![]()
本篇文章写于2019年12月02日,从公众号同步过来(博客搬家),本篇为原创文章。
并发数上升,到底是哪个服务处理能力到了瓶颈,还是Redis性能到了瓶颈,只有找出是哪里的性能问题,才能对症下药。所以,了解redis的一些运维知识能够帮助我们快速判定是否Redis集群的性能问题。
redis-cli命令的 –stat选项
关于stat选项,官网也是介绍的比较简单。使用redis-cli命令加上stat选项可以实时监视redis实例,比如当前节点内存中缓存的 key总数以及每秒处理请求数等。stat默认每隔一秒会输出一行信息,如果需要改变频率可使用-i 指定频率,单位为秒,如–stat -i 100。需要配合-h选项使用。

关于requests与connections官方也没有介绍,自己结合本地和线上的输出,做了对比得出的结论。
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
97146 6.82G 1724 0 60068357585 (+49536) 93936323
97146 6.82G 1724 0 60068403702 (+46117) 93936323
97146 6.82G 1724 0 60068451875 (+48173) 93936323
97146 6.82G 1724 0 60068496037 (+44162) 93936323
- keys:当前节点缓存的key总数
- mem:当前节点缓存总的占用内存
- clients:当前节点的活跃连接数,或者说未断开连接的总连接数
- blocked:当前节点正在等待阻塞命令的数量
- requests:当前处理的请求数,与上一次请求数相减可知1秒所处理的请求,或者说所执行的命令数。
- connections:是历史连接总数,即到目前为止,一共新建了多少个连接。与前一次相减,可以得出一秒内新建的连接数。
Requests列括号里的数是每间隔所处理的命令数。比如当前60068496037减去前一次60068451875 等于44162,由于stat默认频率是每秒输出一次,44162就是每秒执行4万多条命令。正好是括号里面的数字,也因此可以知道,括号里面的数字代表每秒(interval)执行的命令数。
当然–stat每秒输出一次结果也是一条命令,所以在没有任何请求的情况下,你看到的requests是自增的,可以本地起个redsi服务,然后使用redis-cli –stat观察下输出。
Blocked并不是排队等待执行的命令数,而是客户端执行阻塞命令的总数。比如BLPOP。
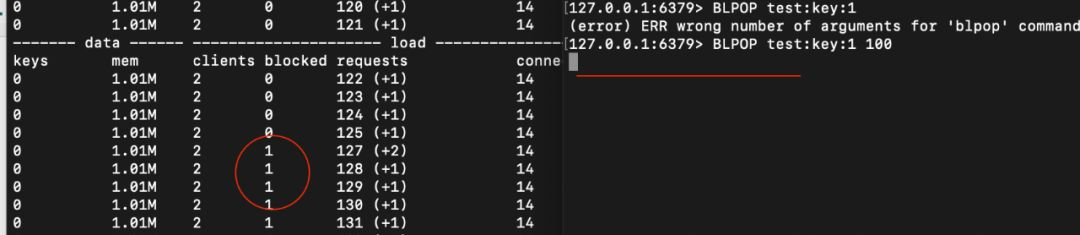
Connections也是很有用的参数,如果发现connections与前一次的差值很大,且很频繁,那就要看下代码中连接池配置是否生效了。
使用–stat分析读写分离的主从集群缺点
在此之前,我们项目中用的是古老的主从集群模式,使用读写分离的连接池,所有写请求都会访问主节点,所有读请求都会访问从节点,那么读写分离会存在哪些问题?
