发展到一定程序后,由于每天产生大量数据,导致单表增加和查询都很慢。为解决单表数据量过大导致的插入和查询慢而需要进行分表处理。
本次并未涉及到分库,只是简单的水平分表。目前数据量比较大的是一个统计报表(其实就是收益报表),当前数据量为四千三百多万。前段时间还是每天五万条记录的增长速度,现在是每天以十几万的数据量在增长。还有一个表的增长速度是它的几倍,就是存储统计报表详情信息的表。当然还有其它的待拆分的表,因为其它的表如果要拆分对项目的改动会很大,所以本次分表主要还是先拿报表试水。
我的分表思路是按日期分表,以月为单位对表进行拆分。以每天十五万的增速来算,一个月的数据量大约为四百五十万。刚好是mysql的性能瓶颈。这是统计报表的分表方案。
对于报表详情这张表,由于其是以外键与报表记录进行多对一关联,当然,这个外键是对程序而言,而不是在数据库表中创建的外键。我选择使用雪花算法计算报表的id,不再使用数据库的自增id,报表详情根据报表的id进行分表。拿到报表id后,利用雪花算法提取到时间戳部分,再根据时间戳转化成日期,所以报表详情也是使用日期分表,以月为单位。
雪花算法
雪花算法Snowflake,其实很简单,就是由时间戳、工作进程id、序列号所组成。生成的id长度为64位,也就是8字节,刚好是java一个long类型变量的长度。看下shardingsphere官方介绍给出的图。
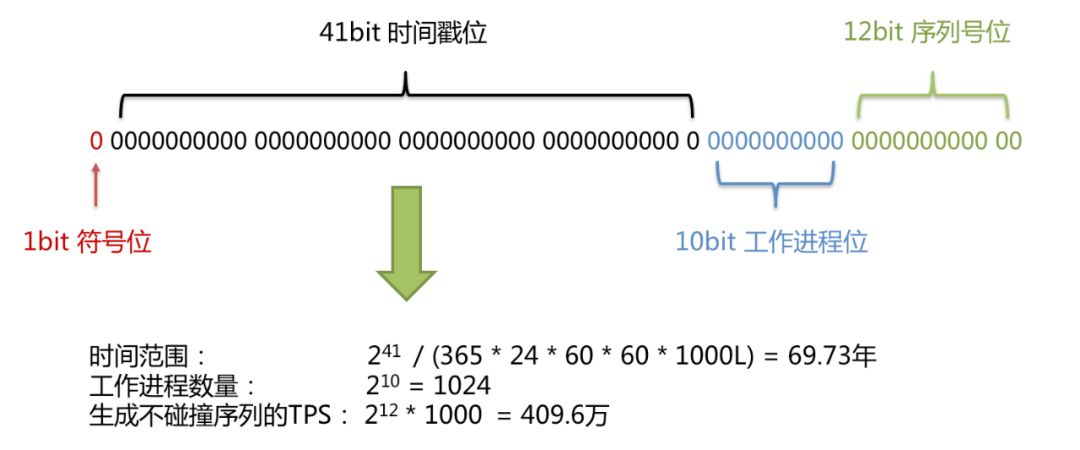
其中最高位保持为0,如果取值为1就会导致所生成的id变成负数。时间戳占41位,记录的是2016-11-01 00:00:00以来所经历过的毫秒数,“2016-11-01 00:00:00”这个时间是shardingsphere官方给定的,如果你使用它提供的雪花算法,那就是这个值。10位工作进程位,用于区分分布式系统下不同的系统进程,以避免单纯使用时间戳时,由于并发导致的时间戳刚好相等的情况。后面的12位是序列号,也就是同一毫秒内,同一个进程id,最多可以产生2的12次方条数据。
所以,拿到雪花算法产生的id,我们很容易就能从中扣取时间戳部分,只需要将id右移22位即可,由于最高位是0,并不需要处理。如:
long id = 341369369395200000;
long time = id>>>22;
报表的查询优化经历
这个报表统计我已经折腾有一个多月,一开始就简单sql查询返回,但是慢慢的,运营反馈说查询太慢了,所以就有了第一次的优化。
第一次优化:后台开一个定时任务,每天凌晨跑一次。以天为单位,统计昨天的报表数据,然后插入到MongoDB。查询接口只需从MongoDB查即可。
但是有个缺点,就是MongoDB并不能像sql一样,支持在查询的时候做除法运算。因为是按天统计的,当我选择时间范围为一个月的时候,就需要按月进行统计,然后排序。
报表的字段如下,记录的是一个广告一个小时内产生的收益:
广告id、时间(每个小时一条记录)、展示次数、点击次数、转化数、转化率、收益。
其中转化率是根据按日期统计后,再拿总的点击次数除以总的转化数。如果选择按转化率排序,那就需要在查询的时候计算出转化率。
现在,我要统计这个广告一个月内的总展示次数、总点击数、总转化数、转化率,然后根据转化率降序排序,那么sql应该这么写。
select 广告id,sum(展示次数),sum(点击数),sum(转化数)
,ROUND(sum(点击数)/sum(转化数),4) as 总的转化率,
from 报表
where day >= 开始时间
and day < 结束时间
group by 广告id
order by 总的转化率
limit 0,20;
由于MongoDB不支持在查询的时候做除法运算,所以我是将查询范围内的记录load到内存中,再根据广告id做统计(我只是说的例子,实际上比这复杂多)。也就是在内存中完成分组、计算转化率、排序、分页。
第二次优化:这次要解决的事情主要是以下四点。
1、【报表排序】 描述:在报表上方的各标题加上排序的功能,可以选择升序还是降序;也就是说数值类型的字段都需要支持排序。
2、【支持多个广告id一起查询】 描述:可以只查询一个或多个广告的收益统计。
3、【数据按日期区分展示】 描述:报表可以按照某一天或某个时间段,可以选择分天或者某个时间段的汇总展示数据情况。
比如我选择的时间范围是一个月,但是我选择分组区间是一天,那就是要统计每个广告这个月内、以每天为单位进行分组统计。
再比如我选择的时间范围是三天,但是我选择分组区间是一个小时,那就是要统计每个广告这三天内、以每个小时为单位进行分组统计。
4、【报表总计】 描述:在报表的最下方可以显示数据的总计,不管你选的统计区间是按天还是按小时,这一列显示的是按所选时间范围内,每一列的所有记录的总和(sum);
这次MG缓存的是数据库的直接拷贝,继续沿用将记录load到内存中处理,所以第二次优化并不难实现,只是更耗内存了。为避免频繁的请求,比如选择下一页,所以我加了一层内存缓存,如果查询、分组、排序等条件不变,只是分页变了,那就直接从内存取。因为报表的数据并不需要实时同步。
第三次优化:虽然经过前面两步的优化,感觉差不多了,但是,你有没有发现,无形之中又加了很多开销。比如内存的开销、mongodb的数据冗余,mongodb又存了一份数据库的数据。除了这些之外,单表的数据量剧增,影响到了插入数据的耗时。
所以,我想把原来缓存在内存中的数据移动到MongoDB,而原本缓存在MongoDB的数据就不要了,通过分表解决查询慢问题,分组、排序、分页还是在内存中完成,这是分表后不可避免的。
使用Sharding-JDBC实现分表
一开始我是想自己写一个框架的,但是考虑到时间不允许,一堆需求等着我去做,而且上次因为自己写的JDBC插件导致服务崩溃了几次,还是有点阴影的。刚好,前段时间看到Sharding-JDBC这个东东,就想折腾折腾。
其实,我并不建议使用Sharding-JDBC,如果可以,选择一层代理层,像mycat,会更好,不需要改动任何代码。而且Sharding-JDBC范围查询只支持BETWEEN,BETWEEN相当如”>=” and “<=“,两边都是闭区间,如果原本项目写的都是“>=” and “<“,那你就需要慢慢改代码了。
