![]()
 Spring Cloud Kubernetes微服务实战与源码分析 专栏收录该内容,点击查看专栏更多内容
Spring Cloud Kubernetes微服务实战与源码分析 专栏收录该内容,点击查看专栏更多内容原创 吴就业 514 0 2020-06-09
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/9f1bb4455b7542579c639d4d52f68910
作者:吴就业
链接:https://wujiuye.com/article/9f1bb4455b7542579c639d4d52f68910
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
本篇文章写于2020年06月09日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
Docker与Kubernetes是什么关系?这可能是我们刚接触Kubernetes时都有的一个疑问。那么Kubernetes是什么?
Kubernetes是一个容器集群编排管理系统,用于实现容器集群的自动化部署、自动扩缩容等功能。Docker提供用于运行应用程序的容器技术,而Kubernetes本身并不提供用于运行应用程序的容器,而是负责管理容器。
了解Docker与Kubernetes的关系之后,就能理解为什么我们要先学习Docker再学习Kubernetes,这与先学习Spring框架才能更好地学习Spring Boot、Spring Cloud是一样的。
作为开发,我们为什么要了解容器技术,这不是运维该学习的吗?作为开发者,只有足够了解容器技术,才能做好技术选型,以及开发部署在Kubernetes容器服务之上的应用应该要注意哪些问题。如果运维不了解代码,开发也不了解Kubernetes,谁能解决将服务迁移到Kubernetes上遇到的各种问题呢?
Kubernetes笔者学习Kubernetes的路线,分享给大家:
* 官方学习文档:http://docs.kubernetes.org.cn/
* 阅读书籍:《Kubernetes in Action中文版》
* 极客时间视频教程:《Spring Cloud与Kubernetes云原生微服务实战》
学习Kubernetes首先要了解Kubernetes的架构,了解一些“概念”,再了解常用的几种资源。资源,对初学者来说是最难理解的,因此推荐大家阅读《Kubernetes in Action中文版》这本书,跟着例子一步步掌握常用的几种资源的使用,如:Deployment、Service、ConfigMap、Secret。
Kubernetes管理所有可用的物理机,以阿里云容器服务Kubernetes为例,Kubernetes负责管理一堆ECS实例,这需要我们在创建Kubernetes集群时,购买足够的ECS实例,至少两台。后续也可将新购买的ECS实例加到Kubernetes集群,由Kubernetes管理。
