![]()
 深入理解Sentinel 专栏收录该内容,点击查看专栏更多内容
深入理解Sentinel 专栏收录该内容,点击查看专栏更多内容原创 吴就业 495 0 2020-09-22
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/d5113bcb35834db0bd60577276b7930c
作者:吴就业
链接:https://wujiuye.com/article/d5113bcb35834db0bd60577276b7930c
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
集群限流,我们可以结合令牌桶算法去思考,服务端负责生产令牌,客户端向服务端申请令牌,客户端只有申请到令牌时才能将请求放行,否则拒绝请求。
集群限流也支持热点参数限流,而实现原理大致相同,所以关于热点参数的集群限流将留给大家自己去研究。
sentinel-core模块的cluster包下定义了实现集群限流功能的相关接口:
TokenService接口的定义如下:
public interface TokenService {
TokenResult requestToken(Long ruleId, int acquireCount, boolean prioritized);
TokenResult requestParamToken(Long ruleId, int acquireCount, Collection<Object> params);
}
TokenResult实体类的定义如下:
public class TokenResult {
private Integer status;
private int remaining;
private int waitInMs;
private Map<String, String> attachments;
}
ClusterTokenClient接口定义如下:
public interface ClusterTokenClient extends TokenService {
void start() throws Exception;
void stop() throws Exception;
}
ClusterTokenClient接口定义启动和停止集群限流客户端的方法,负责维护客户端与服务端的连接。该接口还继承了TokenService,要求实现类必须要实现requestToken、requestParamToken方法,向远程服务端请求获取令牌。
ClusterTokenServer接口定义如下:
public interface ClusterTokenServer {
void start() throws Exception;
void stop() throws Exception;
}
ClusterTokenServer接口定义启动和停止集群限流客户端的方法,启动能够接收和响应客户端请求的网络通信服务端,根据接收的消费类型处理客户端的请求。
EmbeddedClusterTokenServer接口的定义如下:
public interface EmbeddedClusterTokenServer
extends ClusterTokenServer, TokenService {
}
EmbeddedClusterTokenServer接口继承ClusterTokenServer,并继承TokenService接口,即整合客户端和服务端的功能,为嵌入式模式提供支持。在嵌入式模式下,如果当前节点是集群限流服务端,那就没有必要发起网络请求。
这些接口以及默认实现类的关系如下图所示。
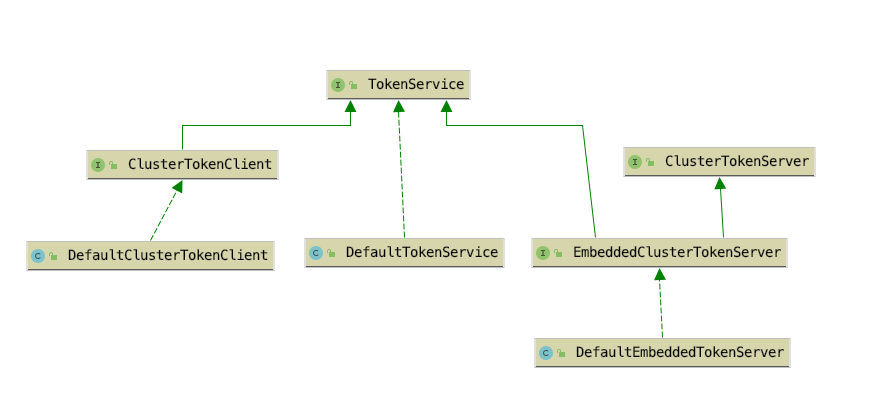
其中DefaultClusterTokenClient是sentinel-cluster-client-default模块中的ClusterTokenClient接口实现类,DefaultTokenService与DefaultEmbeddedTokenServer分别是sentinel-cluster-server-default模块中的ClusterTokenServer接口与EmbeddedClusterTokenServer接口的实现类。
当使用嵌入模式启用集群限流服务端时,使用的是EmbeddedClusterTokenServer,否则使用ClusterTokenServer,通过Java SPI实现。
我们接着单机限流工作流程分析集群限流功能的实现,从FlowRuleChecker#passClusterCheck方法开始,该方法源码如下。
private static boolean passClusterCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,boolean prioritized) {
try {
// (1)
TokenService clusterService = pickClusterService();
if (clusterService == null) {
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
// (2)
long flowId = rule.getClusterConfig().getFlowId();
// (3)
TokenResult result = clusterService.requestToken(flowId, acquireCount, prioritized);
return applyTokenResult(result, rule, context, node, acquireCount, prioritized);
} catch (Throwable ex) {
RecordLog.warn("[FlowRuleChecker] Request cluster token unexpected failed", ex);
}
// (4)
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
整体流程分为:
pickClusterService方法实现根据节点当前角色获取TokenService实例。如果当前节点是集群限流客户端角色,则获取ClusterTokenClient实例,如果当前节点是集群限流服务端角色(嵌入模式),则获取EmbeddedClusterTokenServer实例,代码如下。
private static TokenService pickClusterService() {
// 客户端角色
