![]()
看了很多大佬的观点,关于应用容器化部署之后,日记如何收集的问题,也就三个方案:
- 在Node节点上以DaemonSet部署日记收集容器
- 将日记收集容器以SideCar注入到Pod
- 直接应用中通过网络发出
Serverless帮助我们实现了自动扩缩容,但要实现真正的按需付费,就要使用弹性的物理节点,例如AWS的Fargate,使用EKS将Pod调度到Fargate上。这也注定了不会有固定的Node去运行Pod,因此在Node上以DaemonSet部署日记收集容器的方案就走不通了。
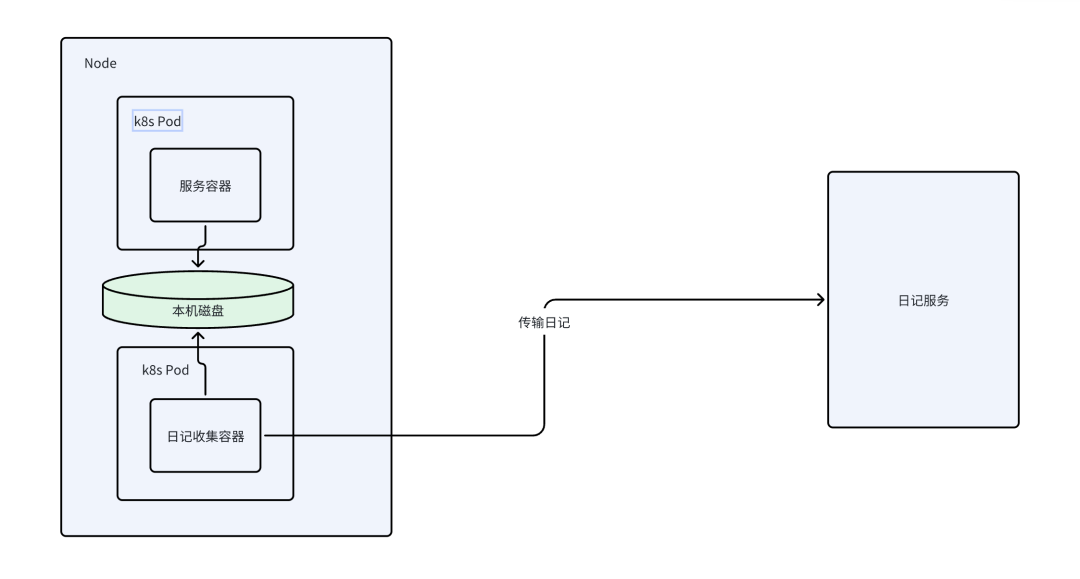
只剩两种方案:
- 通过SideCar部署日记收集容器,和主容器共享pv,如图2
- 直接走网络写,如图3、图4
方案一是通过SideCar容器使用FileBeat或其它工具收集日记,SideCar容器和主容器使用相同的PV(共享Volume),主容器日记落盘到PV,SideCar容器从PV读日记。
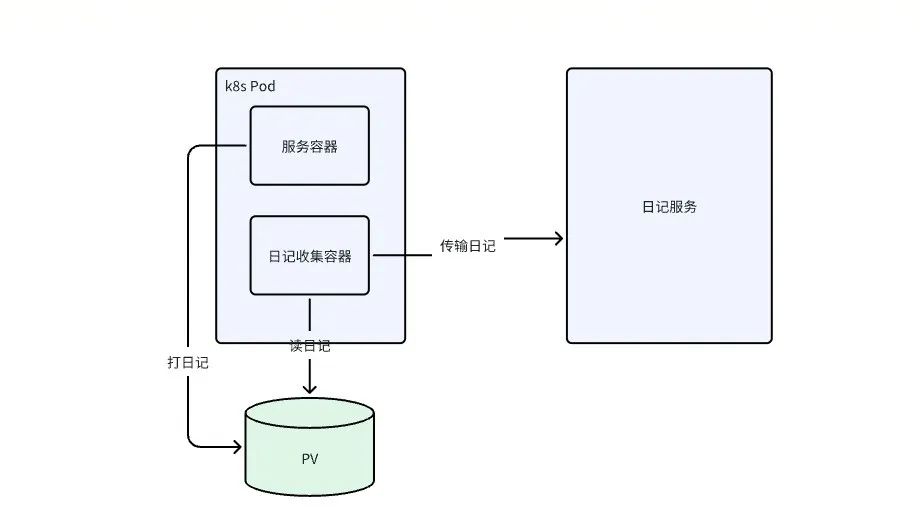
这种方式的缺点是,需要为每个Pod加一个SideCar容器,占用资源多。但这种方式也比较灵活,不需要业务去配置改动升级,而且日记收集一般是中间件团队维护,收集工具的bug修复和性能优化迭代的发布,都能通过k8s提供的Pod容器原地升级的能力去更新。
