![]()
调研的目的/需求背景
在自定义k8s持久卷csi驱动,并将一个大的nfs文件系统分割成多个小的持久卷(PV)的背景下,如何解决每个持久卷只允许使用到卷的容量上限(例如50GB)是个待功克的技术难题。
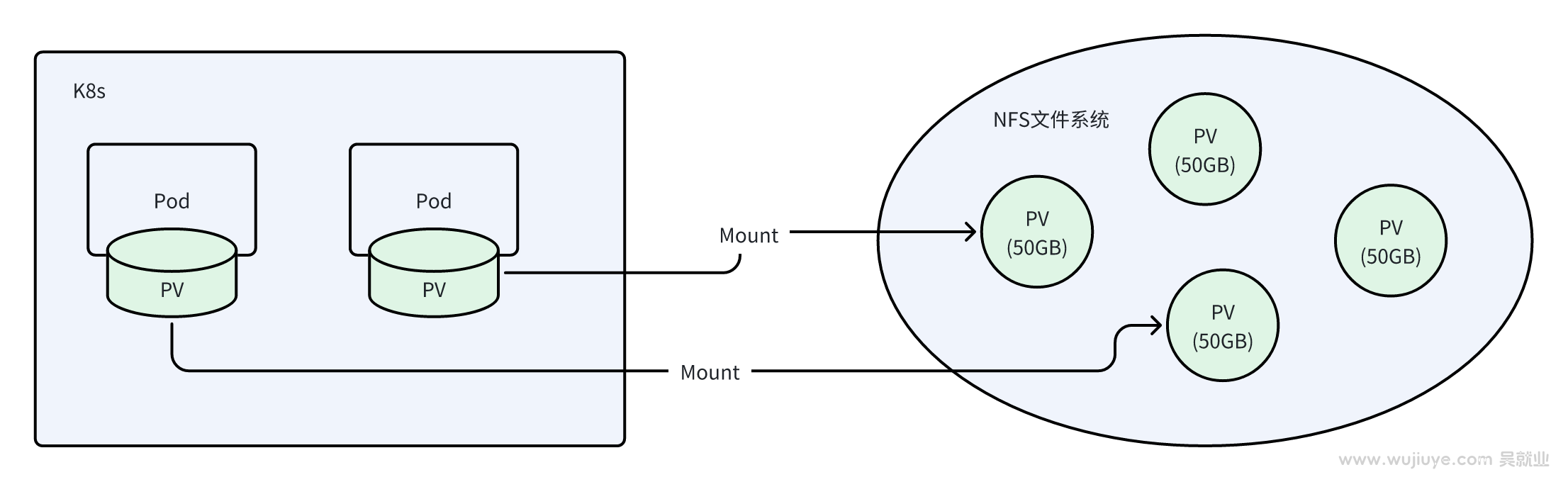
方案调研
方案一:eBPF拦截vfs_write
vfs_write是linux虚拟文件系统写操作的一个系统函数,所有对文件的写操作必然都经过这个系统函数。
eBPF可以在Linux操作系统内核中运行沙盒程序,用于安全有效地扩展内核的功能,在无需更改内核源代码或加载内核模块的情况下,能过插入我们的hook逻辑。
用于验证的demo案例:
//go:build ignore
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include <asm-generic/errno.h>
// ......
SEC("kprobe/vfs_write")
int kprobe_vfs_write(struct pt_regs *ctx) {
// .......
struct dir_cfg *value = bpf_map_lookup_elem(&dir_allow_write_map, &key);
if (value && value->disable == 1) {
bpf_printk("not allow write by root path = /%s\\n", root_path);
return -EPERM;
}
// ........