开发者和运维都不需要知道一个应用程序部署在哪个ECS实例上,只需要指定运行应用程序所需要的cpu、内存等资源,Kubernetes会根据要求计算出满足条件的节点(ECS),并在节点(ECS)上从镜像仓库拉取应用程序的镜像创建容器并运行容器,并且监控容器的整个生命周期。我们可以把Kubernetes管理的所有节点(ECS)看成一个大的物理机,这台大的物理机的cpu、内存是所有节点(ECS)的总和。
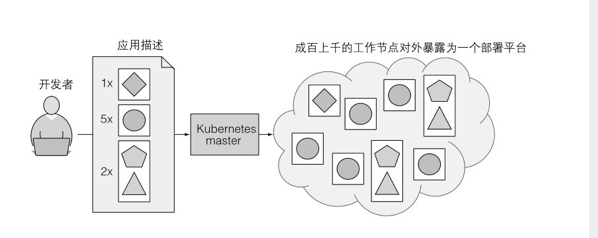
(图片来自《Kubernetes in Action》)
如上图所示,开发者只需要将应用构造成镜像,并将镜像push到远程镜像仓库,然后编写一个Deployment资源文件,在资源文件中描述应用程序的镜像和运行所需要的cpu、内存等,使用kubectl apply -f 此Deployment资源文件名就能将应用程序部署到Kubernetes。
Kubernetes由两种类型的节点组成。
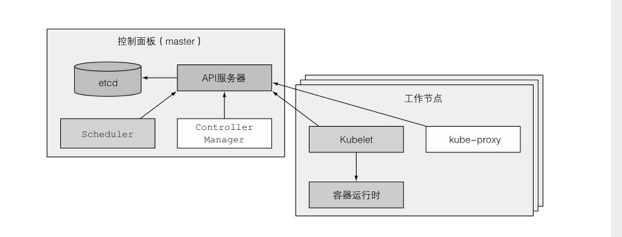
(图片来自《Kubernetes in Action》)
一种是主节点Master,负责控制和管理整个集群,为实现高可用,主节点也要求部署集群。主节点上会部署一些组件,这些组件可以运行在单个主节点上,或者通过副本分别部署在多个主节点上,实现高可用。如基于Raft协议实现的数据强一致性存储服务etcd、提供给我们使用的Kubernetes API服务、调度应用部署的Scheculer组件、执行集群功能的Controller Manager组件。这些组件我们可以先这么简单了解,暂时不用过于深究。
另一种是工作节点,运行用户实际部署的应用。
假设我们在阿里云购买了托管的Kubernetes服务,那么主节点就由阿里云托管,而工作节点就是我们购买的ECS实例,一个集群中有多少个ECS实例就是有多少个工作节点。
工作节点就是运行容器的机器,除了运行用于运行我们部署的应用程序的容器外,每个工作节点上还会运行一些组件,这些组件负责运行、监控和管理应用服务。如Docker、Kubelet、Kube-proxy。Docker我们已经很熟悉了;Kubelet负责与主节点的Kubernetes API服务通信,并管理它所在的工作节点的容器;Kube-proxy负责组件之间的负载均衡网络流量。
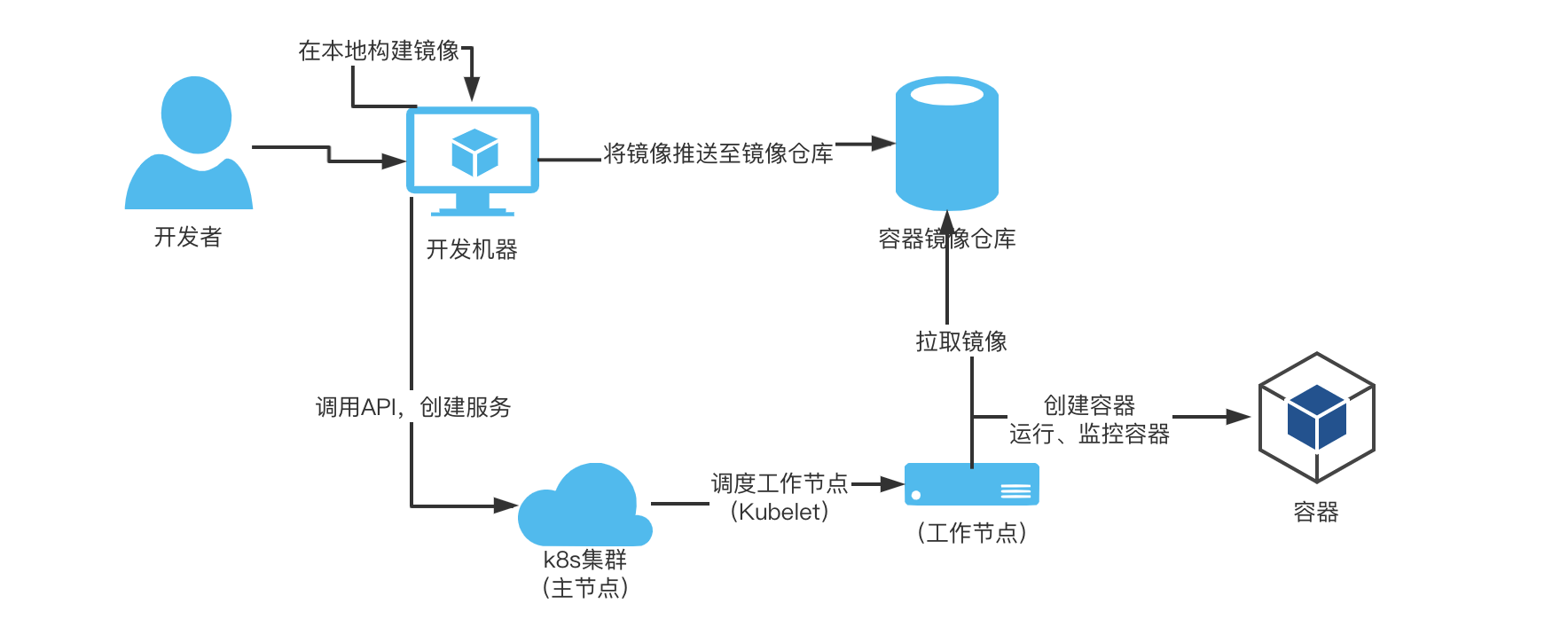
上图是根据到目前为止我们对Kubernetes的了解所画出的一个应用部署流程图。
* 1、开发者在本地机器构建应用程序镜像;
* 2、开发者将本地应用程序镜像psuh到镜像仓库;
* 3、开发者为运行应用程序编写Deployment资源描述文件;
* 4、开发者使用kubectl apply -f命令将应用程序描述文件提交给Kubernetes;
* 5、Scheduler组件根据描述文件调度工作节点部署应用程序;
* 6、在工作节点上由Container runtime负责从镜像仓库拉去镜像、创建Pod并运行容器;
在实际项目部署时,我们可能最关心也最难理解就是网络和存储卷这部分内容,本篇就不过多介绍。
我们需要了解的一些概念:
namespaces:用于实现逻辑隔离,如隔离测试、生产环境资源。不指定namespaces则默认使用default。
节点(Node):节点就是实际的物理机器或者虚拟机,例如阿里云ECS。
