![]()
上一篇nfs协议的rpc通信协议,我们了解到nfs的rpc通信协议,无论是rpc请求还是rpc响应,其协议头都是以4个字节的消息id开始。
rpc请求:
- |4字节的消息id | 4字节的消息类型,rpc请求为0|Body
rpc响应:
- |4字节的消息id|4字节的消息类型,rpc响应为1|4字节的rpc调用状态码|Body
但当我们抓包并写代码解码的过程中发现,我们解码每个TCP数据包:先获取TCP数据包的Payload,再拿Payload解码为nfs的rpc协议数据包,无论是rpc请求还是rpc响应,都是要先跳过前四个字节,才是rpc协议的消息id,这样解码才正确。
解码代码如下:
func (l *listener) NextAppProtocolData(src, dst *Endpoint, data []byte) {
// 头4个字节到底是什么?
// fmt.Println(binary.BigEndian.Uint32(data[0:]))
xid := binary.BigEndian.Uint32(data[4:])
msgType := binary.BigEndian.Uint32(data[8:])
if msgType == 0 {
fmt.Println("request", xid, msgType)
rpcReqBody := data[12:]
nfsVer := binary.BigEndian.Uint32(rpcReqBody[8:])
op := binary.BigEndian.Uint32(rpcReqBody[12:])
fmt.Println(binary.BigEndian.Uint32(rpcReqBody[0:]),
binary.BigEndian.Uint32(rpcReqBody[4:]),
nfsVer, op)
if nfsVer != 3 || op != 7 {
return
}
fmt.Println(fmt.Sprintf("%s -> %s", src.String(), dst.String()))
fmt.Println(xid, msgType)
} else {
rpcStatus := binary.BigEndian.Uint32(data[12:])
fmt.Println("response:", xid, msgType, rpcStatus)
}
}
那么跳过的前四个字节到底是什么呢?
我们用Wireshark分析数据包发现Wireshark能解码nfs协议,并且我们发现Wireshark能正常解码头4个字节。
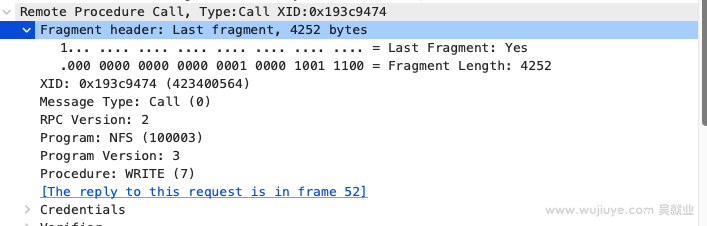
这个Fragment header占四个字节,共32bit,前一个bit是一个bool值。我们通过右键->Copy->Field name拿到这两个字段的名称分别为rpc.lastfrag和rpc.fraglen。
从名字来看,这两个字段都跟rpc协议有关。
我们找到了Wireshark的一篇文档:Display Filter Reference: Remote Procedure Call,有这两个字段的描述,然后通过查找资料,大概理解这两个字段的意思:
rpc.lastfrag:这个字段表示当前数据包是否是RPC消息的最后一个片段。它是一个布尔值,如果当前数据包是消息的最后一个片段,则该字段为真(true)。rpc.fraglen:这个字段表示当前RPC消息片段的长度。它是一个无符号整数值(32位),用来指示数据包中片段的长度27。
RPC的消息在传输之前可能会分成多个片段(fragments)传输,在数据包很大,超过TCP协议Payload所允许的大小的情况下就会分段。rpc.lastfrag 标志一个数据包是否是最后一个片段,如果不是则需要等待接收完才能解码,而 rpc.fraglen 则提供了每个片段的具体长度,有助于正确地重新组装原始的RPC消息。
我们自己实现解码器也应该正确处理多fragments传输的情况,所以头4个字节的rpc.lastfrag和rpc.fraglen至关重要。至此,我们就理解了头4个字节是什么了。
那么,go代码如何实现解码rpc.lastfrag和rpc.fraglen?
代码如下:
// 头4个字节到底是什么?
lastfrag := data[0]>>7&1 == 1
fraglen := uint32(data[3]) | uint32(data[2])<<8 | uint32(data[1])<<16 | uint32(data[0]&0b0111_1111)<<24
fmt.Println("rpc.lastfrag=", lastfrag, "rpc.fraglen", fraglen)