return 0;
}
char __license[] SEC("license") = "Dual MIT/GPL";
调研结论:我们无论reutrn -1还是0还是1,都无法阻止vfs_write的执行,原因是我们无法在eBPF程序中Blocking系统函数的调用。就好比AOP的逻辑只能打打日记。
方案二:eBPF+nfs协议拦截写操作
所有挂盘写操作,最终都是通过nfs协议走网络通信写到nfs文件系统,是否可以通过eBPF拦截网络出口流量数据包?然后根据nfs v3协议采用的rpc通信协议和xdr编解码协议来解码出nfs数据包,对写操作的数据包进行改写或丢包处理。
nfs协议:https://www.ietf.org/rfc/rfc1813.txt
Nfs的rpc通信协议:https://linux-nfs.org/wiki/index.php/NetworkTracing
通过tcpdump抓包分析后,发现写文件的流程是:
- 打开一个文件写:LOOKUP -> WRITE -> COMMIT
- 创建一个文件写:LOOKUP -> CREATE -> WRITE -> COMMIT
LOOPUP的过程是一步步获取文件句柄。
举例:假如我们需要打开/data/logs/log.txt文件写。
那么需要经过三次LOOPUP才能拿到要的的文件句柄,分别是:
- 调用LOOKUP查询.(当前)目录下的data目录,获取data目录的文件句柄。
- 调用LOOKUP查询data目录下的logs目录,获取logs目录的文件句柄。
- 调用LOOKUP查询logs目录下的log.txt文件的文件句柄。
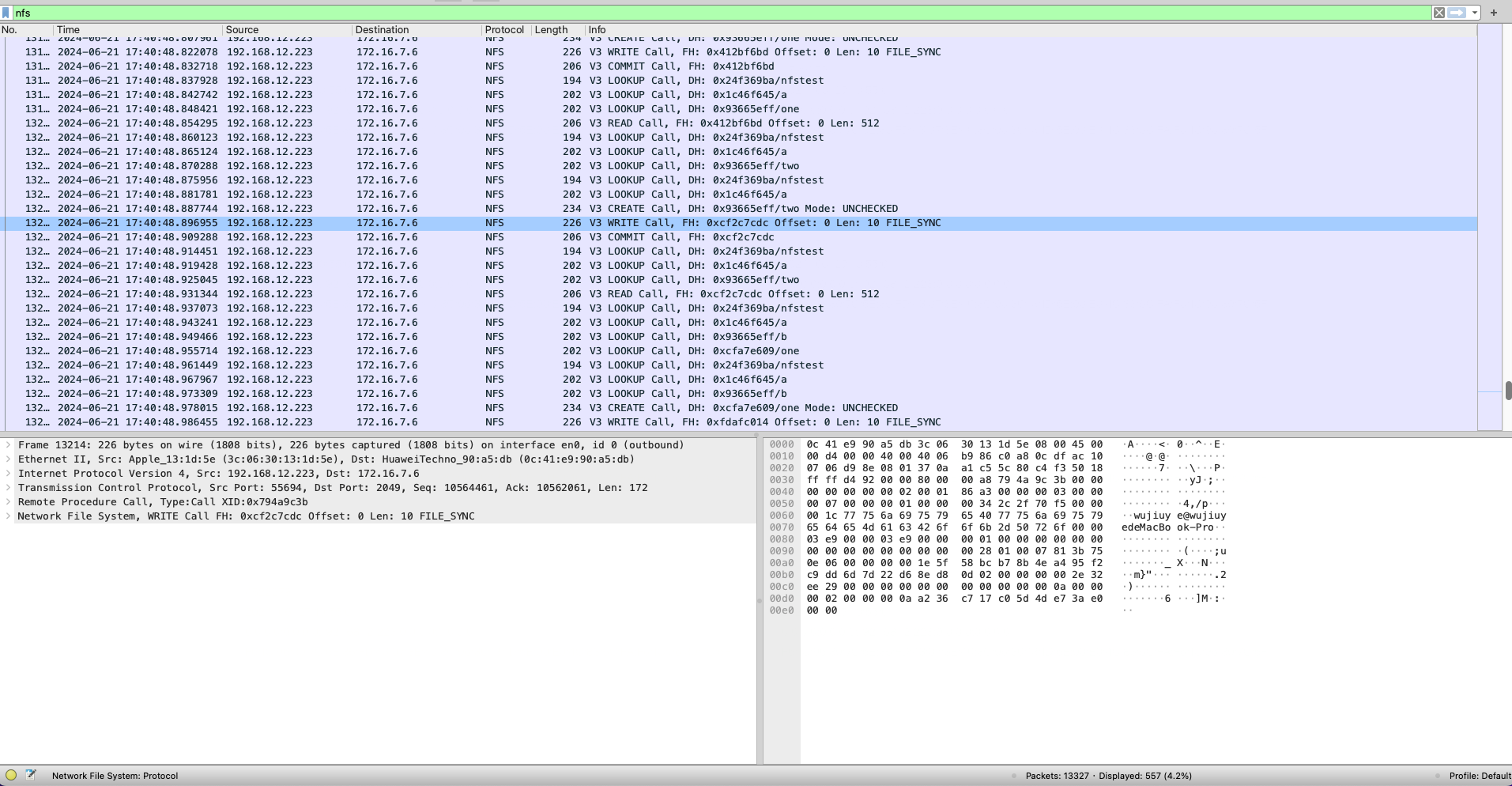
调研的结论:由于nfs协议我们只能拿到写文件的文件句柄,无法直接得出这个文件是哪个目录下的。想通过ebpf拦截nfs网络数据包来拦截写,因为要实现知道一个文件句柄是哪个目录下的,需要花很大的成本代价来缓存文件元数据信息,花大成本只为了实现实现一个拦截功能,这条路肯定也走不通。
方案三:eBPF xdp或tc直接匹配IP丢包
最坏的情况下,是否可以限制只允许一个pod挂一个pv(持久卷),我们能够通过IP协议层数据包获取源ip对应的pod,再查pod挂的pv,如果这个pv已经到了写入限制,那么就可以在ebpf拦截直接丢包。
由于eBPF xdp挂载点只能拦截入口网络数据包,也就是说,拦截write,实际已经调nfs服务器完成了写,只是拦截了响应,这可能会造成数据的不一致?
