![]()
 故障排查与性能优化 专栏收录该内容,点击查看专栏更多内容
故障排查与性能优化 专栏收录该内容,点击查看专栏更多内容原创 吴就业 699 0 2024-02-29
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/4883fd5bbff84194954da6d6885bb7fb
作者:吴就业
链接:https://wujiuye.com/article/4883fd5bbff84194954da6d6885bb7fb
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
BPF是Berkeley Packet Filter的缩写,就是网络包过滤器,可以简单的理解为在系统内核插桩(hook),为我们提供了切面来实现过滤网络包的功能,可以类比Java Agent。BPF一开始出现的目的就是为UNIX内核实现一个网络包过滤器,我们熟悉的tcpdump命令就是基于BPF所实现。
eBPF,即extended BPF,扩展了BPF,不只是用于过滤网络数据包了,也不只有网络相关的探针(hook)。eBPF除了可以用于处理网络方面的问题,还可以用来实现方法调用追踪、监控系统性能,实时监视系统行为、安全审计。
bpftrace是降低eBPF的使用门槛,是一款基于eBPF之上的内核追踪排查工具。对于普通开发者来说,可以通过编写简单的脚本代码就能使用eBPF实现追踪功能。
安装很简单,如ubuntu下可以用apt-get install -y bpftrace安装。
执行命令验证是否成功:
bpftrace -e 'BEGIN{printf("Hello, World!\\n")}'
脚本格式:
/*采用与 C 语言类似的注释*/
BEGIN{
// 开始时执行一次的代码
}
probe/filter/ {
// 事件与 prob 和 filter 匹配时执行
}
END{
// 结束时执行
}
eBPF的运行基于内核的事件驱动,例如进入或退出某个函数的事件。我们编写的eBPF或者bpftrace程序将会被注入eBPF VM,告诉内核在发生指定事件时执行对应的代码。bpftrace通过过滤器+代码块的格式编写一个事件的处理逻辑,即:
probe/filter/ {
// 事件与 prob 和 filter 匹配时执行
}
而BEGIN和END是bpftrace额外提供的,用于执行一些与事件无关的逻辑,比如做一些初始化工作,或者结束时输出结果。这两个不是必须的。
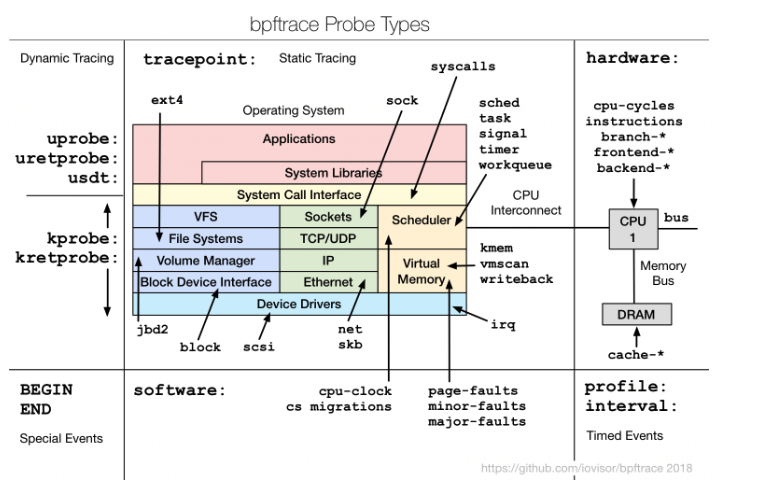
eBPF支持的探针有很多,主要分为三类:静态探针、动态内核探针、动态用户探针。
Tracepoint是内核开发人员在内核代码中留下的hook。可在/sys/kernel/debug/tracing/events/目录下查看当前版本的内核支持的所有Tracepoint。
内核动态探针可以分为两种:Kprobe和Kretprobe。Kprobe类型的探针用于跟踪内核函数调用,在内核函数被调用时插入相应的eBPF程序,而Kretprobe则在内核函数执行完毕返回之后,插入相应的eBPF程序。类似于我们实现Java Agent做全链路追踪,在方法的第一行代码之前和最后一行代码之后插入逻辑。
Kprobe和Kretprobe是用来跟踪底层内核的,要求开发者需要熟悉内核源代码,理解这些探针的参数、返回值的意义。
例如,tcp_connect是一个内核函数,当有TCP连接发生时将调用该函数,如果对tcp_connect使用Kprobe探针,则对应的eBPF程序会在tcp_connect被调用时执行,而如果是使用Kretprobe探针,则eBPF程序会在tcp_connect执行返回时执行。
实现与Kprobe/Kretprobe类似功能,支持对用户态程序进行追踪的机制。
Uprobe用于在用户空间程序的函数入口处设置断点,允许跟踪函数的调用,在函数入口处执行自定义的eBPF程序。而Uretprobe用于在用户空间函数返回前设置断点,允许在函数返回前执行自定义的eBPF程序。
一个统计read系统调用耗时的脚本案例:
#!/usr/bin/bpftrace
kprobe:vfs_read
{
@start[tid] = nsecs;
}
kretprobe:vfs_read
/@start[tid]/
{
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
}
kprobe:vfs_read即过滤内核vfs_read调用事件,{}内为处理逻辑。
kretprobe:vfs_read即过滤内核vfs_read函数返回事件,{}内为处理逻辑。
@用于声明使用脚本全局变量,变量可以当成map类型使用,如用例中@start[tid]=nesecs就是给全局变量start设置key-vlaue,tid和nsecs为pbftrace提供的内部变量,分别是线程id和当前时间戳(单位纳秒)。
$用于声明使用局部变量,在{}内可见。如用例中的$duration_us = (nsecs - @start[tid]) / 1000。
hist、delete为pbftrace提供的内部函数。
//用于添加过滤条件,如用例中的/@start[tid]/就是当start存在指定key的情况下,才执行{}内的逻辑。
所以,这个案例的用途是:在read函数调用之前,记录时间戳,在read函数return前计算方法执行耗时,将结果保存到us全局变量。
使用@声明的全局变量,会在bpftrace脚本进程结束时输出到控制台。
内置变量:
uid:用户id。
tid:线程id。
pid:进程id。
probe:当前的探针名称。
comm:进程名字。
nsecs:当前时间戳,单位纳秒。
kstack:内核级别的trace栈。
ustack:用户级别的trace栈。
curtask:当前进程的task_struct地址。
args:获取该kprobe或者tracepoint的参数列表
arg0:获取该kprobe的第一个变量,tracepoint不可用
arg1:获取该kprobe的第二个变量,tracepoint不可用
arg[n]:获取该kprobe的第n个变量,tracepoint不可用
retval: 函数返回值
内置函数:
count():获取事件总数
sum(x):对x求和
hist(x):x的二次幂直方图
delete(@x[key]):删除map变量的某个key
clear(@x):清空map变量
exit():退出bpftrace
printf("..."):打印字符串
system("..."):执行shell命令
cat(char *filename):打印文件内容
......
更多内置函数可查看原文:https://www.brendangregg.com/BPF/bpftrace-cheat-sheet.html
参考文献:
本文经「原本」原创认证,作者吴就业,访问yuanben.io查询【27890AZB】获取授权信息。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
借助eBPF,给vfs_write写操作挂个hook,可以用这个hook实现一些可观察需求。本案例仅供参考学习,可以把案例中的vfs_write改成其它的。
使用ebpf-go,假如bpf map的value需要用到结构体,而value由go程序写入,c程序读,value结构体在c中声明,那么怎么生成对应的go结构体呢?
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。