![]()
本篇文章写于2021年08月15日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
由于Kafka不支持延迟消息,而目前公司技术栈中消息中间件使用的是Kafka,业务方希望使用RocketMQ满足延迟消息场景,但如果仅仅只是需要延迟消息功能而引入多一套消息中间件,这会增加运维与维护成本。在此背景下,我们希望通过扩展Kafka客户端提供延迟消息的支持。
本篇将介绍四种延迟消息实现方案的原理,以及分析其优缺点。
方案一:时间轮算法
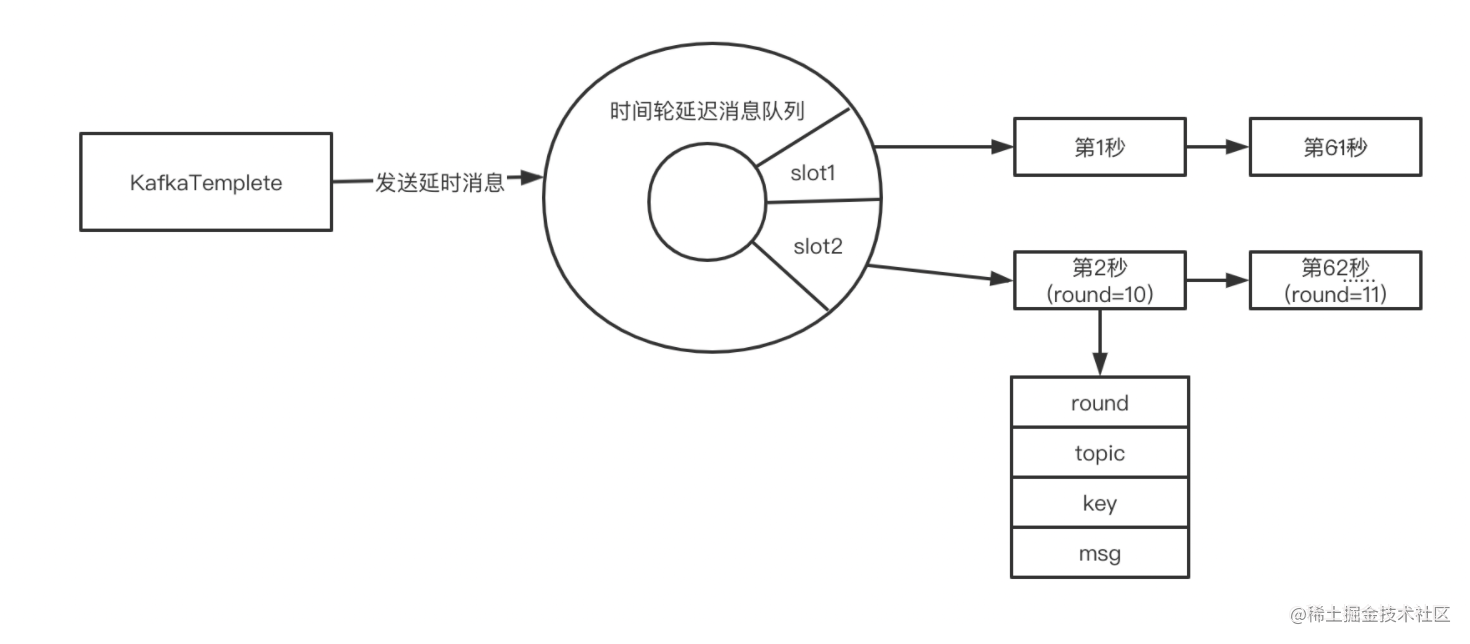
每个生产者持有一个时间轮延迟消息队列,消息保存在内存中。
- slot = (当前时间戳 - 时间轮启动时间) % slot总数;
- round = (当前时间戳 - 时间轮启动时间) / slot总数;
- 延时消息链表: 按round排序。
缺点分析:
