![]()
我们项目有个服务,使用基于Netty封装的实现HTTP协议的SNHEngine轻量级框架开发。SNH即Spring Boot + Netty + HTTP的意思。该框架是我开发的,取名有点随意,无妨。
SNHEngine借鉴了Spring MVC,完全可以像使用Spring MVC一样开发,目前支持的注解有@HttpController、@HttpGet、@HttpPost,比Spring MVC更轻量,更简洁。
本篇内容包括:
- 为何选择Netty
- 如何衡量一个服务的并发处理能力
- 业务代码调优
- 针对不同业务场景的高并发性能调优
与这篇“传统BIO网络编程知识点总结与Java NIO简介”是同一天写的。
为何选择Netty
先简单介绍下业务场景。作为一个广告系统,服务每天都需要处理几千万甚至上亿的点击广告请求,比如,推广一个Android应用,则用户点击广告会先跳转到我们的广告平台,做一些业务处理后,响应客户端302,重定向到GP。每天的请求量千万级别。
其实选择Netty是历史遗留问题,前辈开发的系统。我这次只是推翻前辈所写的代码,对项目做了重构。这次结合业务场景考虑,最终还是决定继续使用Netty。首先https使用aws的负载均衡器实现了,所以不需要考虑支持https协议,其实支持也并不能,按需加载就是Netty提供的特性。其次,我们并不需要考虑Session管理什么的。业务需求简单,复杂的只是业务逻辑。最主要的是Netty并没有让我失望。
如何衡量一个服务的并发处理能力
抛开TPS|QPS的那套计算公式,理论只是个经验值,基于此实现调整、优化。
本次以track服务为例,就是广告点击跳转服务,这是我的实战经历。track服务在优化之前,平均一个请求的处理耗时在6000ms左右,而优化后平均在20ms左右,一台2核4g的机器一分钟能抗下5w多的请求,并且5xx、4xx的数据量维持在十几个左右。之前需要三台机器抗下每天几千万的请求,现在只需要一台足以,这是在优化之前不可想象的。
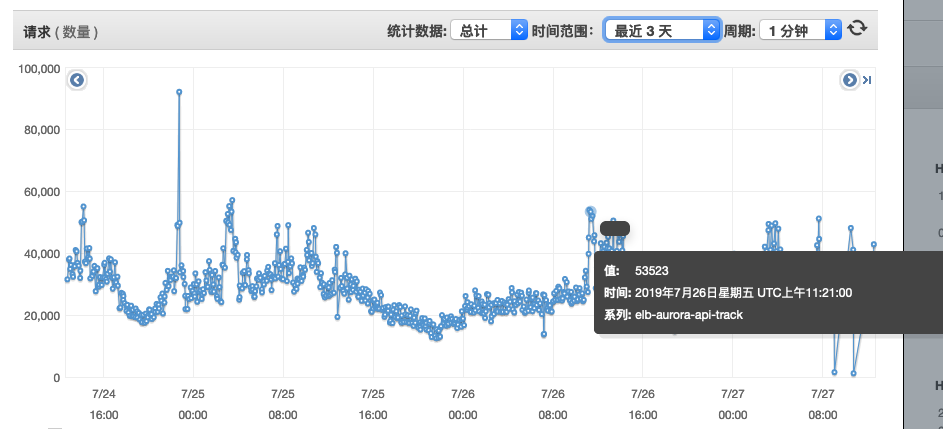
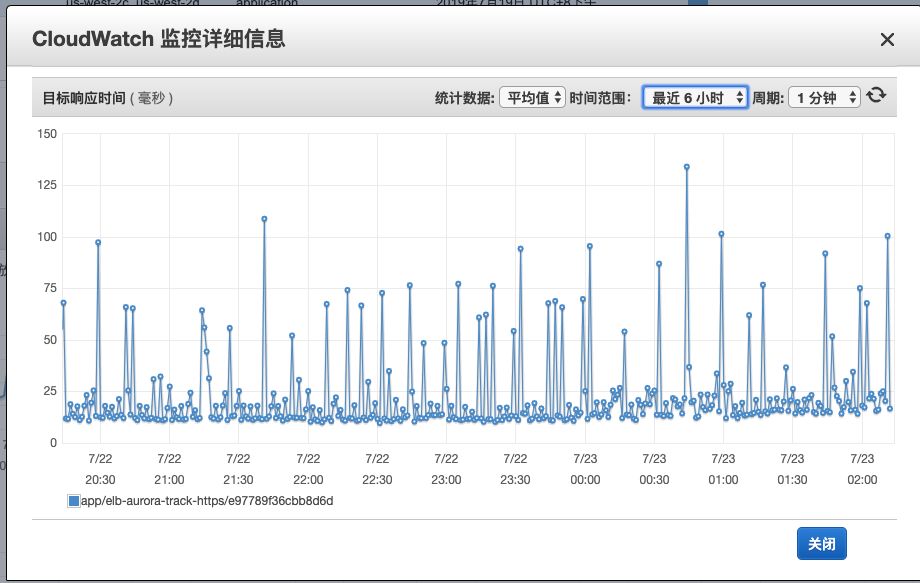
对于Track服务而言,不仅要求系统的吞吐量,更是对响应时间有着苛刻的要求。并发可以通过横向添加机器实现,当然,这也是要付出代价的。而响应时间与一次业务逻辑的执行时间挂钩,如果业务代码执行的时间长,那一次请求的响应时间必然会相对延长。
笔者的总结:一次请求所处理业务的时间,就是衡量一个服务单机所能处理的并发请求数的度量单位。在高并发场景下,请求的平均响应时间越接近一次业务处理的耗时,说明性能越好,反之则越差。
我在调优的过程中,观察到经过代码调优后每个请求的实际处理时间只需要8ms左右,所以我的目的就是让响应时间尽量的接近8ms。所以,高并发性能调优,首先要调的当然是业务代码,只有代码调优到不能再调优的程度,再考虑并发的优化,比如Netty线程数的设置、jvm的堆内存大小设置等。