Sharding-JDBC的社区活跃度也并没有那么好,遇到一些坑,百度谷歌都找不到解决方案,只能调试源码。你从网上找的博客什么的,都是各种不同的版本,而我选择使用官网提供的文档上面使用的版本,就是献给apache之后的版本,目前就只有一个,4.0.0_RC1。https://shardingsphere.apache.org/document/current/cn/features/
在build.gradle中添加依赖,第二个是xa事务的依赖,如果用不到事务可以不用管。
//sharding-jdbc
compile group: 'org.apache.shardingsphere', name: 'sharding-jdbc-core', version: '4.0.0-RC1'
compile group: 'org.apache.shardingsphere', name: 'sharding-transaction-xa-core', version: '4.0.0-RC1'
接着是配置ShardingDataBase作为数据源。注意:如果项目中已经使用了动态数据源,需要将动态数据源去掉。
数据源还是以前的配置,比如原本使用druid做为连接池的配置,这部份不需要改动。
//mysql数据源
@Bean(name = "mysql-database")
public DataSource mysqlDatabase() {
DruidDataSource druidDataSource = new DruidDataSource();
//配置jdbc
druidDataSource.setDriverClassName(driverClassName);
druidDataSource.setUrl(jdbcUrl);
druidDataSource.setUsername(username);
druidDataSource.setPassword(password);
//配置连接池信息
try {
DruidPoolConfig druidPoolConfig = PropertiesUtils.getPropertiesConfig(DruidPoolConfig.class);
druidDataSource.setMinIdle(druidPoolConfig.getMinIdle());
druidDataSource.setMaxWait(druidPoolConfig.getMaxWait());
druidDataSource.setMaxActive(druidPoolConfig.getMaxActive());
druidDataSource.setInitialSize(druidPoolConfig.getInitialSize());
druidDataSource.setValidationQuery(druidPoolConfig.getValidationQuery());
druidDataSource.setTestOnBorrow(druidPoolConfig.getTestOnBorrow());
druidDataSource.setTestOnReturn(druidPoolConfig.getTestOnReturn());
druidDataSource.setTestWhileIdle(druidPoolConfig.getTestWhileIdle());
druidDataSource.setRemoveAbandonedTimeout(druidPoolConfig.getRemoveAbandonedTimeout().intValue());
druidDataSource.setRemoveAbandoned(druidPoolConfig.getRemoveAbandoned());
druidDataSource.setTimeBetweenEvictionRunsMillis(druidPoolConfig.getTimeBetweenEvictionRunsMillis());
} catch (Exception e) {
e.printStackTrace();
}
return druidDataSource;
}
Sharding主要的是配置分片规则。参考官网提供的使用java配置的例子:https://shardingsphere.apache.org/document/current/cn/manual/sharding-jdbc/configuration/config-java/
ShardingRuleConfiguration需要配置默认使用的数据源,因为不参与分表的其它表需要走默认数据源。
默认的分表策略选择NoneShardingStrategyConfiguration,即默认不配置分表规则的表都不进行分表;
默认的分库策略选择NoneShardingStrategyConfiguration,即默认情况下不分库。
因为本次只是为了分表,并没有进行分库,所以分库策略配置为NoneShardingStrategyConfiguration。
@Configuration
public class ShardingDataSourceConfig {
@Bean(name = "shardingDataSource")
@Primary
public DataSource dataSource(@Qualifier("mysql-database") DataSource mysqlDatabase) throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds01", mysqlDatabase);
DataSource shardingDataSource = ShardingDataSourceConfig.getShardingDataSource(dataSourceMap, "ds01");
return shardingDataSource;
}
/**
* 配置@Transactional事物注解
* 使用动态数据源
*
* @return
*/
@Bean
public PlatformTransactionManager transactionManager(@Qualifier("shardingDataSource") DataSource shardingDataSource) throws SQLException {
return new DataSourceTransactionManager(shardingDataSource);
