![]()
话说在前面,本篇并不会去比较fastjson与Jackson在正常业务场景下的json解析性能,侧重点是比较两者在解析大json字符串上的性能。可以给出的结论是,jackson在解析大json场景下性能是秒杀fastjson的,不急,我们有图有真相。
我对大Json的定义是,超过1m大小的json字符串可以算是大json了。可能大家平时都没有遇到超过1m大小的json字符串,最多也就几百kb级别的,而这个级别json,fastjson与jackson解析性能比较可以参考网上的一些分析文章。
我遇到的大Json解析场景,来自第三方接口的调用。最大的有64m的json字符串,这是输出到文本文件后以文件的大小计算的。有些第三方接口没有分页的功能,我遇到一次一个接口调用返回几百万条数据的,也是从那次开始,发现fastjson的弊端。
之前测试过一次,64m的json用fastjson解析花了一个多小时,,这种场景下,fastjson不再fast。而今天我再测试一次一个只有2000条记录的json字符串解析,分别用fastjson与jackson解析,比较两者的性能。
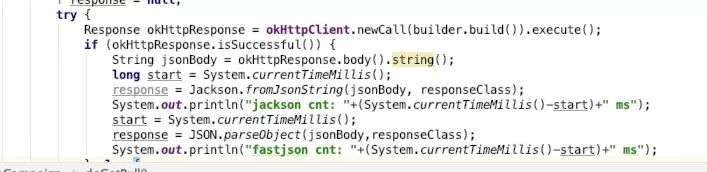
从测试代码中可以看出,这是一个调用第三方接口,拿到响应body之后,再分别使用fastjson与jackson测试解析耗时的例子。
方法输出:

可以看到,jackson解析耗时只需要318毫秒,而fastjson却要641459毫秒,这差的不是一星半点,整整2017倍。而且json字符串越长,性能差异越大,大家可以亲自去测试一下,模拟一个超过1m大小的字符串,分别使用fastjson与jackson测试。
Fastjson其实也给出了针对这种大json解析场景的解决方案,stream api,但并不能解决大部分的业务场景。感兴趣可以去研究下。
你可能想通过缩短Json字符串解决这个问题,确实也是,谁会这么无聊,设置响应如此大数据量的接口,简直就是数据库拷贝。这确实可以通过接口支持分页解决,但你没办法让别人去改变这种设计,接口是别人家的,人家改不改是别人家的事情,我们能做的只有自己去优化。