当然,服务的并发处理能力,首先是受制于硬件,如处理器的核心数、内存、网络带宽,我们要做的只有榨干机器的性能,在有限的硬件资源上,提高服务的并发处理难力,这就是高并发性能调优的意义。抛开硬件之后,就是软件的并发处理能力,首先是框架的选型,其次是业务场景的考虑,业务代码的优化,线程数的设置。当优化到不能再优化的程度,随着并发量的增加,只能选择硬件上的优化,如提升机器的配置、添加机器。
为什么说track服务对响应时间有着苛刻的要求,我们先来理解下业务场景。
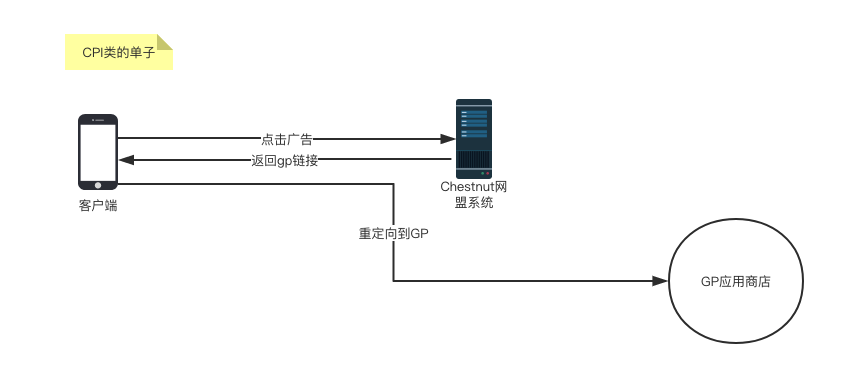
就以CPI类型的广告为例,比如现有一个游戏APP的广告,当用户点击广告时,会先跳转到我们的网盟广告系统,网盟广告系统的Track(点击)服务,需要做一些业务逻辑处理,处理完成后再返回GP链接给客户端。这里是302重定向,对用户无感知,浏览器会直接跳转到重定向后的地址,也就是GP应用商店。如果用户从点击广告到跳转到GP应用商店,超过了6s , 你觉得用户还会有耐心等吗?对电商而言,就是抹掉了用户对商品的购买欲。
业务代码调优
1、尽量不要把定时任务放到track服务,定时任务一多,必定会抢占CPU、内存等资源。
- 对于需要及时更新的配置,比如offer更新了状态,已经下线了,那么应该由更新offer状态的服务(比如管理后台)去更新到redis缓存,也可以使用消息中间件来解耦,由消息消费者统一去更新缓存。
- 避免大批量数据一同更新:比如一次性查全表更新数据到缓存,服务器的内存有限,一次性更新大批量数据会占用很大内存,这直接影响到jvm频繁触发Full GC,同时由于数据量大导致查询长时间占用I/O资源。
- 避免频繁更新改动少的数据:比如三分执行一次定时任务更新所有offer到缓存,这可能有好几万的offer,三分钟内估计只有那么十来个百来个offer发生改变,甚至是都没有改变。这不正是做无意义的劳动吗。
2、对大对象,尽量不走内存缓存,避免占用太多的内存。
JVM栈帧是线程私有的,方法、局部变量表、操作数栈都需要内存、线程内也会创建很多存放堆内存的对象,所以,线程数一增加,耗的内存也会增长,如果一个线程的完成一次事务所需要的内存大小是10M,那么想要100个线程并行,就需要1G的内存空间。如果创建1000个线程呢?由于线程的上下文切换会保存线程的状态,使其能在下一次获取执行的时候,能恢复状态信息继续执行,所以,即便是1000个线程有999个是WAIT状态,占用的内存也不会改变。
3、避免缓存穿透,尽可能的走缓存
能避免查库的操作,就不要查库。track服务在改造之前,存在很多这样的代码,当然,还有我曾经的手笔。看个栗子
String key = “xxx”+id;
Boolean isOpen = null;
If(cache.get(key)==null){
Boolean result = mapper.select();
cache.put(key,result);
cache.exp(1000000);// 设置过期
}
isOpen = cache.get(key);
这段代码正常来讲,确实是能提高性能,在过期时间内,只会有一次数据库的查询操作。但确有一个隐患,如果这个key在数据库中并没有记录,那岂不是每次都要走数据库查询一次?如果高并发下,存在很多这样的key呢?上千、上万,那不就是成千上万个请求同时都要执行查询操作?
