![]()
我们可以通过修改redis.conf配置文件来选择使用持久化策略,redis提供了三种持久化策略。
RDB快照(snapshot)
redis.conf配置文件默认情况下就是选用这种策略,在redis.conf同级目录下会出现一个dump.rdb的二进制文件。我们来看下redis.conf的默认配置。
################################ SNAPSHOTTING ################################
#
# 将数据库保存在磁盘上:
#
# save <seconds> <changes>
save 900 1
save 300 10
save 60 10000
配置格式为:
save <seconds> <changes>
如果到达了间隔的给定的秒数,而且在这段间隔时间内发生了指定的数据改变次数(如写操作),则会保存数据库快照到磁盘。
理解官方给的默认配置:
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
- 在900秒之后,如果至少有一个键的数据发生了改变(该键被删除,或者该键的值有改动),那么执行一次保存操作。
- 在300秒之后,如果至少有10个键的数据发生了改变,那么执行一次保存操作。
- 在60秒之后,如果至少有10000个键的数据发生了改变,那么执行一次保存操作。
假设到了60秒之后第三个条件没有满足,那么什么也不做,接着到了300秒之后,如果条件依然没有满足,那么什么也不做,继续到了900秒之后如果条件满足了,就是执行一次保存操作,执行完成之后更新计时;假设到了60秒之后第三个条件满足了,那么就会执行一次保存操作,然后就更新计时了。所有这些配置是按钮时间顺序排序的。
dbfilename dump.rdb
dbfilename是配置快照的文件名,没什么好说的。
测试一下,将上面配置修改为如下
save 30 1
dbfilename dump.rdb
即30秒内如果有一个key发生了改变,那么就执行一次保存操作。另起一个终端,第一次执行一条指令后会出现一个dump.rdb文件,接着再执行一次set操作。
-rw-r--r-- 1 wjy staff 119 12 6 18:59 dump.rdb
等待30秒后看看,由于后面的快照会覆盖前面的,所以只能从文件的修改时间来判断是否执行保存操作。
-rw-r--r-- 1 wjy staff 117 12 6 19:01 dump.rdb
我发现这个时间是这样计算的,如果没有满足任何一个“save ”规则那么计时是不会重新计算的,也就是说当你30秒之后才执行一次set操作,那么会马上触发这个条件,执行保存操作,然后才更新计时。而如果距离上一次执行保存操作已经过去了15秒,当你这时候执行一条set操作时,将在15秒之后得到触发。
AOF(Append-only file)
使用RDB也会有缺陷,比如因故障原因导致redis进程死掉,那么将会丢失最近变动且未达到触发保存操作条件的数据,所以才有了AOF。AOF持久化跟RDB是完全不同的,AOF是将修改的每一条指令追加到.aof文件尾,当redis重启时,就会读取.aof文件中的指令,一条条顺序执行,这样数据就恢复了。
来看看如何配置。
############################## APPEND ONLY MODE ###############################
#是否开启aof
#appendonly no
appendonly yes
#aof文件名
appendfilename "appendonly.aof"
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
“auto-aof-rewrite-min-size”这一行配置的是:自动重写aof文件,当aof文件达到最小大小64mb时就开始重写,重写时将所有的相同的key操作整合为一条指令,比如旧的aof文件中有几万条对key=myname的记录做set操作,那么重写时就只会set最后一次set操作的值。这个后面还会再说一次。
现在来重启一次redis服务。
-rw-r--r-- 1 wjy staff 286 12 6 19:03 appendonly.aof
重启之后在redis.conf同级目录下多出了一个appendonly.aof文件,先用redis-cli执行一条set指令和一条get指令,看看appendonly.aof文件的变化。
27.0.0.1:6379> set wujiuye 123
OK
127.0.0.1:6379> get wuijuye
"123"
看看当前appendonly.aof文件中保存了什么