- 消耗内存资源严重,只适用于延迟时间短(如一分钟内)的场景;
- 容易丢失消息。
方案二:单轮时间轮算法+文件存储(方案一的改进版)
使用单轮的时间轮算法,单轮的slot数量满足max delay = slot count,并让每个slot指向一个文件。
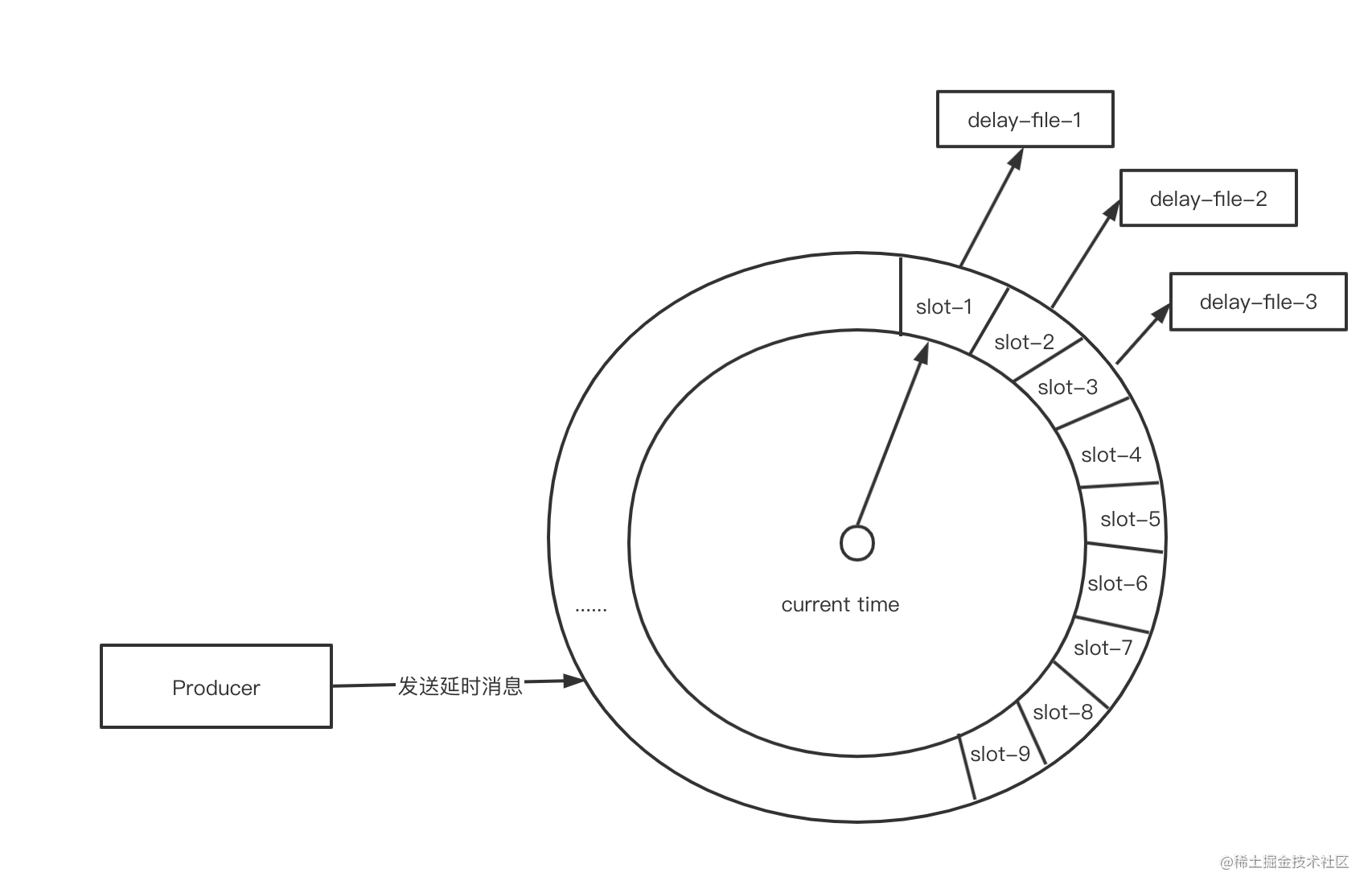
缺点分析:
- 如果服务容器化部署,重新构建后也会导致时间轮文件丢失,无法保证消息一致性。
方案三:多级分区+自动降级
按等级划分多个分区,根据剩余延时(期望发送时间-当前时间)将消息降级到指定分区,直到降级到真实topic。
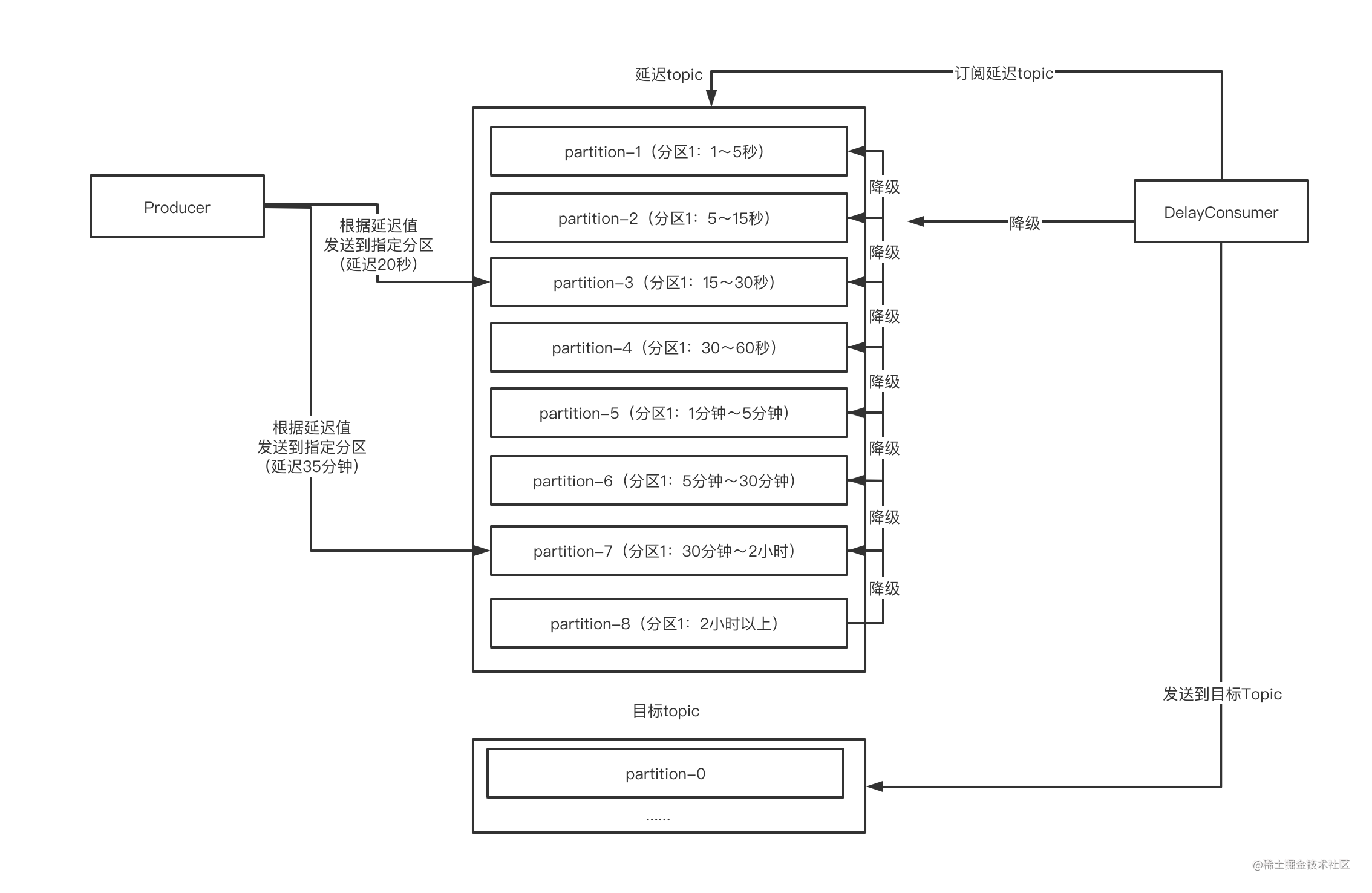
缺点分析:
- 需要经过多次发送-订阅,如果按照图中的等级划分,那么一个延迟2小时的消息至少要经过8次订阅、9次发送才最终发送到目标topic;
