{kind=link}
{kind=link}
{kind=link}
![]()
本篇文章写于2021年03月04日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
笔者开源了自己实现的Java版Raft算法框架raft-core\
项目链接:https://github.com/wujiuye/delay-scheduler/tree/main/raft/raft-core\
该项目代码是delay-scheduler(分布式延迟调度中间件)的子模块,水平有限,建议只用于学习。
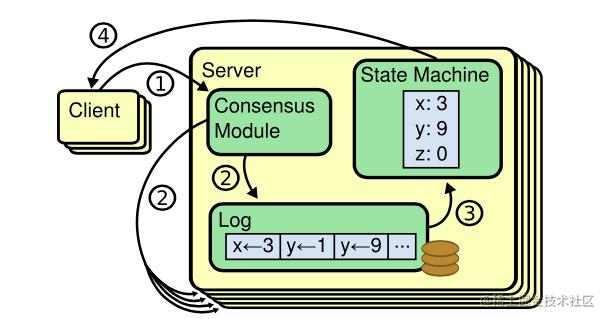
(图片来源:https://github.com/maemual/raft-zh_cn/images/raft-图1.png)
关于CAP原理
C(一致性)A(可用性)P(分区容忍性)原理是分布式系统永远绕不开的话题,在任何的分布式系统中,可用性、一致性和分区容忍性这三个方面都是相互矛盾的,三者不可兼得,最多只能取其二。
* AP:如果要求系统高可用(A)和分区容错(P),那么就必须放弃一致性(C);
* CP:如果要求数据强一致(C),由于网络分区会导致同步时间无限延长(P),可用性就得不到保障,那么就要放弃可用性(A);
* CA:如果不存在网络分区(分区指不同机房/国家/地区)(P),那么强一致性(C)和可用性(A)可以同时满足。
Raft一致性算法简介
在Raft集群中,每个节点都对应一个角色,要么是Leader(领导节点),要么是Follower(跟随节点),在未选举出Leader之前,每个节点都可以是Candidate(候选节点)。
Raft算法约定Raft集群只能有一个Leader节点,并且只能由Leader节点处理客户端的读写请求,将写请求转译为操作日记,由Leader节点将操作日记复制给其它Follower节点,当Leader节点成功将一条操作日记同步到多数节点上时(包括自己在内的多数节点),就可以将操作日记应用到状态机,由状态机执行写操作(执行命令),以此保证数据的最终一致性。
我们可以把Binlog看成Mysql数据库执行的写操作的命令,而MyISAM存储引擎是Binlog的状态机,用于执行命令。
实现Raft算法需要实现的两个RPC接口:
* RequestVoteRpc:选举时由当前候选节点向其它节点发起拉票请求;
* AppendEmtriesRpc:由Leader节点向其它Follower节点发送日记复制请求、心跳请求以及提交日记请求。
定时心跳计时器
Leader节点需要定时向其它Follower节点发送心跳包,以刷新其它Follower节点上的选举超时计时。
心跳计时器在节点成为Leader节点时启动,而在节点变为Follower节点时停止。
要求心跳超时时间间隔要比超时选举时间间隔长,即Heartbeat Timeout(心跳包广播时间)< Election Timeout(选举超时时间)。
超时选举计时器
当计时达到超时(Election Timeout)阈值时触发Leader选举,当前节点将任期号+1,并尝试给自己投一票(如果还未将票投给其它候选人),给自己投票成功则将自己变成候选人,并向其它节点发起拉票请求。
超时选举计时器的当前计时可被重置,在接收到AppendEntriesRPC(含心跳请求)请求时重新计时。要求每个节点的超时阈值要不一样,避免同时发起拉票请求,导致多轮选举都未能选出Leader的情况发生。
Leader选举流程
Leader通过投票选举机制选举,每个任期号每个节点都只能有一票,每个节点都优先考虑投给自己,获得多数选票的节点将成为Leader节点,因此Raft集群要求至少3个节点,并且Raft集群节点总数最好是奇数。
RequestVoteRpc请求数据包(拉票数据包):
public class RequestVote {
private long term;
private int candidateId;
