![]()
本篇文章写于2021年10月13日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
为什么加上“原生”,因为我们基于BFE开发已经魔改了。
路由转发是BFE作为一个七层流量代理服务的核心功能,BFE设计了一套支持多租户、多机房的路由转发模型。
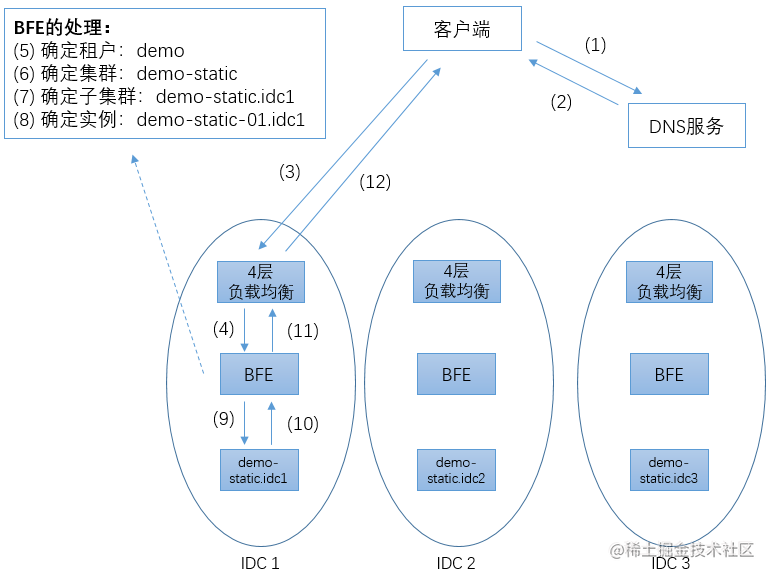
图片来源:《深入理解BFE》
基本概念
在原生路由转发功能中,bfe对租户、集群、子集群、实例的概念解释如下:
- 租户:product,不同业务线/不同产品线;
- 集群:一个产品会有多个微服务,例如一个商城产品可能会有用户微服务、订单微服务、库存微服务,每个微服务就是一个集群;
- 子集群:通常一个集群只有一个子集群,除非存在多数据中心;
- 实例:每个子集群可以有多个后端服务实例,“ip+端口”为一个实例,一个微服务部署多少个节点就有多少个实例;
相关配置文件
- host_rule:配置租户与标签的映射,以及标签与域名的映射,用于通过域名获取标签,再通过标签确定租户;
- vip_rule:配置ip与租户的映射,用于通过ip确定租户;
- route_rule:配置路由规则,即请求如何路由到集群;
- cluster_rule:集群常规配置,如心跳检测接口、请求后端超时时间、最大重试次数等等;
- gslb:配置全局负载均衡,即配置集群下的子集群的权重,用于负载均衡选择集群下的子集群;
- cluster_table:集群->子集群->实例配置文件;
路由转发过程
与路由相关的流程:确定租户->确定集群->确定子集群->确定实例
与转发相关的流程:获取转发器->转发请求
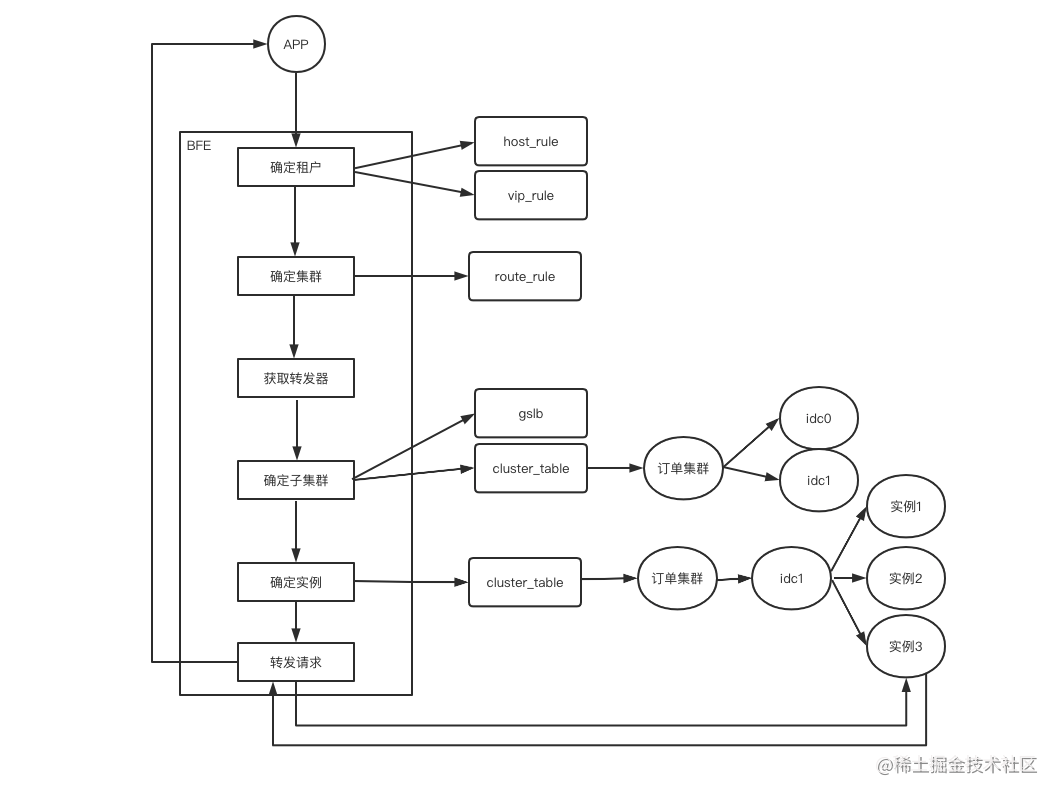
确定租户
- 1、根据请求的host(域名)从host_rule配置中查找该host映射的租户;
- 2、如果host映射不到租户,或者host是ip地址,那么根据ip从vip_rule配置文件中查找ip映射的租户;
确定集群
- 1、根据租户名称从route_rule配置中获取该租户的所有路由规则;
- 2、按规则配置的顺序,遍历路由规则,获取第一个匹配当前请求的路由规则(匹配逻辑与限流的匹配逻辑相同);
- 3、获取匹配的路由规则配置的集群名称;
获取转发器
- 1、根据集群名称,从cluster_rule配置文件中查找该集群的配置;
- 2、根据集群配置获取或创建转发器;
确定子集群
- 1、根据集群名称,从gslb配置文件中查找该集群的所有子集群,再根据子集群的权重负载均衡选择一个子集群;
- 2、从cluster_table配置文件中获取该子集群下的所有实例;
确定实例
- 1、从子集群中,根据权重负载均衡选择一个实例;
转发请求
- 1、使用转发器,传入后端地址,根据后端地址和请求协议创建连接或获取空闲的连接;
- 2、使用连接转发请求;
说明:这些步骤中的从xx配置文件中查找/获取xx配置,只是为了便于理解才这样描述,实际上,BFE在启动时就已经加载所有配置文件缓存在内存中了。
案例分析
商城产品线(ShoppMall),域名为shoppmall.com,订单服务(OrderService)部署在中国机房(CN-idc0),部署三个实例。
相关配置如下:
host_rule:
{
"Version": "1.0.0",
"DefaultProduct": null,
"Hosts": {
// 对应HostTags下的配置
"ShoppMallTag":[
"shoppmall.com"
]
},
"HostTags": {
"ShoppMall":[
// 标签随便定
"ShoppMallTag"
]
}
}
route_rule:
{
"Version": "1.0.0",
"ProductRule": {
"ShoppMall": [
{
// 以/order开头的请求路由到OrderService微服务
"Cond": "req_path_prefix_in("/order")",