4、反射带来的性能开销
我做过一组测试,对调用同一个类成员方法sayHello,直接使用反射获取Method调用,与先通过反射取得Method然后缓存,再调用。两者之间耗时相差约3倍。来看下代码。
/**
* @author wujiuye
* @version 1.0 on 2019/7/21 {描述:}
*/
@Slf4j
public class CacheMethodTest {
private static Method method;
public void sayHello() {
}
public static void main(String[] args) throws NoSuchMethodException {
method = CacheMethodTest.class.getDeclaredMethod("sayHello");
CacheMethodTest test = new CacheMethodTest();
for (int i = 0; i < 10; i++) {
t1(test);
// 大约相差3倍
t2(test);
}
}
private static void t1(CacheMethodTest test) {
long satrt = System.nanoTime();
try {
test.getClass().getMethod("sayHello").invoke(test);
log.info("t1 cnt {} ns", System.nanoTime() - satrt);
} catch (Exception e) {
}
}
private static void t2(CacheMethodTest test) {
long satrt = System.nanoTime();
try {
method.invoke(test);
log.info("t2 cnt {} ns", System.nanoTime() - satrt);
} catch (Exception e) {
}
}
}
虽然相差只在12000ns=0.012ms,但这仅仅只是一次反射带来的性能开销,如果业务中用到很多呢。比如下面的代码。
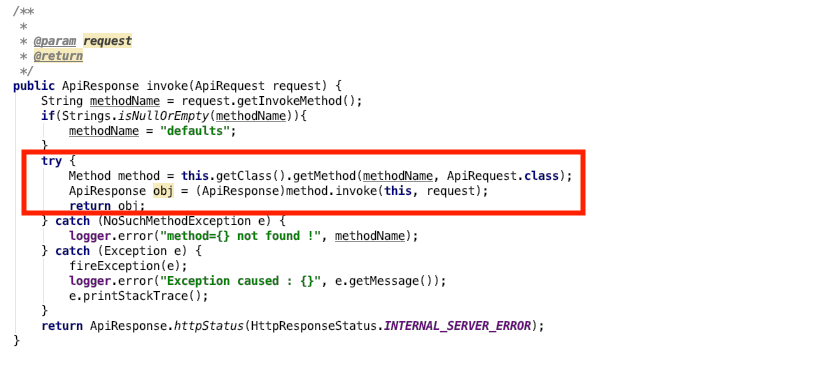
这是根据请求的url拿到目标方法名,然后通过反射获取目标Method,再使用反射调用执行,意味着每个http请求都会执行一遍。不过还好,我想要说的是,尽量不要大量去使用反射,比如对象的属性拷贝。对于上面的代码,我的优化方案是,参考Spring MVC的设计,只在应用初始化时调用反射一次,之后缓存Method。
@Controller(“user")
public class UserController{
@Post(“login")
public void doLogin(){
}
}
缓存类:
public class ControllerMethod{
String beanName;
Method method;
HttpMethod httpMethod; // GET|POST..