所以优先考虑了另一种方案,利用tc实现拦截出口流量并匹配源Pod ip丢包。tc是Traffic Control的缩写,即流量控制,是 Linux 内核中用于流量控制的一套功能强大的工具和框架、是内核的一个子系统。参考文献:[译\] 深入理解 tc ebpf 的 direct-action (da) 模式(2020)
该方案存在局限:tc不能控制nfs读写,也就是说,如果对某个pod丢包处理的话,会影响读和写。但正常来说,一个磁盘的用满,应该只能影响写入而不能影响读、也不能影响删除。
在k8s DemainSet pod上验证使用tc丢包方案的可行性,得出结论:由于pv是由csi驱动的node组件这个pod挂载的,只有这个pod安装了nfs的client,能够与nfs文件系统交互,然后node组件是将这个目录挂载到应用pod的挂载点而已,实际我们在应用pod往磁盘写数据,最终网络上是通过csi这个node组件的nfs client去写到nfs文件系统的。所以我们无法拦截应用Pod的,只能拦截csi node组件的pod。
即:所有基于IP的拦截方案都行不通。tc这个方案也走不通。
方案四:eBPF LSM拦截vfs_write
LSM是Linux Security Module的缩写,即Linux 安全模块,它是 Linux 内核的一个基于钩子的框架,用于在Linux内核中实现安全策略和强制访问控制。
Linux 5.7版本引入了eBPF LSM(简称LSM BPF)。eBPF LSM是LSM的一个扩展,允许开发者编写eBPF程序来定义和执行安全策略。
因为这个钩子允许我们返回非0以Blocking掉系统调用,所以可以用来实现拦截文件写入的需求。从vfs_write这个系统函数的源码我们找到了file_permission这个HOOK。