if (ClusterStateManager.isClient()) {
return TokenClientProvider.getClient();
}
// 服务端角色(嵌入模式)
if (ClusterStateManager.isServer()) {
return EmbeddedClusterTokenServerProvider.getServer();
}
return null;
}
ClusterTokenClient和EmbeddedClusterTokenServer都继承TokenService,区别在于,ClusterTokenClient实现类实现requestToken方法是向服务端发起请求,而EmbeddedClusterTokenServer实现类实现requestToken方法不需要发起远程调用,因为自身就是服务端。
在拿到TokenService后,调用TokenService#requestToken方法请求获取token。如果当前节点角色是集群限流客户端,那么这一步骤就是将方法参数构造为请求数据包,向集群限流服务端发起请求,并同步等待获取服务端的响应结果。关于网络通信这块,因为不是专栏的重点,所以我们不展开分析。
applyTokenResult方法源码如下:
private static boolean applyTokenResult(/*@NonNull*/ TokenResult result, FlowRule rule, Context context,
DefaultNode node,
int acquireCount, boolean prioritized) {
switch (result.getStatus()) {
case TokenResultStatus.OK:
return true;
case TokenResultStatus.SHOULD_WAIT:
try {
Thread.sleep(result.getWaitInMs());
} catch (InterruptedException e) {
}
return true;
case TokenResultStatus.NO_RULE_EXISTS:
case TokenResultStatus.BAD_REQUEST:
case TokenResultStatus.FAIL:
case TokenResultStatus.TOO_MANY_REQUEST:
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
case TokenResultStatus.BLOCKED:
default:
return false;
}
}
applyTokenResult方法根据响应状态码决定是否拒绝当前请求:
在请求异常或者服务端响应异常的情况下,都会走fallbackToLocalOrPass方法,该方法源码如下。
private static boolean fallbackToLocalOrPass(FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) {
if (rule.getClusterConfig().isFallbackToLocalWhenFail()) {
return passLocalCheck(rule, context, node, acquireCount, prioritized);
} else {
// The rule won't be activated, just pass.
return true;
}
}
fallbackToLocalOrPass方法根据规则配置的fallbackToLocalWhenFail决定是否回退为本地限流,如果fallbackToLocalWhenFail配置为false,将会导致客户端在与服务端失联的情况下拒绝所有流量。fallbackToLocalWhenFail默认值为true,建议不要修改为false,我们应当确保服务的可用性,再确保集群限流的准确性。
由于网络延迟的存在,Sentinel集群限流并未实现匀速排队流量效果控制,也没有支持冷启动,而只支持直接拒绝请求的流控效果。响应状态码SHOULD_WAIT并非用于实现匀速限流,而是用于实现具有优先级的请求在达到限流阈值的情况下,可试着占据下一个时间窗口的pass指标,如果抢占成功,则告诉限流客户端,当前请求需要休眠等待下个时间窗口的到来才可以通过。Sentinel使用提前申请在未来时间通过的方式实现优先级语意。
在集群限流服务端接收到客户端发来的requestToken请求时,或者嵌入模式自己向自己发起请求,最终都会交给DefaultTokenService处理。DefaultTokenService实现的requestToken方法源码如下。
@Override
public TokenResult requestToken(Long ruleId, int acquireCount, boolean prioritized) {
// 验证规则是否存在
if (notValidRequest(ruleId, acquireCount)) {
return badRequest();
}
// (1)
FlowRule rule = ClusterFlowRuleManager.getFlowRuleById(ruleId);
if (rule == null) {
return new TokenResult(TokenResultStatus.NO_RULE_EXISTS);
}
// (2)
return ClusterFlowChecker.acquireClusterToken(rule, acquireCount, prioritized);
}
由于ClusterFlowChecker#acquireClusterToken方法源码太多,我们将acquireClusterToken拆分为四个部分分析。
第一个部分代码如下:
static TokenResult acquireClusterToken(FlowRule rule, int acquireCount, boolean prioritized) {
Long id = rule.getClusterConfig().getFlowId();
// (1)
if (!allowProceed(id)) {
return new TokenResult(TokenResultStatus.TOO_MANY_REQUEST);
}
// (2)
ClusterMetric metric = ClusterMetricStatistics.getMetric(id);
if (metric == null) {
