![]()
 故障排查与性能优化 专栏收录该内容,点击查看专栏更多内容
故障排查与性能优化 专栏收录该内容,点击查看专栏更多内容原创 吴就业 509 0 2022-02-15
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/2ab52cf257194deaa66bc3588348e2f4
作者:吴就业
链接:https://wujiuye.com/article/2ab52cf257194deaa66bc3588348e2f4
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
业务使用我们基础部门封装的kafka组件,在一次版本迭代中,我们引入了offset缓存,正是这个缓存,在某种条件触发下,会导致出现消息重复消费现象。
业务方反馈,升级组件后,某个topic,出现过几次不规律的从很早之前的offset重复消费消息,现象表现如下图。
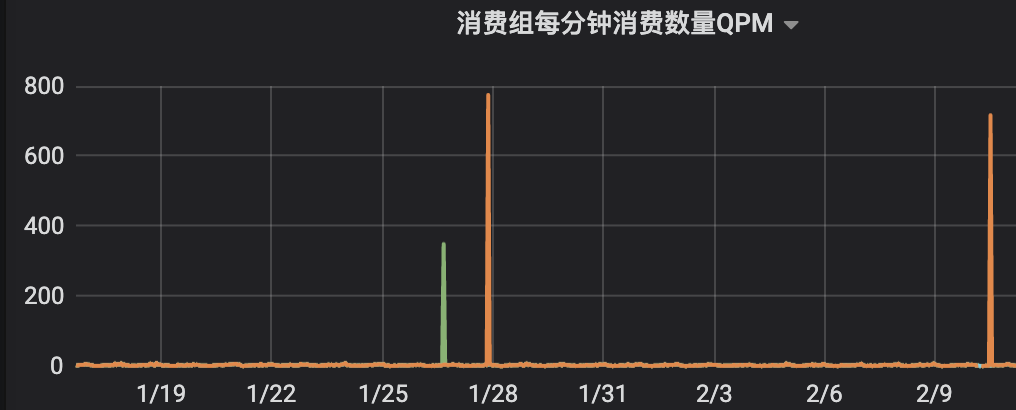
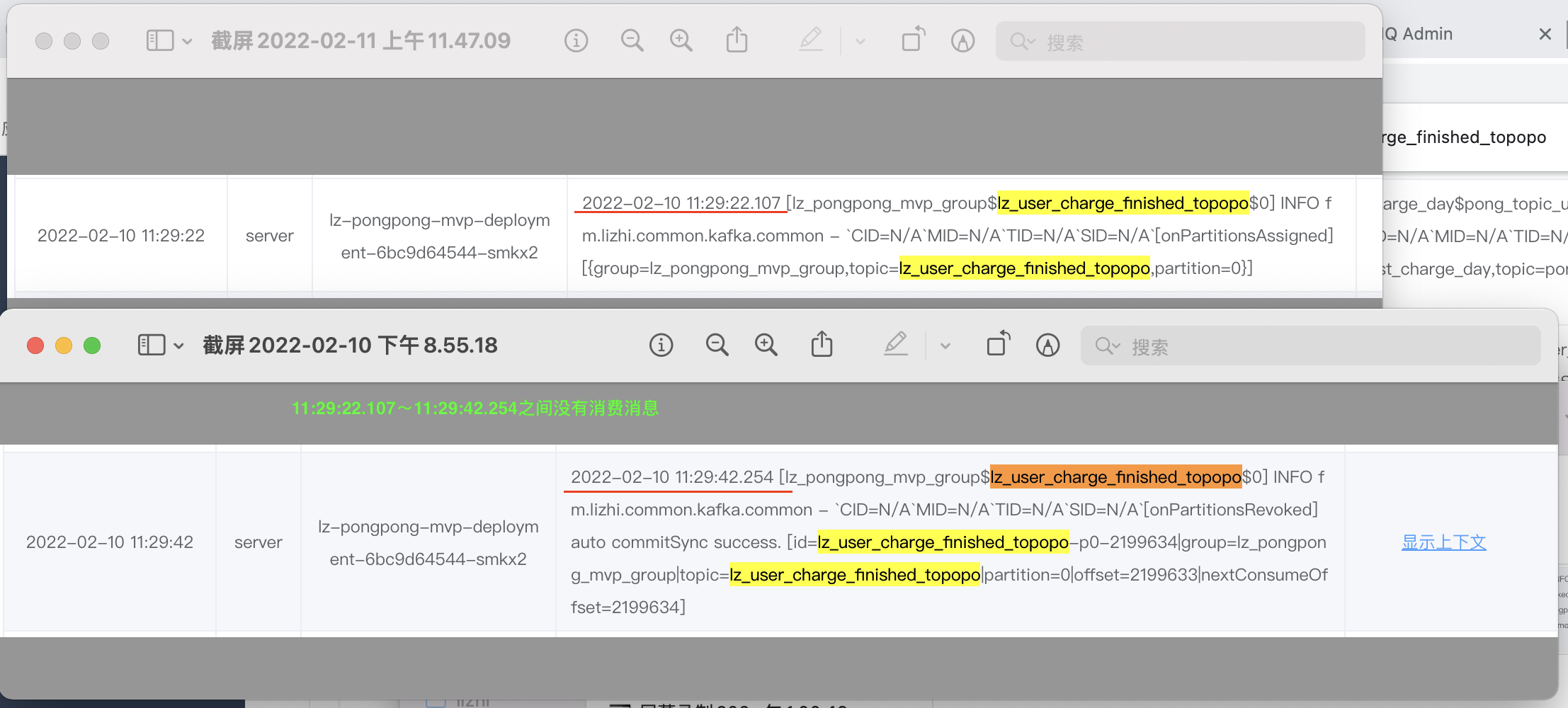
查看这些时间点范围的日记发现,都有出现重均衡的情况,所以首先就是怀疑重均衡导致的。
随后看了组件重均衡处理的相关代码,以及出现重复消费的时间点范围内的重均衡日记,锁定了猜测。
此次排查的,出现重复消费现象的topic,只有一个分区,部署4个消费者节点,每个节点开启3个KafkaConsumer,假设给这些消费者编号为:
从日记表现来看,猜测可能的原因如下:
只是猜测,当时各种尝试都无法重现出来,可能还受其它条件的影响,因此未被证实。
目的是在重均衡时,失去某些分区消费权限的消费者,在重均衡转移后的消费者开始消费这些分区之前,先把最后消费的消息的offset提交,避免接管的消费者产生不必要的重复消费。
消费者每消费一条消息,就会将该消息的offset更新到Map缓存,key为TopicPartition,value为offset。
给消费者注册ConsumerRebalanceListener,在onPartitionsRevoked方法中,将失去消费权限的TopicPartition的offset提交。
正常情况下,不会出现“重均衡到了a0,然后不知道什么原因,a0没开始消费,又重均衡到了其它节点”这种情况,所以在测试组件时,没考虑到这种情况。
修复只需要在ConsumerRebalanceListener的onPartitionsAssigned方法中,移除缓存。
class AutoCommitOffsetRebalanceListener implements ConsumerRebalanceListener {