观察主节点,所有写请求都会发到这个节点。
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
382453 1.22G 1305 0 53636611824 (+5112) 70953183
382453 1.22G 1305 0 53636616926 (+5102) 70953183
382453 1.22G 1305 0 53636622056 (+5130) 70953183
观察从节点,所有读请求都会发到这个节点。
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
382551 1.22G 1307 0 197046636517 (+34705) 75561440
382551 1.22G 1307 0 197046669775 (+33258) 75561440
382552 1.22G 1307 0 197046701747 (+31972) 75561440
382551 1.22G 1307 0 197046734329 (+32582) 75561440
很明显,主节点每秒处理的写请求数远小于从节点每秒处理的读请求数。在极端情况下,比如写少读多的场景,使用这种主从读写分离方案,会导致一个节点无请求,而另一个节点忙得不可开交。
主从读写分离还有一个缺点,如果一时间批量写了很多数据,由于主从同步的延时问题,会出现一个空白期,从从节点上读不到数据。如果有实时性要求高的场景,或者大批量数据更新很频繁的场景,还是不建议使用读写分离。从节点应该只用来提供高可用的保证,在主节点挂的情况下从节点保证这部分槽位可用。当然,这不用也是浪费。
分析两主无从Cluster集群模式
只有两个主节点的Cluster集群,槽位平均分配。使用redis-cli –stat实时监视实例。
节点1输出片段:
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
97270 6.82G 1726 0 60242433804 (+26930) 94154236
97270 6.81G 1726 0 60242457927 (+24123) 94154236
97270 6.82G 1725 0 60242485748 (+27821) 94154236
97270 6.82G 1725 0 60242511827 (+26079) 94154236
节点2输出片段:
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
96077 4.20G 1725 0 61244385399 (+32594) 94349868
96076 4.20G 1725 0 61244417031 (+31632) 94349868
96075 4.21G 1725 0 61244443142 (+26111) 94350076
96075 4.20G 1725 0 61244466682 (+23540) 94350076
从两个节点的当前连接数可以看出,JedisCluster配置的连接池会为每个节点创建一个连接池,每个节点的连接池连接数都是相同的。之所以会每个节点都维持相同的连接数,因为每个请求的key都有可能落在其中的一个节点上,你无法预知程序运行过程中落在哪个节点的请求数较多,哪个较少。
当各个服务的集群总节点数很多的情况下,就需要合理分配连接池的最大连接数。官方推荐单个redis节点最大连接数不超过1w,假设有20个服务节点需要用到redis,那么每个节点的连接池最大连接数最大不能超过10000/20 = 500。建议连接池的最大连接数比业务线程的最大线程数多20个连接,只要确保每个工作线程都能有一个redis连接,不至于为了等待连接而阻塞就可以,因为不可能一个线程同时会用到2个以上的连接。假设工作线程数为200,那么redis连接池可以配置为200~220。
从两个节点的内存使用和每秒处理的请求数能够看出,数据的倾斜还是较为严重的,每秒请求数相差在1w左右,这个差距还在可接受范围内。如果请求和内存的倾斜比较严重,就可以重新分配槽位,给请求和存储较少的一方分配更多的槽位以达到平衡状态。
使用info也能统计每秒处理的命令数
stat对于性能监控还是很有帮助的。能够获取到每秒处理的命令数还可以通过info Stats。如
172.31.x.x:6379> info stats
# Stats
.....
instantaneous_ops_per_sec:8589
....
instantaneous_ops_per_sec:redis内部较实时的每秒执行的命令数。
如果想要获取更详细的每种命令的平均耗时,可以使用info Commandstats查看如:
172.31.x.x:6379> info Commandstats