private long lastLogIndex;
private long lastLogTerm;
}
term:拉票方(候选节点)的当前任期号;candidateId:拉票方的节点ID;lastLogIndex:拉票方最新日记条目的索引值;lastLogTerm:拉票方最新日记条目对应的任期号。
RequestVoteRpc响应数据包(投票数据包):
public class RequestVoteResp {
private long term;
private boolean voteGranted;
}
term:投票方的当前任期号,用于告知拉票方更新term值;voteGranted:如果投票方将选票投给拉票方,则voteGranted为true,否则为false。
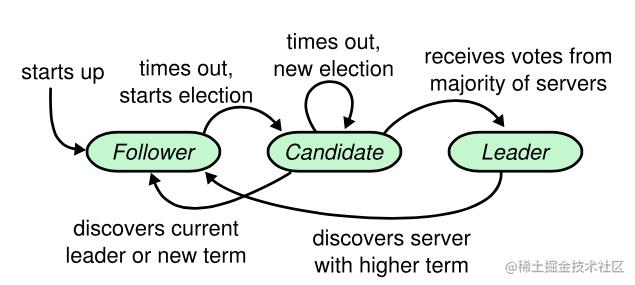
(图片来源:https://github.com/maemual/raft-zh_cn/images/raft-图4.png)
在选举计时器超时时发起拉票请求流程如下:
* 1)将自己本地维护的当前任期号(term)加1;
* 2)为自己投票,投票成功再将自己的状态切换到候选节点(Candidate),因此每个候选节点的第一张选票来自于它自己;
* 3)向其所在集群中的其他节点发送RequestVoteRPC请求(拉票请求),要求它们投票给自己。
每个节点接收到其它候选节点发来的拉票请求时需根据节点当前任期号、日记同步情况、是否已经将当前期的一票投给了其它节点(包括自己)等作出如下反应:
* 1)、如果拉票方的term小于自身的当前term,返回false,提醒拉票方term过时,并明确告诉拉票方,这张选票不会投给它;
* 2)、如果拉票方的term大于自身的当前term,且如果之前没有把选票投给任何人(包括自己),则将选票投给该节点,返回拉票方的term和true;
* 3)、否则如果拉票方的term等于自身的当前term,如果已经把选票投给了拉票方(重复发起请求场景),并且请求方的日记和自己的日记一样新,则返回拉票方的term和true;
* 4)、否则,如果在此之前,已经把选票投给了其他人,则这张选票不能投给请求方,并明确告诉请求方,这张选票不会投给它。
候选节点广播发起拉票请求后需根据最终投票结果作出如下反应:
* 1)、如果多数节点连接异常,则继续当前期重新发起一次拉票,即多数节点挂掉选举异常;
* 2)、得到大多数节点的选票成为Leader,包括自己投给自己的一票,但每个节点只有一票,投给了自己就不能投给其它节点;
* 3)、发现其它节点赢得了选举(当拉票请求响应的term大于当前候选节点的term时,认为其它节点赢得了选举)则主动切换回Follower;
* 4)、当超时选举计时器又触发超时选举时,说明没有接收到Leader的心跳包,最后一次选举没有节点赢得选举成为Leader,那么继续发起选举。
如果是其它节点成为当前期的Leader,Leader会通过发送心跳包告知自己,要留给Leader足够时间发送心跳包给自己,因此选举超时要大于心跳超时,也就是:Heartbeat Timeout(心跳包广播时间)< Election Timeout(选举超时时间)。
在选举结束后,每个Follower节点必须记录当前期的Leader节点是哪个,Leader节点必须记录其它所有Follower节点。Leader节点需要向其它Follower节点发送心跳包以及日记同步请求,而其它Follower节点在接收到客户端请求时需要告知客户端重定向到Leader节点发送请求。
Raft日志复制流程
在Raft集群中,Leader节点负责接收客户端的读写请求,如果是Follower接收请求,则需要将请求重定向到Leader节点。