}
static finale Map<String,ControllerMethod> cacheControllerMethod = new xxxMap<>();
cacheControllerMethod的key对应的就是请求的路径,比如:“/user/login”,那么对应的value(ControllerMethod)就是beanName=“userController”,method=“doLogin()”,对应的httpMethod=“POST”。
5、局部无锁化
尽管jdk提供的锁已经优化到了极致,但资源竞争永远避免不了。所以无锁,总比有锁性能更优。局部无锁化,就是尽量让一次业务处理(一次请求)都在同一个线程内完成,尽量不要使用线程共享变量。对于贯穿整个请求上下文的变量,应用ThreadLocal来保存,避免经过层级很深的传递,并记得在请求结束后移除,使用需注意,用不好会导致内存泄漏。
针对不同业务场景的性能调优
Netty高并发性能调优包括:JVM性能调优、业务代码优化、针对不同业务场景的Netty性能调优。其中,JVM性能调优,无非就是配置足够大的堆内存,避免频繁发生Full GC。
JVM性能调优:
使用top命令可以看出,java进程实际使用的内存便大于-Xmx设置的最大堆内存。这是由于java进程所占用的实际内存= 本地内存+堆内存+元空间内存。jvm本身是由c写的,c程序运行需要向系统申请内存,线程栈也是使用直接内存,即线程栈所占的内存大小为线程数*线程栈最大大小。比如设置Xss256k,则200个线程使用200*256k的内存。还有就是Netty的读写缓存区使用的是堆外直接内存。
java程序刚开始运行时,堆内存并未使用满,随着程序的运行,内存使用越来越大,随后停留在一个稳定的值。这是由于堆的使用到达设置的最大堆大小。
Netty 的接收和发送 ByteBuf 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行 Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
之前出现过内存不够用导致服务挂掉的原因,机器只有4g内存,kinesis进程占用了256m,服务进程配置最大堆内存为3g,元空间占用20m,所以当并发连接数突然上涨时,Netty会对内存池进行动态扩容,导致服务挂机。如果并发请求数稳定,那么总的内存消耗会稳定在一个值。比如:我设置的最大堆内存为2g,最终会稳定在2.4g。
针对不同业务场景的Netty性能调优:
在此之前,服务器发生过一次文件句柄数达到上限的异常。但是服务器已经配置了最大打开文件句柄数为102400,这么大的数字,居然这么轻易就达到上限,显然是存在问题的。
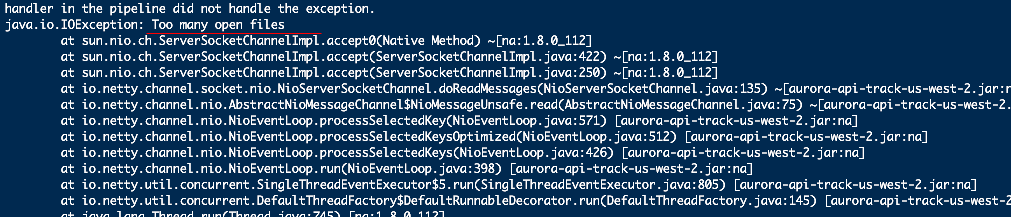

为什么会出现Too many open files异常。原因是 ,boss线程池接收了大量的连接请求,但是work线程池堵住了,得不到及时处理,一直积压,最后连redis也因此受牵连,导致服务直接瘫痪。原来work线程池并未配置线程数,而是使用默认的cpu核心数乘以2,对于2核4g的机器来说,work线程池的线程总数就是4。由于以前的业务逻辑实现简单,基本上一个请求过来,查询一遍redis,过滤一些条件,就完事的,所以以前不会出现这样的问题。但由于经手的人多了,后期添加的业务逻辑也多了,随着项目的发展,请求数也多了。代码中充满在线程内执行mysql查询的操作,各种缓存读写,还有调用其它服务的接口,所以并发的处理能力就直线下降。如果一次请求的耗时在6s左右,那么6s内,4个线程只能处理4个请求,这不就导致大批量请求被堵住了。再者,work线程是处理I/O读写的线程,业务处理越耗时,I/O读写阻塞越久,如读取客户端发送的消息。如果一开始能考虑到设置work的线程数,也就不需要买那么多台机器。
Work线程池的线程数配置多少合适?