file_permission钩子用于在访问打开的文件之前检查文件权限,该钩子的定义如下:
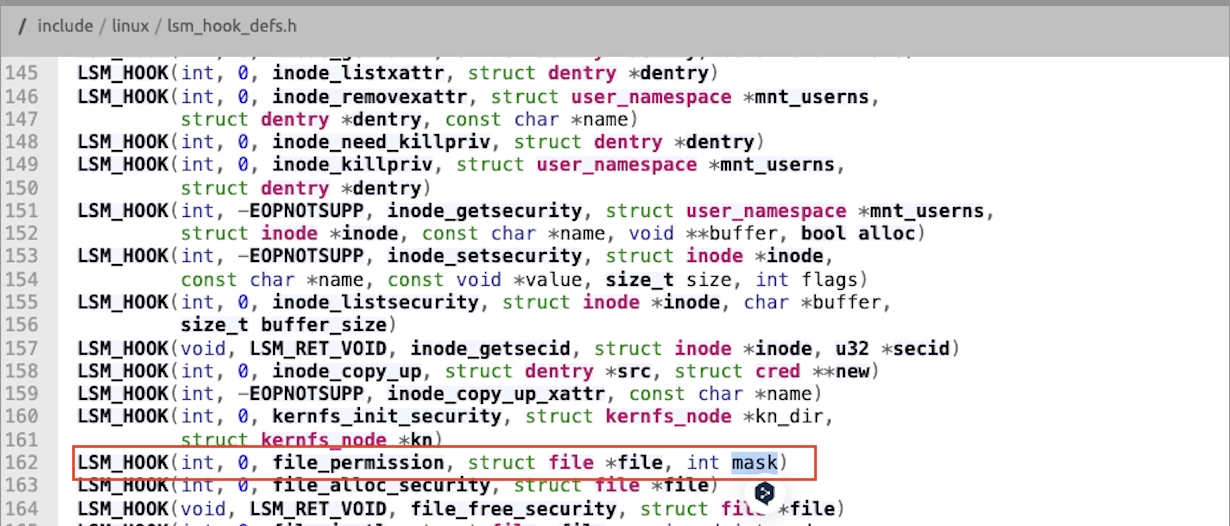
参数说明:
- @file 包含正在访问的文件结构。
- @mask 包含请求的权限。
- 如果权限被授权,返回0,否则返回其它。
但是vfs_read也调用这个hook,open等其它地方也会调用这个hook,需要能区分是哪个系统函数调用的,这个方案理论上才能跑通。
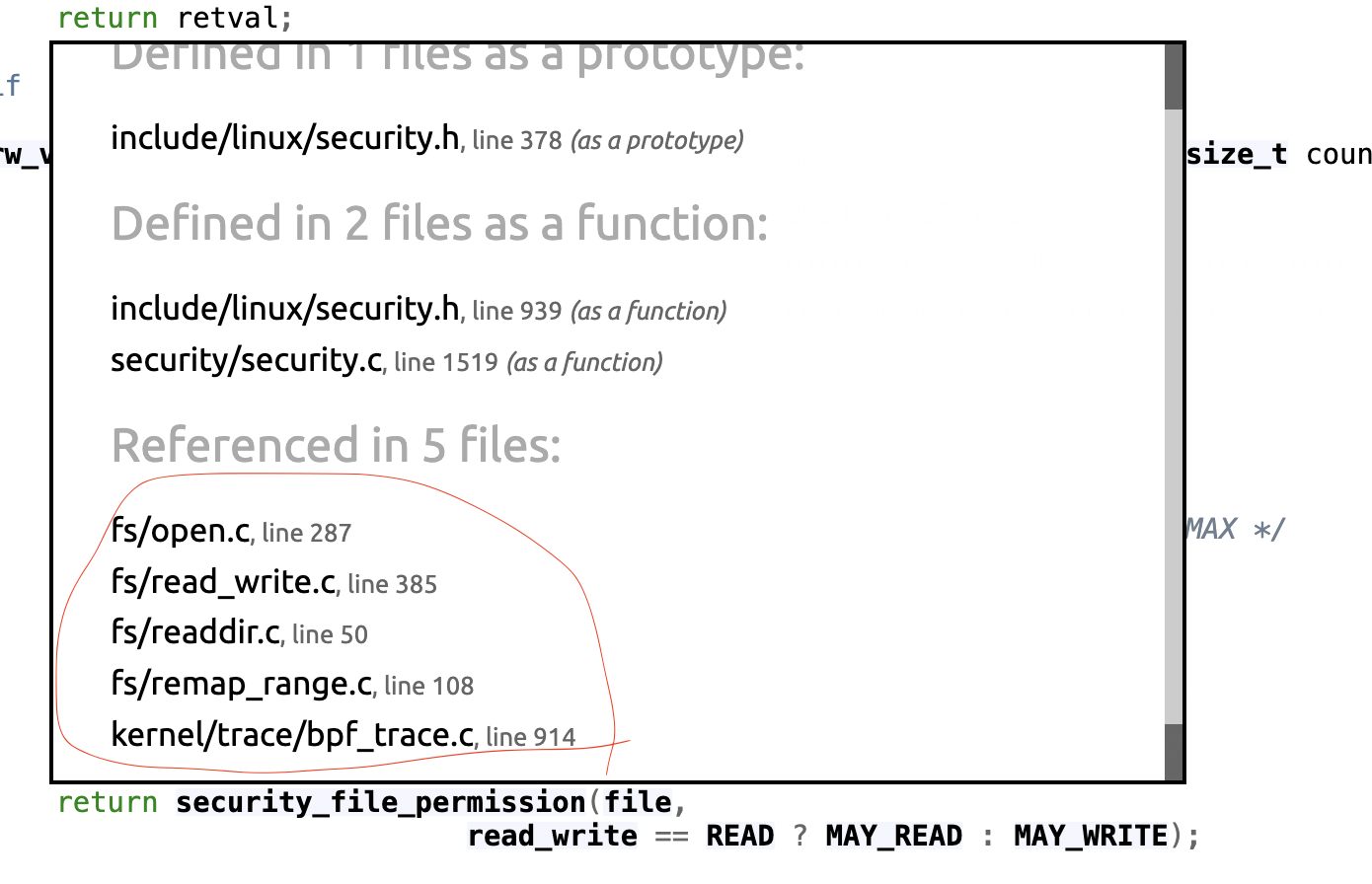
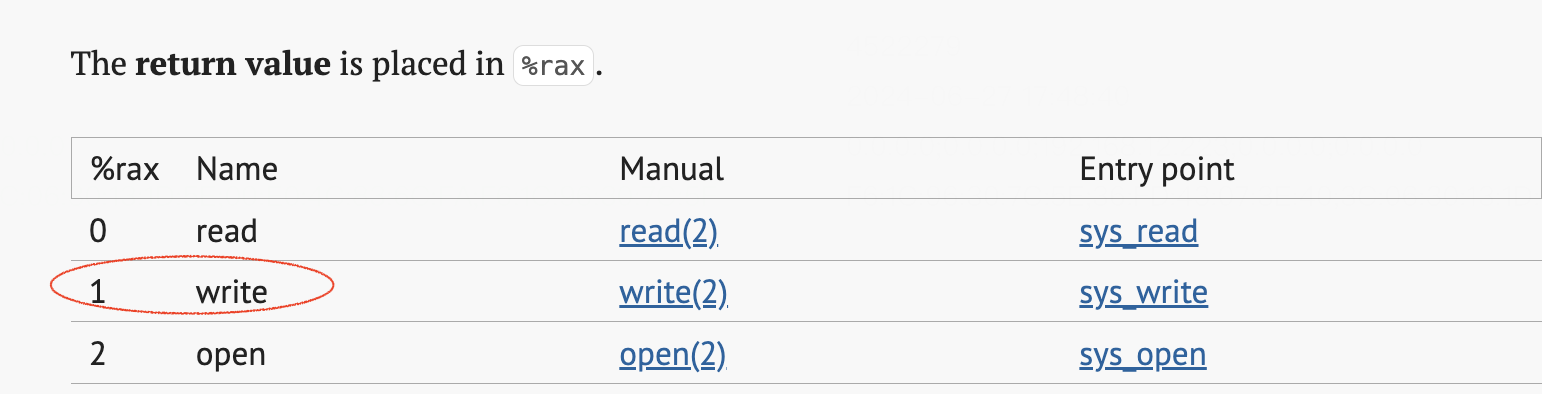
使用 eBPF Linux 安全模块实时修补 Linux 内核中的安全漏洞这篇文章介绍了可以从rax寄存器中拿到系统调用的编号。然后从Searchable Linux Syscall Table这篇文档找到了对应write系统调用的rax值 = 1。
用于验证的bpf代码:
//go:build ignore
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define X86_64_WRITE_SYSCALL 1
#define WRITE_SYSCALL X86_64_WRITE_SYSCALL
char __license[] SEC("license") = "Dual MIT/GPL";
SEC("lsm/file_permission")
int BPF_PROG(handle_file_permission,struct file *file, int mask, int ret) {
struct pt_regs *regs;
struct task_struct *task;