"ClusterName": "OrderService"
}
]
}
}
cluster_rule:
{
"Version": "init version",
"Config": {
// OrderService集群的基础配置
"OrderService": {
// 请求后端相关:连接超时等
"BackendConf": {
"TimeoutConnSrv": 2000,
"TimeoutResponseHeader": 50000,
"MaxIdleConnsPerHost": 0,
"RetryLevel": 0
},
// 心跳检测配置
"CheckConf": {
"Schem": "http",
"Uri": "/healthcheck",
"Host": "example.org",
"StatusCode": 200,
"FailNum": 10,
"CheckInterval": 1000
},
// 全局负载均衡策略配置
"GslbBasic": {
"CrossRetry": 0,
"RetryMax": 2,
"HashConf": {
"HashStrategy": 0,
"HashHeader": "Cookie:UID",
"SessionSticky": false
}
},
// 客户端读写相关
"ClusterBasic": {
"TimeoutReadClient": 30000,
"TimeoutWriteClient": 60000,
"TimeoutReadClientAgain": 30000,
"ReqWriteBufferSize": 512,
"ReqFlushInterval": 0,
"ResFlushInterval": -1,
"CancelOnClientClose": false
}
}
}
}
gslb:
{
"Clusters": {
// 订单集群的子集群配置
"OrderService": {
"GSLB_BLACKHOLE": 0,
"CN-idc0": 100
}
},
"Hostname": "",
"Ts": "0"
}
cluster_table:
{
"Version": "1.0.0",
"Config": {
// 集群
"OrderService": {
// 子集群
"CN-idc0": [
// 实例
{
"Addr": "127.0.0.1",
"Name": "example_hostname",
"Port": 8180,
"Weight": 10
},
{
"Addr": "127.0.0.1",
"Name": "example_hostname",
"Port": 8181,
"Weight": 10
},
{
"Addr": "127.0.0.1",
"Name": "example_hostname",
"Port": 8182,
"Weight": 10
}
]
}
}
客户端发送POST http://shoppmall.com/order/createOrder请求路由过程如下:
- 1、根据host:shoppmall.com,路由到租户:ShoppMall;
- 2、获取ShoppMall租户的所有路由规则,路径“/order/createOrder”匹配到集群为OrderService;
- 3、根据集群获取gslb配置,路由到子集群为CN-idc0;
- 4、根据集群:OrderService、子集群:CN-idc0,获取到三个后端实例:127.0.0.1:8180、127.0.0.1:8181、127.0.0.1:8182;
- 5、从三个实例中负载均衡选择一个实例。
总结
笔者个人觉得,BFE的路由配置文件太多了,而且不太直观,有点绕,不区分租户配置,将会导致一个文件一大堆的配置,不易于管理。
可能是开源的缘故,bfe不想依赖其它第三方如配置中心、数据库之类的服务,所以才改为使用配置文件配置,又或者原本设计就是使用文件配置。而这其实与使用nginx一样,需要经常修改配置文件。