}
/**
* 创建sharding-jdbc的数据源DataSource
*
* @param dataSourceMap 数据源
* @param defaultDataSourceName 默认数据库名,在dataSourceMap中的key
* @return
* @throws SQLException
*/
public static DataSource getShardingDataSource(Map<String, DataSource> dataSourceMap, String defaultDataSourceName) throws SQLException {
// 配置事务类型
TransactionTypeHolder.set(TransactionType.XA);
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
// 分表规则配置
shardingRuleConfig.getTableRuleConfigs().add(getReportTableRuleConfiguration());
shardingRuleConfig.getTableRuleConfigs().add(getReportClickInfoTableRuleConfiguration());
// 默认的分库策略, NoneShardingStrategyConfiguration用于配置不分片的策略。
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new NoneShardingStrategyConfiguration());
// 默认的分表策略
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new NoneShardingStrategyConfiguration());
// 指定没有分片规则使用的数据源
shardingRuleConfig.setDefaultDataSourceName(defaultDataSourceName);
// 其它参数配置
Properties props = new Properties();
props.put("sql.show", "true");
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, props);
}
/**
* 报表表,以日期分表,按月分表
*
* @return
*/
private static TableRuleConfiguration getReportTableRuleConfiguration() {
LocalDate skilDate = LocalDate.of(2019, 07, 01);
TableRuleConfiguration result = new TableRuleConfiguration("report_bill");
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("day",
new DatePreciseShardingAlgorithm(skilDate),
new DateRangeShardingAlgorithm(skilDate)));
// 配置分布式id生成算法,必须使用雪花算法,否则report_click_info表无法与之关联
Properties properties = new Properties();
properties.setProperty("worker.id", "1000");
result.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "id", properties));
return result;
}
/**
* 报表详情表
* @return
*/
private static TableRuleConfiguration getReportClickInfoTableRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration("report_click_info");
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("report_bill_id",
// skill为雪花算法的最小取值,为兼容现有表数据的查询
new IdKeyPreciseShardingAlgorithm(SnowflakeIdAlgorithmConfig.getStartSnowflakeId()),
new IdKeyRangeShardingAlgorithm(SnowflakeIdAlgorithmConfig.getStartSnowflakeId())));
return result;
}
实现按日期分表策略。
PreciseShardingAlgorithm:针对in 和 = 的查询计算出记录所在的表。比如in(1,2,3),会调用三次PreciseShardingAlgorithm,计算每个值所在的表。
RangeShardingAlgorithm:针对范围查询BETWEEN,计算出所需要查询的表。
/**
* 范围分片算法,用于BETWEEN
* <p>
* 由于mybatis拼接Date类型参数时,会在末尾加".毫秒"部分,影响查询性能,
* 所以日期我是直接使用字符串作为参数的
*
* @author wujiuye
*/
public final class DateRangeShardingAlgorithm implements RangeShardingAlgorithm<String> {
// 在这个时间之前的数据不分表
private LocalDate skip;
public DateRangeShardingAlgorithm(LocalDate skip) {
this.skip = skip;
}
/**
* 不能使用>=和<,只能使用BETWEEN ... AND ...
*
* @param collection
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {
Collection<String> result = new LinkedHashSet<>();
Range<String> range = rangeShardingValue.getValueRange();
// 处理BETWEEN (>=)
LocalDateTime startDateTime = LocalDateTime.parse(range.lowerEndpoint(), DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
// 处理AND (<=)
LocalDateTime endDateTime = LocalDateTime.parse(range.upperEndpoint(), DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
// 两个时间之间相差的月份
long monthInterval = startDateTime.until(endDateTime, ChronoUnit.MONTHS);
for (int interval = 0; interval <= monthInterval; interval++) {
// 在skip之前则使用逻辑表
if (skip.compareTo(startDateTime.toLocalDate().plusMonths(interval)) > 0) {
result.add(rangeShardingValue.getLogicTableName());
continue;
}
String yearMonth = startDateTime.plusMonths(interval).toLocalDate().format(DateTimeFormatter.ofPattern("yyyyMM"));
String tableName = rangeShardingValue.getLogicTableName() + "_" + yearMonth;
result.add(tableName);
}
return result;
}
}
/**
* @author wujiuye
* @version 1.0 on 2019/6 {描述:
* 精确分片算法,用于=和IN
* }
*/
public class DatePreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
// 在这个日期之前的数据不分表
private LocalDate skip;
public DatePreciseShardingAlgorithm(LocalDate skip) {
this.skip = skip;
}
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {
LocalDate valueDate = LocalDateTime.parse(preciseShardingValue.getValue(), DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))
.toLocalDate();
if (skip.compareTo(valueDate) > 0) {
return preciseShardingValue.getLogicTableName();
}
String name = valueDate.format(DateTimeFormatter.ofPattern("yyyyMM"));
return preciseShardingValue.getLogicTableName() + "_" + name;
}
}
报表详情表基于外键(报表id)实现分表,前面介绍了分表策略,是基于雪花算法,获取到id的时间戳部分,然后按月分表路由。
/**
* @author wujiuye
* @version 1.0 on 2019/6 {描述:
* 根据外键分表
* }
*/
public class IdKeyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
private final long skip;
public IdKeyPreciseShardingAlgorithm(long skip) {
this.skip = skip;
}
/**
* =和in。如果是in,则是每个value都会触发这个方法获取到对应的表
*
* @param collection
* @param preciseShardingValue
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
Long key = preciseShardingValue.getValue();
// 使用report_bill表的id计算表名,但是由于report_bill分表后id自增是从0开始的,所以必须保证id非自增
key -= skip;
if (key <= 0) {
// 兼容旧数据,使用逻辑表
return preciseShardingValue.getLogicTableName();
}
String name = SnowflakeIdAlgorithmConfig.computeDateTimeWithSnowflakeId(key).format(DateTimeFormatter.ofPattern("yyyyMM"));
return preciseShardingValue.getLogicTableName() + "_" + name;
}
}
/**
* @author wujiuye
* @version 1.0 on 2019/6 {描述:}
*/
public class IdKeyRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
private final long skip;
public IdKeyRangeShardingAlgorithm(long skip) {
this.skip = skip;
}
/**
* 不能使用>=和<,只能使用BETWEEN ... AND ...