这种方式相比DaemonSet,还实现了物理上的隔离,多个Pod之间互不影响,不需要应用服务指定不同的日记输出路径,架构上会比DaemonSet更“多租户”。
不过使用SideCar模式需要开发管理的能力,怎么注入SideCar,以及SideCar容器的原地升级的实现。
方案二的实现就是将日记通过网络传输打到远端代理服务上。优点是架构简单,不会占用过多资源。但缺点是,需要代码层面改动配置,需要引入sdk,另外就是会占用出口带宽,日记丢失的风险大。
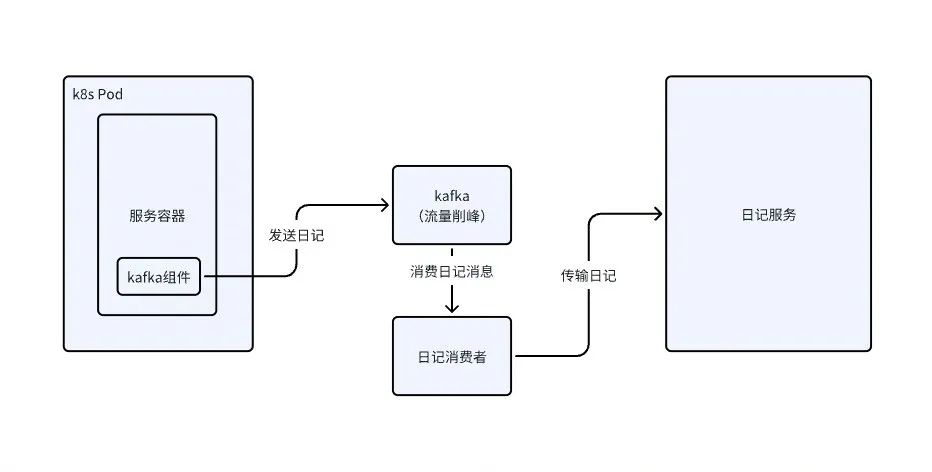
例如腾讯云的日记服务也提供tencentcloud-cls-log4j-appender SDK实现日记不落盘直接网络传输。当然我们也可以自己实现Appender,然后通过kafka将日记发送到kafka服务,再由一个消费者去消费转存。另外我们也可以自研,将日记打到一个日记收集服务再转存。
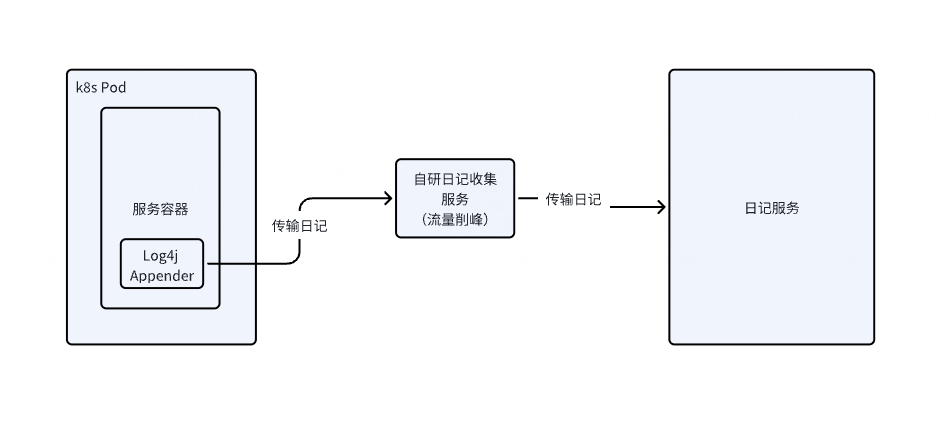
为什么需要中转一下?因为如果我们ES去存储日记的话,流量直接打到ES,ES会扛不住。通过kafka去消费也可以起动削峰填谷的作用。