private final String group;
private final KafkaConsumer<String, byte[]> consumer;
private final Map<TopicPartition, OffsetAndMetadata> offsetNewMap = new ConcurrentHashMap<>();
public AutoCommitOffsetRebalanceListener(String group, KafkaConsumer<String, byte[]> consumer) {
this.consumer = consumer;
this.group = group;
}
// 每消费成功一条消息调用
void syncOffset(TopicPartition topicPartition, OffsetAndMetadata offsetAndMetadata) {
offsetNewMap.put(topicPartition,offsetAndMetadata);
}
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
Map<TopicPartition, OffsetAndMetadata> commitMap = new HashMap<>();
for (TopicPartition topicPartition : partitions) {
OffsetAndMetadata offsetAndMetadata = offsetNewMap.get(topicPartition);
if (offsetAndMetadata != null) {
commitMap.put(topicPartition, offsetAndMetadata.getMetadata());
}
}
// 提交offset
if (!CollectionUtils.isNullOrEmpty(commitMap)) {
try {
this.consumer.commitSync(commitMap);
LogUtils.info("[onPartitionsRevoked] auto commitSync success. {}", commitMapToString(commitMap));
} catch (CommitFailedException exception) {
LogUtils.info("[onPartitionsRevoked] auto commitSync fail. {}, error msg:{}", commitMapToString(commitMap), exception.getMessage());
}
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// fix cache bug on this
for (TopicPartition tp : partitions) {
offsetNewMap.remove(tp);
}
LogUtils.info("[onPartitionsAssigned] {}", partitionsToString(partitions));
}
}
虽然本地debug各种模拟都未能复现,但从日记表现的现象来看,猜测的原因可能性非常大。
本地未能复现“重均衡到了a0,然后不知道什么原因,a0没开始消费,又重均衡到了其它节点”,可能是因为还有其它条件的影响。需要业务方确认消息消费已经做了幂等之后,在将问题修复后,配合升级一个版本,再验证。
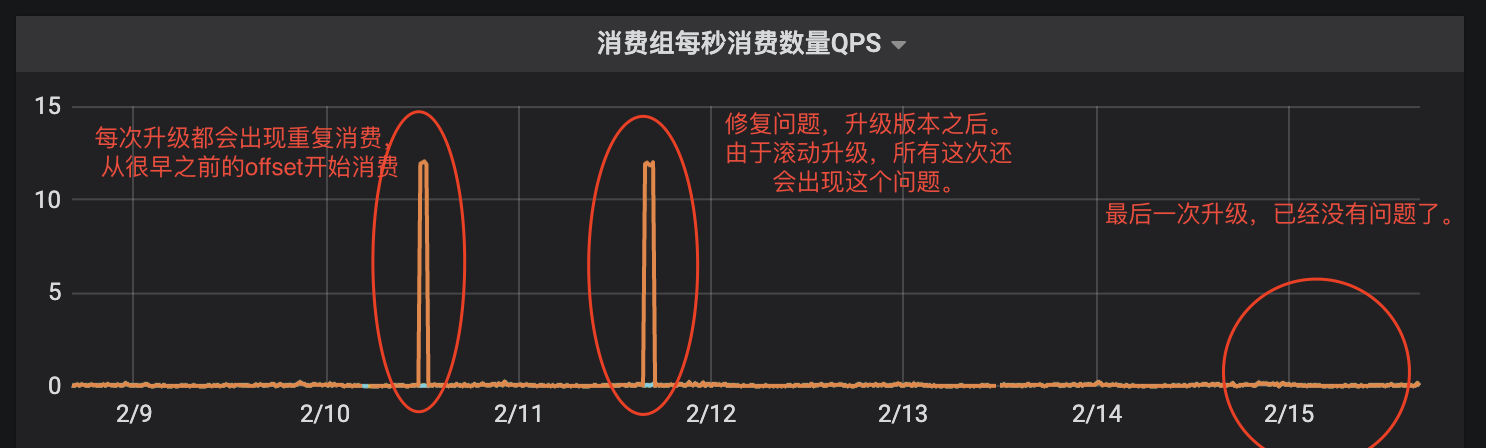
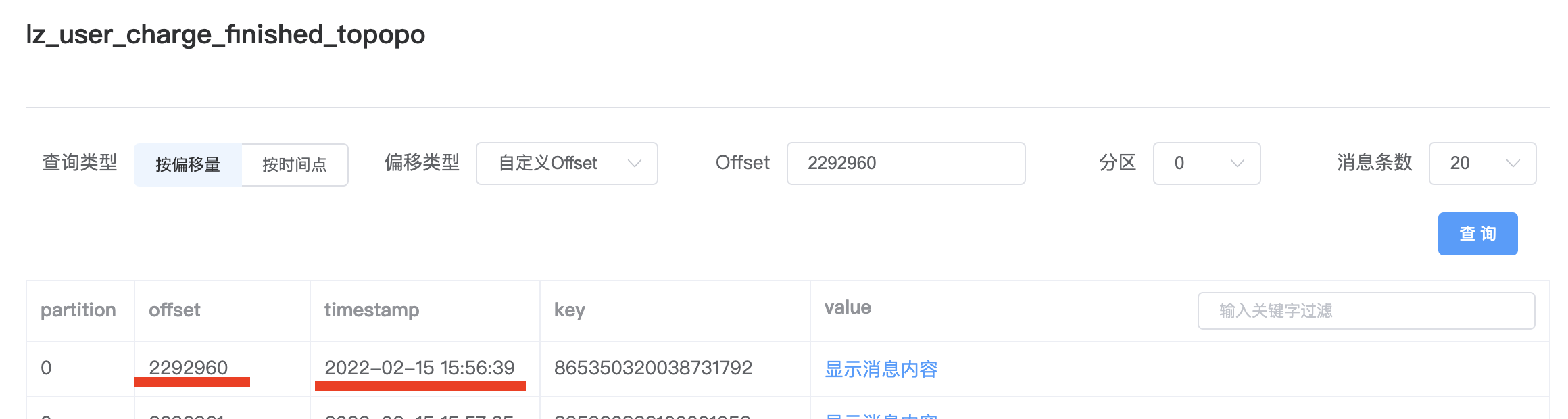
升级后,指标数据、日记,都没有再出现重复消费情况,证实了前面提出的猜测。
指标:
日记:

声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
此次性能测试对比的是我们基于Dubbo扩展点自实现的Http rpc协议,与Dubbo原生Dubbo rpc协议的单次请求响应平均耗时、吞吐量。
很多规模稍大点的公司,内部都会有多个业务部门,这些业务部门都有自己的业务产品。每个业务部门开发的产品部署的环境物理上也都是相对隔离的,但这些业务部门之间可能存在合作关系,业务关联,因此就有了跨业务RPC调用的需求。
在同一时刻需要触发的Job只有少量的情况下,我们看不到Quartz的性能缺陷,在Job数量明显增加情况下,我们就会发现,调度延迟会有明显增加。尽管横向扩展节点,调度延迟也不会降低,且整体调度性能没有明显好转,反而更糟糕。
如果同一时刻需要下发几百个执行job的请求给执行器,使用这种阻塞的RPC,意味着需要开启几百个线程,使用几百个连接发送请求,而这几百个线程都需要阻塞等待响应,Job越多,需要的线程数就会越多,对调动中心的性能影响就越大。
我们基于XXL-JOB的架构原理,重新架构设计了支持多租户横向扩展的分布式任务调度平台。本篇介绍如何实现多个逻辑集群(多个租户逻辑上是独立的集群)的均衡选主。
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。