*
* @param collection
* @param rangeShardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Collection<String> tables = new LinkedHashSet<>();
Range<Long> longRange = rangeShardingValue.getValueRange();
for (long i = longRange.lowerEndpoint(); i <= longRange.upperEndpoint(); i++) {
long key = i - skip;
if (key <= 0) {
// 兼容旧数据,使用逻辑表
tables.add(rangeShardingValue.getLogicTableName());
continue;
}
String name = SnowflakeIdAlgorithmConfig.computeDateTimeWithSnowflakeId(key).format(DateTimeFormatter.ofPattern("yyyyMM"));
String tbName = rangeShardingValue.getLogicTableName() + "_" + name;
tables.add(tbName);
}
return tables;
}
}
根据雪花算法生成的id获取时间戳部分,并转化为日期的代码实现如下。
【SnowflakeIdAlgorithmConfig类】
/**
* 根据分布式id获取日期,再根据日期获取分表
*
* @param snowflakeId 64bit雪花算法,按官方提供的标准走
* @return
*/
public static LocalDateTime computeDateTimeWithSnowflakeId(long snowflakeId) {
long timestamp = snowflakeId >> 22;
// 2016-11-01 00:00:00
LocalDateTime dateTime20161101 = LocalDateTime.parse("2016-11-01 00:00:00", DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
LocalDateTime keyDateTime = dateTime20161101.plus(timestamp, ChronoUnit.MILLIS);
return keyDateTime;
}
SQL的写法如下。
<mapper namespace="com.sharding.dao.ReportMapper">
<select id="selectByRangDate" resultType="map">
select * from report_bill where `day` BETWEEN #{startDate} and #{endDate} and cheat_pb_cnt>0
</select>
<select id="selectDetailByRangDate" resultType="map">
<!-- 像这种查询,第二个表没有入参分表的列,所以第二个表的分表就不起作用,不能这么写,只能先查询出主表的,再使用子查询查询join表的 -->
select * from report_bill r left join report_click_info rc on r.id=rc.report_bill_id
where r.day BETWEEN #{startDate} and #{endDate}
and r.cheat_pb_cnt>0
</select>
<select id="selectDetailByReportId" resultType="map">
select * from report_click_info where report_bill_id in
<foreach collection="ids" item="reportId" open="(" separator="," close=")">
#{reportId}
</foreach>
</select>
</mapper>
原有项目配置了动态数据源,如何与Sharding-JDBC整合
原本定时任务就已经使用了动态数据源,而且一个数据源是mysql,另两个是亚马逊的db,而Sharding-JDBC并不支持亚马逊的那两个db,显然是不能去掉动态数据源的,只能想办法让两者并存。
怎样让两者并存,且互不影响
我的想法是,将mysql数据源配置给Sharding-JDBC数据源,让Sharding-JDBC管理,而动态数据源则管理Sharding-JDBC数据源。配置并不需要改动什么。事务管理者依然是使用动态数据源配置。
只需要将原本动态数据源的配置修改为如下,将原本mysql数据源的位置替换为Sharding-JDBC数据源即可。事务的配置不需要改。
/**
* 动态数据源: 通过AOP在不同数据源之间动态切换
*
* @return
*/
@Primary
@Bean(name = "dynamicDataSource")
public DataSource dynamicDataSource(@Qualifier("shardingDataSource") DataSource shardingDataSource,
@Qualifier("athena-database") DataSource athenaDatabase) {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
// 默认数据源,当没有使用@DataSource注解时使用,