*2
$6
SELECT
$1
0
*3
$3
set
$7
wujiuye
$3
123
勉强看得出,保存了一条“set wujiuye 123”指令,而get指令并没有保存,也就是说不对数据产生改变的指令都不会保存到aof文件。
通过配置appendfsync可以执行aof保存的策略。
appendfsync everysec
- always:总是。即每条对数据产出修改的指令都会追加到文件尾;
- everysec:每秒。即每秒执行一次写aof文件,将一秒内发生对数据修改的指令都追加到文件尾;
- no:从不。
混合策略
混合策略就是rdb和aof组合使用,配置很简单:
#是否开启aof和rdb混合持久化模式
#aof-use-rdb-preamble no
aof-use-rdb-preamble yes
找到aof-use-rdb-preamble,将no改为yes就可以了,配置完成后重启服务。
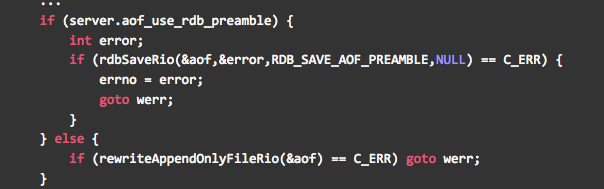
配置文件上的注释:当加载Redis时,也就是当redis重启时,识别出AOF文件以“Redis”字符串开头并加载带前缀的RDB文件,然后继续加载AOF尾部。
关于混合策略下的aof重写
随着redis服务运行时间,aof文件里可能有太多没用指令,所以aof会定期根据内存的最新数据生成aof文件。AOF在重写时将重写这一刻之前的内存rdb快照文件的内容和增量的AOF修改内存数据的命令日志文件,都写入新的aof文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名恢复为appendonly.aof,原子的覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
在Redis重启的时候,是先加载 rdb的内容,然后再重放增量AOF日志就可以完全替代之前的AOF全量文件重放,重启效率因此大幅得到提升。AOF根据配置规则在后台自动重写,也可以连接上redis服务执行命令bgrewriteaof重写AOF。
重写aof文件如果文件很大,重写需要花很长时间,这个时候如果刚好有了新操作的数据,那么新操作会存在内存里,等到aof重写完再追加到aof文件的末尾,aof重写的数据就是重写开始之前的内存数据。
如果redis从启动以来都是对一个string的incr操作,redis的AOP重写是不是只能一条条执行每个incr命令?
没开启混合持久化的话aof重写直接用set类似的命令持久化内存,开启混合持久化的话是先把内存的快照保存到aof文件里,之后的redis修改操作再最加到aof文件后面,也就是说开启混合策略后aof文件存储格式是rdb+aof,恢复顺序是先恢复rdb,然后恢复aof,aof的指令顺序执行。如果aof重写,则rdb部分不变,其它将对影响同一个key的值的操作(set、del等指令)以最后一次操作后的值写入一条新的set指令,如incr lock指令有几万条,而最后一次incr lock后lock的值为1,那么重写时就只需要写一条set lock 1指令。
不要用keys,用scan指令
不能使用keys指令,因为redis执行指令是单线程执行的,如果执行一条很耗时的指令那么所有的指令都处于等待状态,如过key很多的情况下redis进行全局扫描那么keys将一直占用线程。建议使用scan指令,因为scan指令是按游标位置开始扫描,扫描到指定的记录数就停止了。
游标并不是顺序的,这跟redis的存储结构有关系,redis的存储结构是hashtable格式,按照key进行hash存储,scan是按照hash的一维数组逐个往下读取的。
scan 游标位置 match 正则表达式 count 要取的数量
127.0.0.1:6379> scan 0 match key* count 2
1) "6" #当前游标位置
2) 1) "key01"
2) "key2131"
127.0.0.1:6379> scan 6 match key* count 2
1) "1" #当前游标的位置,下次就可以从该游标开始扫描
2) 1) "keydfsdf"
2) "key"
127.0.0.1:6379> scan 1 match key* count 2
1) "0" #游标又回到开始位置,即已经全盘扫描完
2) 1) "key999"
hash冲突后不是马上进行rehash,当hash出现重复记录时使用链表方式存储该hash值下的记录,当redis扩容后所有元素再做rehash重新定位,扩容是根据redis内部的扩容因子来计算的,跟hashmap扩容类似,冲突一直都可能有,只不过redis会尽量通过扩容来减小冲突。