- 由于同一个等级中每个消息的延时不同,如果要确保消息延迟准确,就可能导致一条消息不止需要经过8次订阅、9次发送才最终发送到目标topic,这次数可能会翻好几倍。
比如都是30~60分钟的等级,如果目前队列中的几条消息按顺序延迟值分别为:50、40、36、56,为了不影响后面的延时消息,前面每个消息都必须要消费,然后重新写回同等级分区。因此,最坏的情况下,延时高的消息可能需要经过上百次发送-订阅才能完成。
方案四:多级延迟,不支持任意时间精度的延迟消息(方案三的改进版)
参考RocketMQ支持延迟消息设计,不支持任意时间精度的延迟消息,只支持特定级别的延迟消息,将消息延迟等级分为1s、5s、10s 、30s、1m、2m、3m、4m、5m、6m、7m、8m、9m、10m、20m、30m、1h、2h,共18个级别,只创建一个有18个分区的延时topic,每个分区对应不同延时等级。
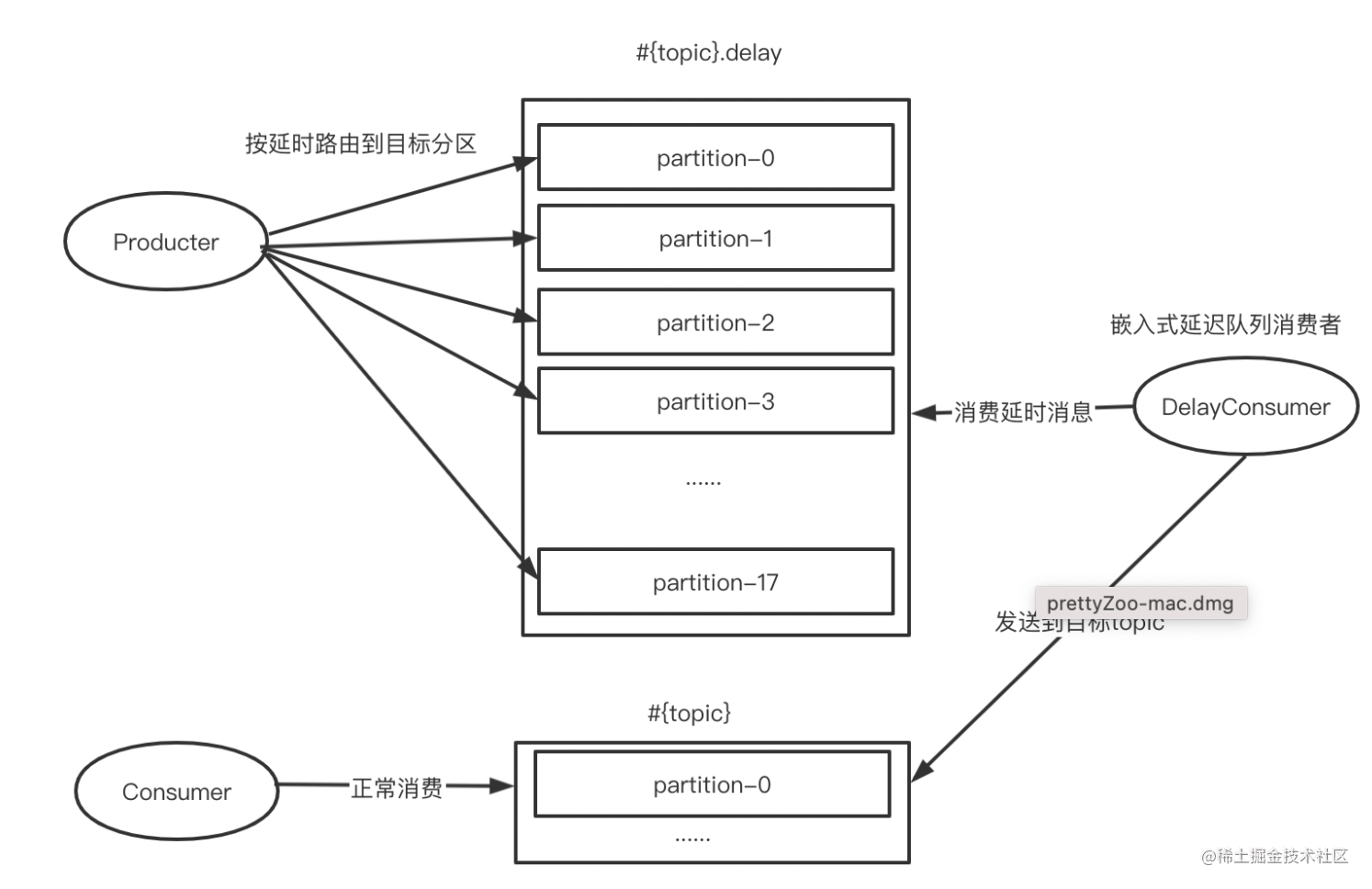
举例:
- 当发送延迟5秒消息时,将消息发送到order-topic.delay的第二个分区;
- 当发送延迟1分钟消息时,将消息发送到order-topic.delay的第五个分区;
- 当发送延迟1小时消息时,将消息发送到order-topic.delay的第17个分区;
优点:
- 保证了每个分区中的消息都是时间顺序的,只需要顺序消费每个分区,将已经达到发送时间的消息转发到真实topic即可;
- 如果消息未到达发送时间,则不需要提交offset,因为相同分区上的offset之后的消息也必定是未到发送时间的。
我们最终采用的是方案四,在实现上,我们为每个进程启动一个KafkaConsumer,使用正则表达式订阅以’.delay’结尾的topic,以此减少线程资源的消耗。在将消息发送到延迟topic时,将延迟等级作为消息key,而将原消息key存储在消息头,等发送到实际topic时再从延迟消息的消息头获取real key以及real topic。