return new TokenResult(TokenResultStatus.FAIL);
}
// (3)
double latestQps = metric.getAvg(ClusterFlowEvent.PASS);
double globalThreshold = calcGlobalThreshold(rule) * ClusterServerConfigManager.getExceedCount();
double nextRemaining = globalThreshold - latestQps - acquireCount;
if (nextRemaining >= 0) {
// 第二部分代码
} else {
if (prioritized) {
// 第三部分代码
}
// 第四部分代码
}
}
ServerFlowConfig serverFlowConfig = new ServerFlowConfig();
serverFlowConfig.setMaxAllowedQps(1000);
ClusterServerConfigManager.loadFlowConfig("serviceA",serverFlowConfig);
(2)、获取规则的指标数据统计滑动窗口,如果不存在则响应FAIL状态码;
(3)、计算每秒平均被放行请求数、集群限流阈值、剩余可用令牌数量;
计算集群限流阈值需根据规则配置的阈值类型计算,calcGlobalThreshold方法的源码如下。
private static double calcGlobalThreshold(FlowRule rule) {
double count = rule.getCount();
switch (rule.getClusterConfig().getThresholdType()) {
case ClusterRuleConstant.FLOW_THRESHOLD_GLOBAL:
return count;
case ClusterRuleConstant.FLOW_THRESHOLD_AVG_LOCAL:
default:
int connectedCount = ClusterFlowRuleManager.getConnectedCount(rule.getClusterConfig().getFlowId());
return count * connectedCount;
}
}
当阈值类型为集群总QPS时,直接使用限流规则的阈值(count);
当阈值类型为单机均摊时,根据规则ID获取当前连接的客户端总数,将当前连接的客户端总数乘以限流规则的阈值(count)作为集群总QPS阈值;
这正是客户端在连接上服务端时,发送PING类型消费给服务端,并将名称空间携带在PING数据包上传递给服务端的原因。在限流规则的阈值为单机均摊阈值类型时,需要知道哪些连接是与限流规则所属名称空间相同,如果客户端不传递名称空间给服务端,那么,在单机均摊阈值类型情况下,计算出来的集群总QPS限流阈值将为0,导致所有请求都会被限流。这是我们在使用集群限流功能时特别需要注意的。
集群限流阈值根据规则配置的阈值、阈值类型计算得到,每秒平均被放行请求数可从滑动窗口取得,而剩余可用令牌数(nextRemaining)等于集群QPS阈值减去当前时间窗口已经放行的请求数,再减去当前请求预占用的acquireCount。
第二部分代码如下 :
metric.add(ClusterFlowEvent.PASS, acquireCount);
metric.add(ClusterFlowEvent.PASS_REQUEST, 1);
if (prioritized) {
metric.add(ClusterFlowEvent.OCCUPIED_PASS, acquireCount);
}
return new TokenResult(TokenResultStatus.OK).setRemaining((int) nextRemaining).setWaitInMs(0);
当nextRemaining计算结果大于等于0时,执行这部分代码,先记录当前请求被放行,而后响应状态码OK给客户端。
第三部分代码如下:
double occupyAvg = metric.getAvg(ClusterFlowEvent.WAITING);
if (occupyAvg <= ClusterServerConfigManager.getMaxOccupyRatio() * globalThreshold) {
int waitInMs = metric.tryOccupyNext(ClusterFlowEvent.PASS, acquireCount, globalThreshold);
if (waitInMs > 0) {
return new TokenResult(TokenResultStatus.SHOULD_WAIT)
.setRemaining(0).setWaitInMs(waitInMs);
}
}
当nextRemaining计算结果小于0时,如果当前请求具有优先级,则执行这部分逻辑。计算是否可占用下个时间窗口的pass指标,如果允许,则告诉客户端,当前请求可放行,但需要等待waitInMs(一个窗口时间大小)毫秒之后才可放行。
如果请求可占用下一个时间窗口的pass指标,那么下一个时间窗口的pass指标也需要加上这些提前占用的请求总数,将会影响下一个时间窗口可通过的请求总数。
第四部分代码如下:
metric.add(ClusterFlowEvent.BLOCK, acquireCount);
metric.add(ClusterFlowEvent.BLOCK_REQUEST, 1);
if (prioritized) {
metric.add(ClusterFlowEvent.OCCUPIED_BLOCK, acquireCount);
}
return blockedResult();
当nextRemaining大于0,且无优先级权限时,直接拒绝请求,记录当前请求被Block。
集群限流使用的滑动窗口并非sentinel-core模块下实现的滑动窗口,而是sentinel-cluster-server-default模块自己实现的滑动窗口。
ClusterFlowConfig的sampleCount与windowIntervalMs这两个配置项正是用于为集群限流规则创建统计指标数据的滑动窗口,在加载集群限流规则时创建。如下源码所示。
private static void applyClusterFlowRule(List<FlowRule> list, /*@Valid*/ String namespace) {
......
