![]()
本篇介绍如何使用Redis的Sorted Set数据结构实现支持范围查找的IP库缓存方案。
使用Sorted Set实现范围查找
最近系统需要更新IP库,IP库存储的是IP所属的国家和城市信息,广告主投放广告会有区域限制,所以需要根据点击广告的终端ip,获取位置信息,并判断是否满足广告投放区域的要求。
最头疼的是,IP信息库是按区间存储的,拿到一个ip得要知道它所属的范围才能知道它对应哪条记录。它的表结构是这样的:
Ip_from,ip_to,ccountry_code,country,regin,city
Ip起始段,Ip结束段,国家编码,国家,区域(比如中国的省),城市

而Ip_from和ip_to是一个数值,将ip通过公式转化后的数值。
a.b.c.d
A*(256*256*256)+b*(256*256)+c*(256)+d
为了效率,程序中的转换可以写为
a*(1<<24)+b*(1<<16)+c*(1<<8)+d
在此之前我都没注意以前是怎么实现查找的,以前是用内存缓存实现,但以前的数据比较少,而查找的方式用的递归,先不说递归查找算法的缺陷。而新的ip库数据量很大,本地debug直接OOM,没有足够的内存撑起这么大的ip库。
如果说,一个csv文件的大小是1g多,那么读取到jvm中,就需要4g甚至更高的内存,因为一个对象占的内存是比一行逗号隔开的字符串耗更大的内存。要实现查找算法,创建对应的数据结构,这些也会占用很大的内存。
综上所述,我们考虑用redis来缓存,当然,也可以用mongodb,如果是用mongodb缓存,那就简单了。既然要用Redis,那么就不得不面对,Redis如何实现范围查询,还要支持高并发。这算是一道难题了。
插入一段内容,关于如果使用Sorted Set实现范围查找,就是sql中的大于等于and小于等于。(下面是我参考的一篇博客,我觉得他的实现有些鸡肋,完全可以用一条:zadd myset 1015 1011-1015-v1 替代两条记录)。
服务端对于客户端不同的版本区间会做些不同的配置,那么客户端一个版本过来怎么快速的定位是属于哪个版本区间呢?可以利用Sorted Sets的zrangebyscore命令。
zadd myset 1011 v1_start
zadd myset 1015 v1_end
zadd myset 1018 v2_start
zadd myset 1023 v2_end
如上我们像myset里插入了4条数据,代表的意思是版本区间v1是从1011-1015版本,版本区间v2是从1018-1023版本。
那么我现在如何判断1014版本属于哪个区间呢,使用zrangebyscore如下操作:
zrangebyscore myset 1014 +inf LIMIT 0 1
1)v1_end
返回v1_end说明1014属于版本区间1,上面的这个命令的意思是在myset中查找第一个score值大于等于1014的member,如果我们查找一个不在区间内的版本,比如1016:
zrangebyscore myset 1014 +inf LIMIT 0 1
1)v2_start
首先,我想到的是利用Redis的有序集合Sorted Set,存储每条记录的ip区间,或者叫ip范围。ip_to列作为有序集合的score。如:
zadd ip-country-city-locations-range 3756871679 3756871424~3756871679
这样就可以查询一个ip对应的score落在哪个区间,找出符合条件的第一个区间。如:
(1)将ip转为number,假设得到的值为:3756871650
(2)使用zrangebyscore命令获取所在区间
zrangebyscore ip-country-city-locations-range 3756871650 +inf 0 1
因为3756871650比3756871424~3756871679区间的end值3756871679小于等于,所以匹配到这条记录。但拿到这条记录后并不能说明3756871650在这个区间内,所以还要比较
3756871424<=3756871650<=3756871679
因为会存在这种情况,该区间与前一个区间并不是连续的,比如。
(1)3756870911=>3756870656~3756870911
(2)3756871679=>3756871424~3756871679
明显,这两个区间之间存在断层。但可以肯定的是,如果不落在区间(2)中,也不会落在区间(1)。所以不满足就可以直接返回null了。
// [0] <= midNumber <= [1]
if (midNumber.compareTo(Long.valueOf(rangeSn[0])) < 0
|| midNumber.compareTo(Long.valueOf(rangeSn[1])) > 0) {
return null;
}