Pod:Pod是Kubernetes创建或部署的最小基本单位,一个Pod封装一个或多个应用容器,存储卷、一个独立的网络IP以及管理控制容器运行方式的策略选项。
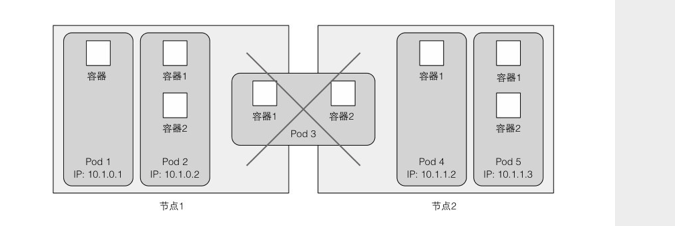
(图片来自《Kubernetes in Action》)
如上图所示,当一个Pod包含多个容器时,这些容器总是运行于同一个工作节点上,不会跨越多个工作节点。例如我们部署一个web程序,可以在一个Pod中运行一个web后端程序的容器、一个web前端程序的容器。Pod可以封装紧密耦合的应用,它们需要由多个容器组成,它们之间能够共享资源,例如前后端部署在一起。而对于我们开发java微服务应用来说,一般一个Pod只会运行一个容器,因此初学时可以不用过多去纠结这些概念。
Service:Service抽象的概念,是Pod的逻辑分组,这一组Pod能够被Service访问到,通常是通过Label、Selector实现。例如:
apiVersion: v1
kind: Service
metadata:
name: demo-srv-service
namespace: sit
spec:
selector:
app: demo-srv
env: sit
ports:
- protocol: TCP
port: 80
targetPort: 8080
通过selector匹配app为demo-srv、env为sit的一组Pod,这组Pod对应demo-srv-service这个Service。
更简单一点理解,假设我们部署一个java程序,一个Pod只启动一个该java程序的容器,那么启动多个该java程序就对应多个Pod,而这组Pod对应同一个Service。
Deployments:Deployment为Pod提供声明式更新。你只需要在Deployment中描述你想要的目标状态是什么,Deployment Controller就会帮你将Pod的实际状态改变到你的目标状态。如指定一个java程序部署的副本数量为3,如果Pod超过3,则控制器会终止额外的Pod,如果少于3,则控制器会创建新的Pod,始终保持在定义范围。
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-srv-deployment
namespace: sit
spec:
# 副本数,运行多少个`Pod`
replicas: 3
# 选择器,使用标签匹配
selector:
matchLabels:
app: demo-srv
template:
metadata:
# 标签
labels:
app: demo-srv
env: sit
spec:
# 容器,指定多个容器就会在一个`Pod`内运行多个容器
containers:
- name: demo-srv
image: registry.cn-shenzhen.aliyuncs.com/wujiuye/demo-srv
DaemonSet:确保每个节点(物理机器或者虚拟机)上只运行一个该应用的Pod。如阿里云的实现的日记收集,就是在每个节点上运行一个用于收集日记的应用程序容器,对应一个Pod。