如果业务执行时间长,可以适当增加work线程数,一般属于I/O型;如果业务逻辑简单,执行时间短,建议使用cpu核心数乘以2。实际的配置可以通过模拟并发测试来调整,比如使用Jmater,测出一个吞吐量最高、错误率最低、平均耗时最接近一次业务执行时间的线程数。
业务是否放在work线程中执行?
如果业务中必须包含数据库的查询操作,且比较耗时,就可以考虑将业务的执行从work线程分离到业务线程,而不是无线增大work线程。为什么说比较耗时的情况下,比如1s、2s,才将业务的执行从work线程分离。将work线程切换到业务线程执行,伴随着一次线程上下文的切换。其流程如下。
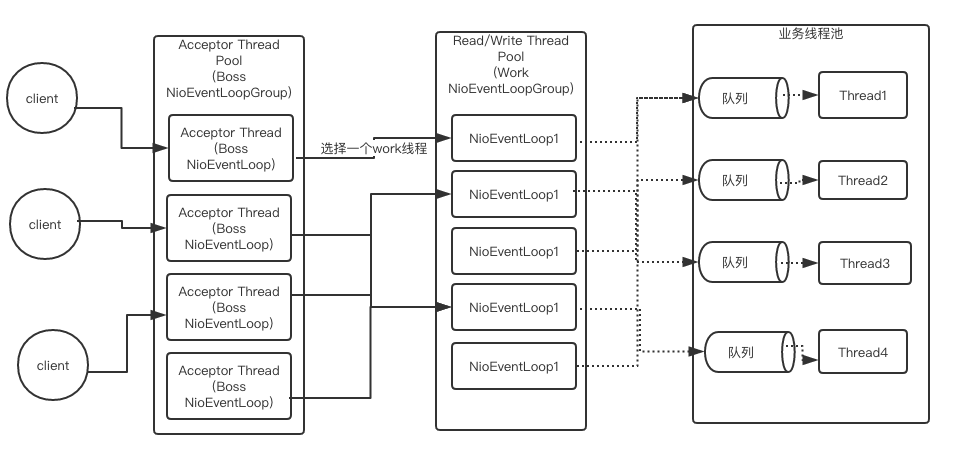
work线程处理消息的读写,包括根据协议编码解码、处理半包粘包等操作,而业务的处理则交给业务线程池,业务线程处理完成后work线程通过Future取得结果。work会先将task放入到任务队列,随后业务线程才会从队列中取得任务执行,业务线程池中的线程与队列是一对一的关系。所以,如果业务逻辑的执行耗时非常短,将业务逻辑放到业务线程池中执行,结果适得其反,得不到性能的提升,反而拖慢请求的响应时间。
将业务处理线程和Netty网络I/O线程分离策略的优点:
如果项目并非只有一个接口,而且实现的功能很复杂,如果某类业务(某个接口)处理较慢,阻塞 I/O 线程,就会导致其他处理较快的业务(其它接口)消息的响应无法及时发送出去。即便处理同一业务,使用同一个I/O线程同时处理业务逻辑和网络I/O读写,如果请求消息的业务逻辑处理较慢,同样会导致响应消息无法及时发送出去。所以,当业务处理比较耗时,或者项目提供的服务很复杂时,统一将业务处理从网络I/O线程分离到业务线程可以达到故障隔离的效果,提升并发性能。
使用长连接还是短连接呢:
对于长连接,我们需要配置心跳保活,当不再接收到客户端的心跳包时,释放连接,释放文件句柄。当然,这是对于非http请求而言,http的设置是无状态的,浏览器不会主动给服务器发送心跳包。那么,我们可以加入空闲检测机制,当客户端与服务端多长时间内,没有任何读写操作,则服务器主动关闭与客户端的连接,避免占着茅坑不xx。
什么情况下使用长连接?很简单,当服务器与客户端存在多次交流时,就应该保持长连接。比如,用户点击广告,通常情况下只会点击一次,那么就可以选择短连接。但,虽然用户只点击一次广告,不代表只发起一个http请求,如果用户使用的是浏览器点击,伴随着会有一次获取网站logo的请求。可以改用长连接,将空闲检测的时间缩短。这是我观察1分钟内,请求次数,与1分钟内,新建连接数得出的结论,我发现,新建连接数与请求数比例约为2:3。而最终我把短连接改为成连接后,性能确实有所提升,也就证实了我的想法。浏览器是支持http协议长连接的,只需要在响应头添加connection: keep-alive。
业务需求,对于服务之间的调用,以及与第三方服务器之间的通信,毫无疑问,保持长连接是最好的选择。