如果Leader节点接收的是读请求,则Leader节点可直接查询数据响应给客户端;如果Leader节点接收的是写请求,则Leader节点先将写请求转译为一条操作日记,并将操作日记Append到本地,同时向其它节点发起AppendEntriesRPC调用,将该操作日记复制给其它节点,在成功复制多数节点后,Leader节点提交该操作日记,提交成功则应用到状态机,再异步的向其它节点发起AppendEntriesRPC调用,告知其它Follower节点该日记已经提交,Follower节点接收提交请求后,先将日记改为已提交状态,再将日记应用到状态机。
AppendEntriesRPC请求数据包(Leader节点向其它Follower节点发起rpc请求,要求其它Follower节点复制这个日记条目):
public class AppendEntries implements Cloneable {
private long term;
private int leaderId;
private long prevLogIndex;
private long prevLogTerm;
private long leaderCommit;
private CommandLog[] entries;
}
term:Leader节点创建该日记条目时的任期号;leaderId:Leader节点的ID,为了其它Follower节点能够重定向客户端请求到Leader节点;prevLogIndex:Leader节点已提交的日记中最新一条日记的索引;prevLogTerm:Leader节点已提交的日记中最新一条日记的任期号;leaderCommit:Leader节点为每个Follower都维护一个leaderCommit,表示Leader节点认为Follower已经提交的日记条目索引值;entries:将要追加到Follower上的日记条目,如果是心跳包,则entries为空。
AppendEntriesRPC响应数据包(AppendEntries RPC响应):
public class AppendEntriesResp {
private long term;
private boolean success;
}
term:当前任期号,取值为Max(AppendEntries请求携带的term,Follower本地维护的term),用于Leader节点更新自己的任期号,一旦Leader节点发现任期号比自己的要大,就表明自己是一个过时的Leader,需要停止发送心跳包,主动切换为Follower;success:接收者(Follower)是否能够匹配prevLogIndex和prevLogTerm,匹配即说明请求成功。
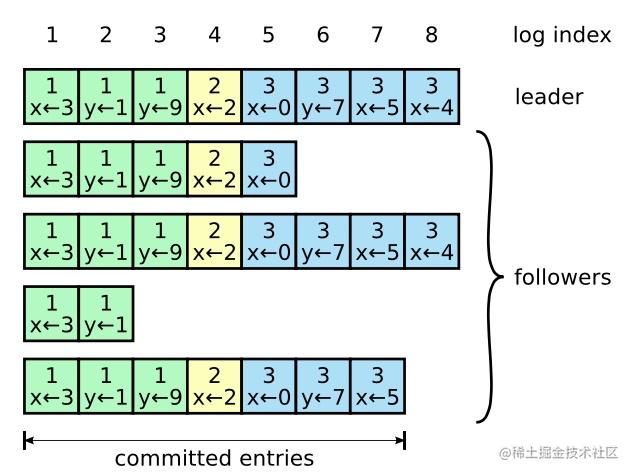
(图片来源:https://github.com/maemual/raft-zh_cn/images/raft-图6.png)
Leader节点处理客户端写请求以及将写请求日记复制给Follower的流程:
* 0)、客户端向Leader发送写请求;
* 1)、Leader将写请求解析成操作指令日记追加到本地日志文件中;
* 2)、Leader异步向其它Follower节点发送AppendEntriesRPC请求;
* 3)、阻塞等待多数节点响应成功,多数节点至少是节点总数除以2加1,由于Leader节点自己也算一个,因此只需要节点总数除以2个节点响应成功即可;
* 4)、如果多数节点响应成功:Leader将该日志条目提交并应用到本地状态机,异步告知其它Follower节点日记已经提交,之后立即向客户端返回操作结果;
* 5)、否则:响应失败给客户端。
Follower节点处理日记复制请求流程:
* 0)、接收到任何AppendEntriesRPC请求(包含心跳包请求、提交日记请求、追加日记请求),都重置选举超时计时器的当前计时;
* 1)、如果自身的term大于请求参数term,另本地记录的Leader的任期号小于自身,则返回自身的term,且success为false(告知请求方:你已经是过期的Leader);
* 2)、否则如果Follower自身在prevLogIndex日记的任期号与请求参数prevLogTerm不匹配,返回自身的term,且success为false(当前Follower节点的日记落后了);