Pod之间的网络通信:
Kubernetes集群中的所有Pod都在同一个共享网络地址空间中,这意味着每个Pod都可以通过其他Pod的IP地址来实现相互访问。当两个Pod彼此之间发送网络数据包时,它们都会将对方的实际IP地址看作数据包中的源IP。
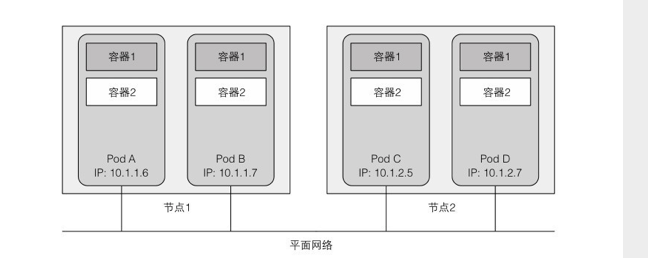
无论是将两个Pod安排在单一的还是不同的工作节点上,同时不管实际节点间的网络拓扑结构如何,这些Pod内的容器都能够像在局域网上的计算机一样通信。
Service之间的网络通信:
Kubernetes Service为一组功能相同的Pod提供单一不变的接入点。当服务存在时,它的IP地址和端口不会改变。客户端通过IP地址和端口号建立连接,这些连接会被路由到提供该服务的任意一个Pod上,会实现负载均衡。
通过这种方式,客户端不需要知道每个单独的提供服务的Pod的地址,这样这些Pod就可以在集群中随时被创建或移除。
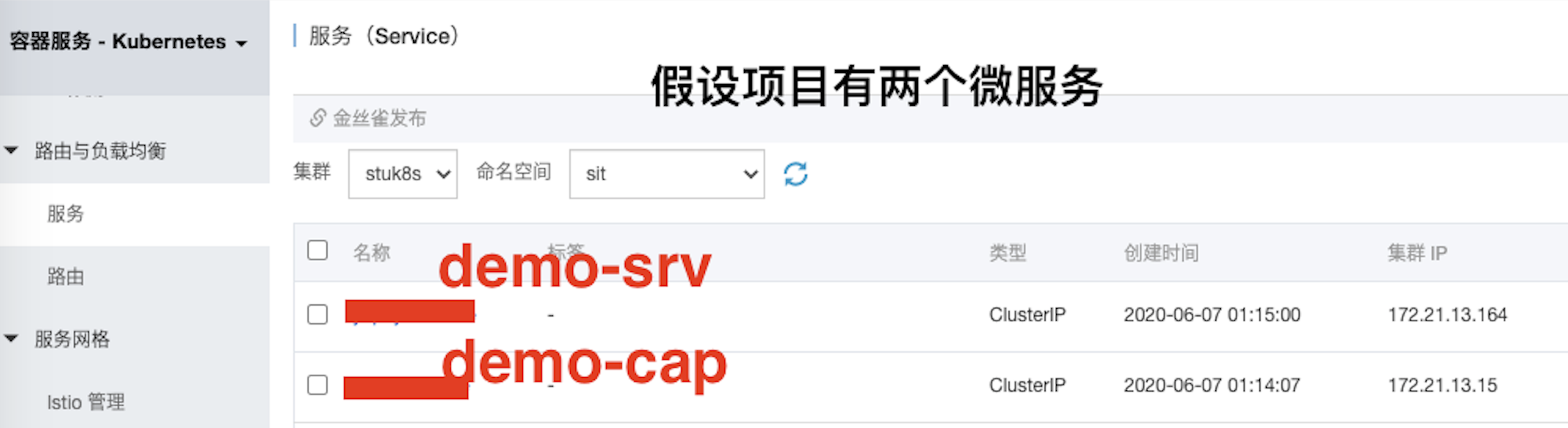
假设现有一个项目,该项目有两个微服务,分别是demo-srv、demo-cap。现在将这两个服务部署到阿里云容器服务Kubernetes上,在控制台的服务列表页可以看到,这两个服务都有一个集群IP,不管这个两个服务部署多少个Pod,也不管Pod怎么变,其它服务都可以通过这个集群IP访问背后的Pod,当然访问背后Pod也是实现负载均衡的。
也是因为如此,我们开发微服务实现的服务发现都是基于Service的,那么在应用程序中实现负载均衡就显得多余了。
类型:
* ClusterIP:通过集群的内部IP暴露服务,选择该值,服务只能够在Kubernetes集群内部可以访问。
* NodePort:可通过任意一个Node节点的IP和NodePort从集群的外部访问服务。
* LoadBalancer:由云产商实现,可以向外部暴露服务,如阿里云提供的负载均衡器。
本篇就介绍到这,Kubernetes要学的知识点很多,但作为开发,我们可能不会去过多的关注一些细节,本篇介绍的知识点是笔者认为作为开发应掌握的知识的。网络、存储卷这些建议多了解一些,网络有关服务间的调用,而存储卷有关日记的存储、文件存储。
不懂的概念可以查阅官方文档:http://docs.kubernetes.org.cn,想要深入学习还是推荐阅读《Kubernetes in Action》中文版。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
本篇我们将从一个简单的demo上手Spring Cloud kubernetes,当然,我们只用到Spring Cloud kubernetes的服务注册与发现、配置中心模块。
选择Spring Cloud Kubernetes意味着我们想要将服务部署到Kubernetes集群,Spring Cloud Kubernetes为我们实现了Spring Cloud的一些接口,让我们可以快速搭建Spring Cloud微服务项目框架,并能使用Kubernetes云原生服务。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。