cmdstat_zrangebyscore:calls=1006828954,usec=9633479351,usec_per_call=9.57
cmdstat_rpush:calls=49673,usec=278402,usec_per_call=5.60
cmdstat_setbit:calls=86267170,usec=2645199883,usec_per_call=30.66
......
- cmdstat_zrangebyscore: 即zrangebyscore命令
- calls:命令调用总次数
- usec: 总耗时
- usec_per_call: 平均耗时,单位微秒
slowlog慢查询分析
当命令的执行耗时超过配置的慢查询时间,则会被放入一个慢查询的队列中。可通过config set slowlog-log-slower-than xxx修改慢查询时间,单位微秒,默认情况下,这个值为10000,即所有执行时间超过10ms的都会记录到慢查询队列。使用slowlog get可以查看慢查询信息。
172.31.x.x:6379> slowlog get 1
1) 1) (integer) 6018
2) (integer) 1575108134
3) (integer) 19861
4) 1) "ZRANGEBYSCORE"
2) "ip-country-city-locations-range-3708"
3) "3.72526109E9"
4) "1.7976931348623157E308"
5) "limit"
6) "0"
7) "1"
5)"172.31.x.x:xxx"
......
1)、慢查询自增id;
2)、命令执行完成时间,时间戳;
3)、命令执行耗时,单位为微秒,1秒=1000毫秒,1毫秒等于1000微秒;
4)、执行的命令;
5) 、发起该命令请求的客户端ip及端口号。
通过分析慢查询,可以分析项目中哪些地方用到这些命令,及时优化这些命令能够在大流量来临之前杜绝隐患,也能及时对代码进行调优,通过替换存储的数据结构优化查询性能,减少单次请求的耗时。
网络延迟也是我们要关注的问题
redis-cli命令–latency选项可以测试当前服务器与redis某个节点的网络延迟。
>src/redis-cli --latency -h 172.31.1.1
min: 0, max: 12, avg: 0.25 (1047 samples)
avg:0.25,即延迟为250μs。如果通过外网连接网络延迟会很高,比如跨机房的redis调用,延迟高的情况下使用redis反而比使用本地硬盘读写性能更差。
还有其它影响redis性能的因素,比如内存的使用,持久化策略等。
AOF持久化策略影响性能问题
如果数据不需要持久化,或者要求不严格,建议直接禁用掉AOF持久化策略,同时RDB快照的保存时间间隔也要调高一些,比如一小时一次,以此达到更高的性能。
# 是否开启持久化策略
# (支持同时开启RDB和AOF,即混合策略)
appendonly no
# yes: 在aof重写期间不做fsync刷盘操作,可能丢失整个AOF重写期间的数据,
no-appendfsync-on-rewrite yes
# fsync针对单个文件操作(比如AOF文件),做强制硬盘同步,fsync将阻塞直到写入硬盘完成后返回,保证了数据持久化。
# always:每次写入都要同步AOF文件。
# no:同步硬盘操作由操作系统负责,通常同步周期为30秒,数据安全性无法保证。
# everysec:由专门线程每秒同步一次fsync。理论上只有在系统突然宕机的情况下丢失1秒的数据。
appendfsync no
#当前aof文件大小与上次重写后文件大小的比值超过该值时进行重写,200即等于之前的2倍
auto-aof-rewrite-percentage 200
#当aof文件大小大于该值时进程重写,以减小aof文件占用的磁盘空间
auto-aof-rewrite-min-size 64mb
appendfsync为everysec时的刷盘过程。
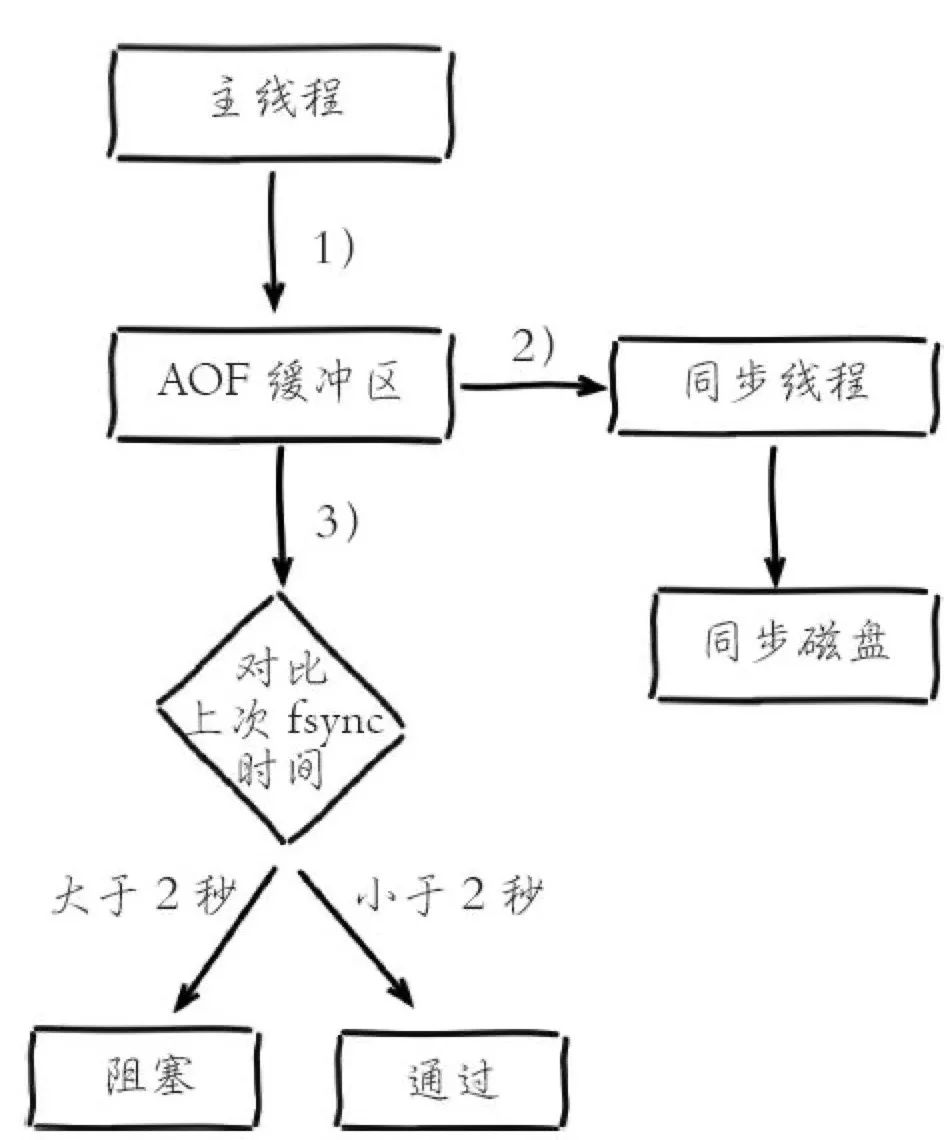
1)主线程负责写入AOF缓冲区。
2)AOF线程负责每秒执行一次同步磁盘操作,并记录最近一次同步时间。
3)主线程负责对比上次AOF同步时间。如果距上次同步成功时间在2秒内,主线程直接返回;如果距上次同步成功时间超过2秒,主线程将会阻塞,直到同步操作完成。
如果系统fsync缓慢,将会导致Redis主线程阻塞影响效率。
上次我将一千两百万记录的ip库数据写入redis时,就因为开启了aof持久化策略,由于大批量数据的写入,导致aof文件几乎每秒重写一次,后面改为1g时重写也因为文件过大重写时间长,没有一次能够成功将一千两百万数据成功写入的。