// 而使用了@DataSource注解如果没有设置beanName也要Aop自己配置使用默认的bean
dynamicDataSource.setDefaultTargetDataSource(shardingDataSource);
// 配置多数据源
// key -> bean
Map<Object, Object> dsMap = new HashMap();
dsMap.put(DataSourceContextHolder.getDefaultDataSource(), shardingDataSource);
dsMap.put("athenaDatabase", athenaDatabase);
dynamicDataSource.setTargetDataSources(dsMap);
return dynamicDataSource;
}
/**
* 配置@Transactional事物注解
* 使用动态数据源
*
* @return
*/
@Bean("dynamicDataSourceTransactionManager")
public PlatformTransactionManager transactionManager(@Qualifier("dynamicDataSource") DataSource dynamicDataSource) {
return new DataSourceTransactionManager(dynamicDataSource);
}
将mysql数据源配置给Sharding-JDBC数据源。
@Bean(name = "shardingDataSource")
public DataSource dataSource(@Qualifier("mysql-database") DataSource mysqlDatabase) throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds01", mysqlDatabase);
return ShardingDataSourceConfig.getShardingDataSource(dataSourceMap, "ds01");
}
事务的配置为什么不用改
如果不是配置多个数据源且多个数据源之间没有统一的管理者,那么才需要为每个数据源配置一个事务管理者。
看下DataSourceTransactionManager的源码你就明白了。DataSourceTransactionManager是通过数据源获取连接Connection的,事务的提交与回滚调用的是Connection的commit与rollback方法。所以,使用动态数据源,事务管理者获取到的就是目标数据源返回的连接Connection。
现在只是将Sharding-JDBC数据源配置给动态数据源,而mysql数据源则配置给Sharding-JDBC数据源。Sharding-JDBC数据源跟动态数据源一样,在getConnection被调用时动态选择目标数据源,然后调用所选数据源的getConnection方法。这是一种设计模式,外界并不需要关心具体是如何获取到正确的数据源的Connection的。
插入数据是否使用雪花算法自动生成ID
我在配置中指定了自增主键使用雪花算法生成的id。因为分表后不能再使用数据库的自增主键,否则根据id查找数据不知道查哪个表的,而且关联的表还需要使用这个id进行分表。
在配置表的路由规则的时候,除了配置表的分片策略,如果需要修改主键的生成,还需要给表的路由配置添加主键生成器,如下配置。官方提供uuid和雪花算法两种分布式主键生成方法。
// 配置分布式id生成算法,必须使用雪花算法,否则report_click_info表无法与之关联
Properties properties = new Properties();
properties.setProperty("worker.id", "10");
result.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "id", properties));
为何使用雪花算法:
1.雪花算法生成的id是增长的,也就是有序的。在插入时不需要调整索引B+树。
2.原本数据库中的id是整型,BIGINT(20),所以使用雪花算法不需要修改表的结构,也不需要添加额外的列。
3.使用雪花算法可以推算出日期,对于关联表可以使用这个特点实现分表。
验证结果如下图,不出意料,确实在插入数据的使用Sharding-JDBC改写了sql,加入id字段,并使用雪花算法生成一个id。

图中billid是我在完成数据的插入之后,查询出来的id。
表不存在时会自动创建表吗
我把官方文档从头到尾看了一个遍,但是却没有找到关于自动创建表的介绍,所以说Sharding-JDBC并没有智能到会帮我们创建表。当按分表算法计算出来的物理表不存在时,便会出现一堆的异常信息。
Table 'cayman.report_click_info_201906' doesn't exist
我目前的做法是提前创建好未来的几个月的表。缺点就是,如果有时候忘记了,整个服务都会因此而奔溃。
目前我所能想到的就是在计算表名的时候(ShardingAlgorithm的doSharding方法中),判断一下这个表是否存在,不存在则创建,但是每次都判断一次很耗性能。单库还好,多库(分库)情况下更糟糕。
插入新记录会根据分片字段路由到表吗
插入新记录时,必须保证分片字段的值不能为空,否则直接报错。因为分片字段没有值,就没有办法路由到物理表,算不出来要插入哪个表,只能放弃抛出异常了。
正常情况下不允许使用可以为null的字段进行分片。如果是使用日期类型的字段,如记录的创建时间create_datetime,作为分片(分表)字段,就不能在创建表的时候声明默认使用系统的当前时间,应该由插入数据的时候指定值,并且设置为不能为空。避免墨菲定律。