Ip库用hash类型存储,field取ip_from或者ip_from&ip_to,value当然就是存完整的一行记录了。最后就可以根据拿到的区间信息获取到对应记录的field,使用hget命令就能获取到最终的一行ip信息记录。
hget ip-country-city-locations 3756871424
这并不难实现,但是,耗时却非常严重,可以看下官方文档介绍的Sorted Set的zrangebyscore的时间复杂度。IP库保守估计百万条记录,如果就这样上线,百分百又是服务雪崩。
改进思路:区间+Sorted Set
由于Sorted Set有序集合的查询时间复杂度是O(log(n)+m),其中n是总记录数,m是此次查询获取的记录数,在limit 0 1的情况下是O(log(n)),所以一个有序集合的元素个数越多,它的查询时间耗时越长。对于一般的应用场景,如排行榜,都是只有极少数的几百条记录。而如果用于ip库的区间查询实现,记录上百万条,而且还是用于高并发场景,不把服务搞垮才怪了。
既然我们要用Sorted Set,但又不能让集合的元素过大,那么我们可以分n/m个区间存储啊。假设有一百万条记录,每个Sorted Set存储1000条,那就用1000个Sorted Set集合来存储。hash的查询时间复杂度是接近O(1)的,增加1000个key在分槽位的分布式集群下根本不算什么。
按照上面的思路改进后,获取一个ip的国家城市信息就变成如下步骤:
1、根据ip计算出一个number值
比如:3756871650
2、根据区间大小(这一步的区间指的是每个Sorted Set的最大大小),计算出该number所在的集合的key
比如:ip-country-city-locations-range-375
3、根据这个key,去Sorted Set查询number所属的区间。
比如:zrangebyscore ip-country-city-locations-range 3756871650 +inf 0 1
4、拿到区间信息后,从区间信息获取ip范围位置信息的 field(hash类型存储)
比如查询结果区间信息为:3756871424~3756871679拿到field就是:3756871424
5、根据key和field拿到目标记录。
hget ip-country-city-locations 3756871424
编码实现
我将实现封装成一个组件,目的是对外提供更简单的使用方式,封装复杂的实现逻辑,同时,内部的改动对使用者无感知。通过SPI+分层设计,利用静态代理模式等,使得组件具有极强的扩展性,如果某天想改成使用mongodb或者内存缓存,只需要实现几个接口就可以了。
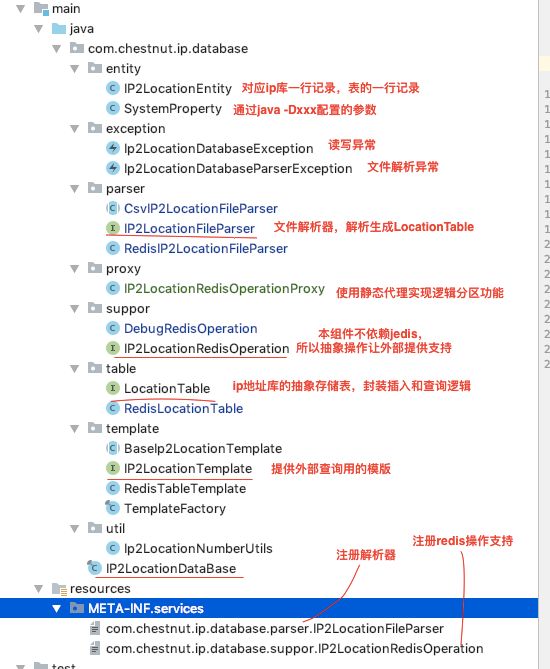
关于数据源表的初始化
使用需要配置update启动参数:
-Dip.database.table.update=true
如:
java -Xss256k -jar -Dip.database.table.update=true xxx-1.0.0.jar
true: 首次启动就会从指定的url文件读取解析记录,插入数据表
false: 表示已经确认表存在记录了,不需要再更新。(也不会去解析文件) 默认:false
解析记录与插入表是异步的,后台开启一个线程执行。耗时根据文件大小决定,我测的是86s
配置使用表
使用了java的SPI
需要指定使用哪个文件解析器,也就对应使用哪种类型的表
配置redis操作实现类
使用了java的SPI
如果解析配置使用了
com.chestnut.ip.database.parser.RedisIP2LocationFileParser
则需要自己实现RedisOperation,并在
com.chestnut.ip.database.suppor.IP2LocationRedisOperation
文件中配置redis操作的实现类
缓存的key
如果使用redis存储数据,则key固定为
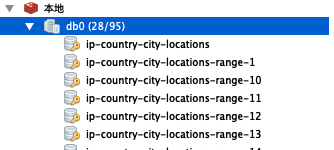
ip-country-city-locations // 存储真实记录ip-country-city-locations-range-* // 存储范围与真实记录的key的映射
其中ip-country-city-locations-range-后面的代表的分区索引。
本地测试性能
本地测试的数据并不理想,我4g内存的电脑本地开redis,一次都没写完过全部数据,都是写一半后不是redis挂就是测试程序挂。可以肯定的是总记录数是以千万为单位的。O(log(n千万/range))的时间复杂度,本地测的结果我并不满意,7ms的时间,太久了。这个数量级的数据,就算内存缓存也很花时间,因为并不是简单的key-value,涉及到范围查找。
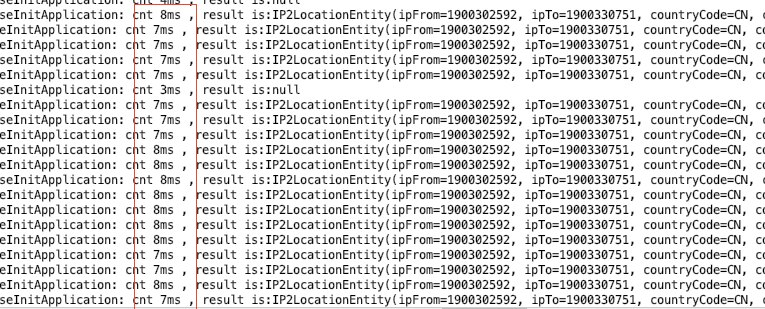
但实际线上测基本只需要1ms,下一篇讲解!