* 3)、否则如果当前只是一个心跳包,说明是接收到Leader的心跳,说明自己已经是Follower,如果需要则将自己从候选节点切换为Follower节点,返回自身的term,且success为true;
* 4)、否则,Follower进行日记一致性检查,删除已经存在但不一致的日记,添加任何在已有的日记中不存在的条目,删除多余的条目,并且,如果是复制已经提交的条目,复制成功时直接提交;
* 5)、如果请求参数的leaderCommit大于自身的当前commitIndex,则将commitIndex更新为Max(leaderCommit,commitIndex),乐观地将本地已提交日记的commitIndex跃进到领导人为该Follower跟踪记得的值,用于Follower刚从故障中恢复过来的场景。
如果Follower节点向Leader节点响应日记追加失败且Follower节点的当前期号小于等于Leader的当前期号,Leader节点将请求参数prevLogIndex递减,然后重新发起AppendEntriesRPC请求,直到AppendEntriesRPC返回成功为止,这才表明在prevLogIndex位置的日志条目中领导人与追随者的保持一致。
这时,Follower节点上prevLogIndex位置之前的日志条目将全部保留,在prevLogIndex位置之后(与Leader有冲突)的日志条目将被Follower全部删除,并且从该位置起追加Leader上在prevLogIndex位置之后的所有日志条目。因此,一旦AppendEntriesRPC返回成功,Leader和Follower的日志就可以保持一致了。
一致性
由于一个候选节点必须是得到多数节点投票才能成为Leader,且投票时节点不会把票投给没有自己的日志新的候选节点,再者Leader只在已经将日记成功同步给多数节点(包括自己)才提交日记(将日记变成已提交状态,同时应用到状态机),因此每次选举出来的Leader就都是包含所有已提交日志的节点。
当新的Leader节点将新日记同步给某个Follower节点时,如果该Follower节点的日记落后很多,该Follower节点会主动移除Leader上没有的日记,并且同步Leader节点日记给Follower。对于Leader节点已经标志为已提交的日记,Follower在接收时就可以直接应用到状态机,以保持数据最终一致性。
Multi Raft
假设有三台机器,每台机器部署一个Raft节点服务,由于读写请求都由Leader节点处理,那么不就只能有一台机器工作?
我们可以给一个节点服务启动多个Raft服务(注意不是多个进程),构造成多个Raft集群,即Multi Raft,这样每个Raft集群的Leader节点就可能均匀分布在多台机器上。
例如:
| 机器 | Raft节点 |
Raft节点 |
Raft节点 |
|---|---|---|---|
机器1 |
Raft服务A节点1(Leader) |
Raft服务B节点1(Follower) |
Raft服务C节点1(Follower) |
机器2 |
Raft服务A节点2(Follower) |
Raft服务B节点2(Leader) |
Raft服务C节点2(Follower) |
机器3 |
Raft服务A节点3(Follower) |
Raft服务B节点3(Follower) |
Raft服务C节点3(Leader) |
在分布式数据库TiDB中,就采用了Multi Raft,将数据进行分片处理,让每个Raft集群单独负责一部分数据。
参考文献
华为云容器服务团队.《云原生分布式存储基石:
etcd深入解析》 (云计算技术系列丛书)Raft论文地址
Raft论文中文版:https://github.com/maemual/raft-zh_cn图片来源
图片来源:https://github.com/maemual/raft-zh_cn/tree/master/images