int syscall;
task = bpf_get_current_task_btf();
regs = (struct pt_regs *) bpf_task_pt_regs(task);
// In x86_64 orig_ax has the syscall interrupt stored here
syscall = regs->orig_ax;
if (syscall != WRITE_SYSCALL){
return 0;
}
// todo 实现根据文件路径返回-1
struct dentry *dentry = BPF_CORE_READ(&file->f_path,dentry);
const unsigned char *filename;
filename = BPF_CORE_READ(dentry,d_name.name);
char filename_str[256];
int name_len = bpf_probe_read_kernel_str(filename_str, sizeof(filename_str), filename);
// 简单判断先验证方案
if (name_len>8 && filename_str[0]=='t'&& filename_str[1]=='e') {
bpf_printk("block write...%s",filename_str);
return -1;
}
return 0;
}
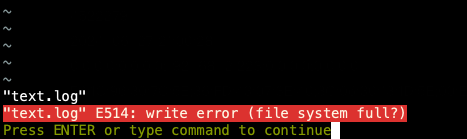
验证结果:
用vim写文件失败:
ebpf程序输出的日记:

调研结论
调研的几种方案,无论从性能还是可行性方面的考虑,采用eBPF LSM实现Blocking文件写操作都是最优的解决方案。
调研过程输出的相关文章