for (FlowRule rule : list) {
if (!rule.isClusterMode()) {
continue;
}
........
ClusterFlowConfig clusterConfig = rule.getClusterConfig();
.......
// 如果不存在,则为规则创建ClusterMetric,用于统计指标数据
ClusterMetricStatistics.putMetricIfAbsent(flowId,
new ClusterMetric(clusterConfig.getSampleCount(),
clusterConfig.getWindowIntervalMs()));
}
// 移除不再使用的 ClusterMetric
clearAndResetRulesConditional(namespace, new Predicate<Long>() {
@Override
public boolean test(Long flowId) {
return !ruleMap.containsKey(flowId);
}
});
FLOW_RULES.putAll(ruleMap);
NAMESPACE_FLOW_ID_MAP.put(namespace, flowIdSet);
}
实现集群限流需要收集的指标数据有以下几种:
public enum ClusterFlowEvent {
PASS,
BLOCK,
PASS_REQUEST,
BLOCK_REQUEST,
OCCUPIED_PASS,
OCCUPIED_BLOCK,
WAITING
}
除统计的指标项与sentinel-core包下实现的滑动窗口统计的指标项有些区别外,实现方式都一致。
集群限流服务端允许嵌入应用服务启动,也可作为独立应用启动。嵌入模式适用于单个微服务应用的集群内部实现集群限流,独立模式适用于多个微服务应用共享同一个集群限流服务端场景,独立模式不会影响应用性能,而嵌入模式对应用性能会有所影响。
集群限流客户端需指定名称空间,默认会使用main方法所在类的全类名作为名称空间。在客户端连接到服务端时,客户端会立即向服务端发送一条PING消息,并在PING消息携带名称空间给服务端。
集群限流规则的阈值类型支持单机均摊和集群总QPS两种类型,如果是单机均摊阈值类型,集群限流服务端需根据限流规则的名称空间,获取该名称空间当前所有的客户端连接,将连接总数乘以规则配置的阈值作为集群的总QPS阈值。
集群限流支持按名称空间全局限流,无视规则,只要是同一名称空间的客户端发来的requestToken请求,都先按名称空间阈值过滤。但并没有特别实用的场景,因此官方文档也并未介绍此特性。
建议按应用区分名称空间,而不是整个项目的所有微服务项目都使用同一个名称空间,因为在规则阈值类型为单机均摊阈值类型的情况下,获取与规则所属名称空间相同的客户端连接数作为客户端总数,如果不是同一个应用,就会导致获取到的客户端总数是整个项目所有微服务应用集群的客户端总数,限流就会出问题。
集群限流并非解决请求倾斜问题,在请求倾斜严重的情况下,集群限流可能会导致某些节点的流量过高,导致系统的负载过高,这时就需要使用系统自适应限流、熔断降级作为兜底解决方案。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
本篇内容介绍如何使用r2dbc-mysql驱动程序包与mysql数据库建立连接、使用r2dbc-pool获取数据库连接、Spring-Data-R2DBC增删改查API、事务的使用,以及R2DBC Repository。
消息推送服务主要是处理同步给用户推送短信通知或是异步推送短信通知、微信模板消息通知等。本篇介绍如何使用Spring WebFlux + R2DBC搭建消息推送服务。
IDEA有着极强的扩展功能,它提供插件扩展支持,让开发者能够参与到IDEA生态建设中,为更多开发者提供便利、提高开发效率。我们常用的插件有Lombok、Mybatis插件,这些插件都大大提高了我们的开发效率。即便IDEA功能已经很强大,并且也已有很多的插件,但也不可能面面俱到,有时候我们需要自给自足。
Instrumentation之所以难驾驭,在于需要了解Java类加载机制以及字节码,一不小心就能遇到各种陌生的Exception。笔者在实现Java探针时就踩过不少坑,其中一类就是类加载相关的问题,也是本篇所要跟大家分享的。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。