![]()
本篇文章写于2020年11月27日,从公众号|掘金|CSDN手工同步过来(博客搬家),本篇为原创文章。
由原来的《如果可以,我想并行消费Kafka拉取的数据库Binlog》和《使用Kafka订阅Binlog之字段值获取防坑指南(阿里云DTS)》合并为一篇
并行消费Kafka拉取的数据库Binlog
笔者在上一篇提到:由于Binlog需要顺序消费,所以阿里数据订阅服务DTS只将Binlog放入topic的单一分区,所以订阅Kafka单一分区只能有一个线程去拉取消息。
官方提供的DEMO采用生产-消费模式搭建DTS binlog消费框架,允许消费者有一个默认512大小的阻塞队列,由生产者往消费者的队列中存入消息,消费者线程通过轮询队列方式调用监听器消费消息。
按官方DEMO的这种方式,只能有一个线程去消费消息,而消费Binlog涉及访问数据库、同步新数据到数据库/ES/缓存,都是些耗时的I/O操作。这种方式作为DEMO本地测试、技术验证还好,如果线上服务采样这种方式,只会导致大量Binlog记录延迟被消费以及消息扎堆现象出现,数据同步也就失去了实时性。
在必须要确保Binlog顺序消费的前提下,怎么才能实现并发消费,提升消息消费速度,这是我们必须要解决的,也是笔者苦思良久都想不到完美答案的问题。
一个生产者-多个消费者-一个offset提交者
一种比较折中的方法是,在官方DEMO的基础上,将单一生产者对应一个消费者,改为单一生产者对应多个消费者,并且消费者不再负责定时提交offset(消费偏移量)。
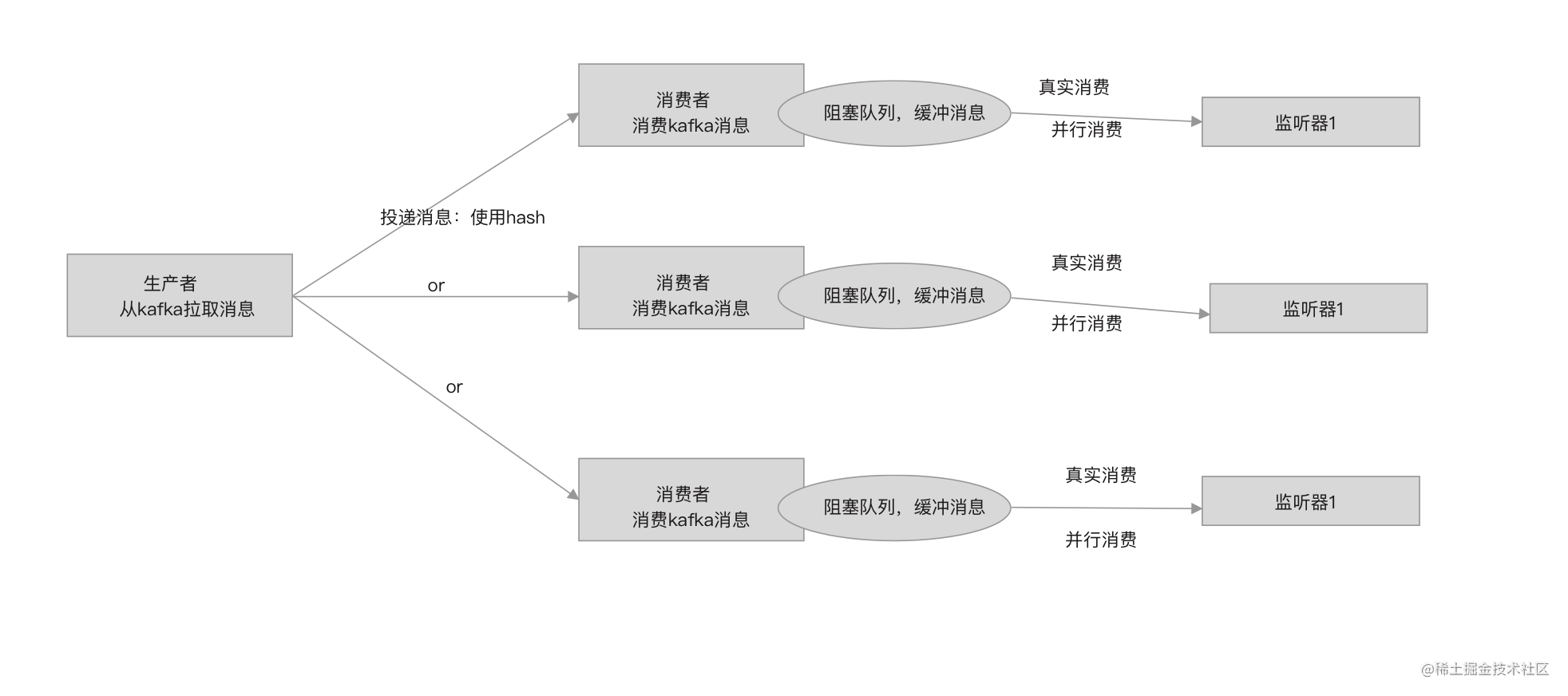
问题一,怎么解决顺序消费Binlog?
笔者想到的答案是一致性hash。
通过一致性hash将操作同一张表的Binlog提交给同一个消费者,整个应用需要监听多少张表就创建多少个消费者,这似乎可行。
实现代码如下:
int hash;
if (realRecord.getObjectName() != null) {
// 同一个表确保由同一个EtlRecordProcessor处理
// objectName = 库名.表名
hash = Math.abs(realRecord.getObjectName().hashCode());
} else {
hash = Math.abs(realRecord.getId().hashCode());
}
// 从多个消费者中选取一个(EtlRecordProcessor数量是固定的,不需要实现一致性hash)
EtlRecordProcessor etlRecordProcessor = recordProcessor[hash % recordProcessor.length];
// offer实现背压
while (!etlRecordProcessor.offer(200, TimeUnit.MILLISECONDS, userRecord) && !existed) {
}
问题二,怎么解决并发消费offset提交问题?
在数据同步可以容忍消息重复消费的前提下,还至少要确保消息被消费一次,所以提交的offset必须是所有消费者已经消费的记录中取最小的offset,每次提交都只提交最小的offset。
要实现这个语意,就需要抽象出一个”offset提交者”,负责完成定时每5秒提交一次且每次提交都只提交最小的offset。
“offset提交者”使用一个队列存放所有消费者(同topic同分区)提交的offset,并且这个队列必须是支持有序插入的,队列的头永远是最小的offset,队列的尾部永远都是最大的offset。
“offset提交者”负责每隔5秒从这个队列中取出连续最大的offset,然后提交。
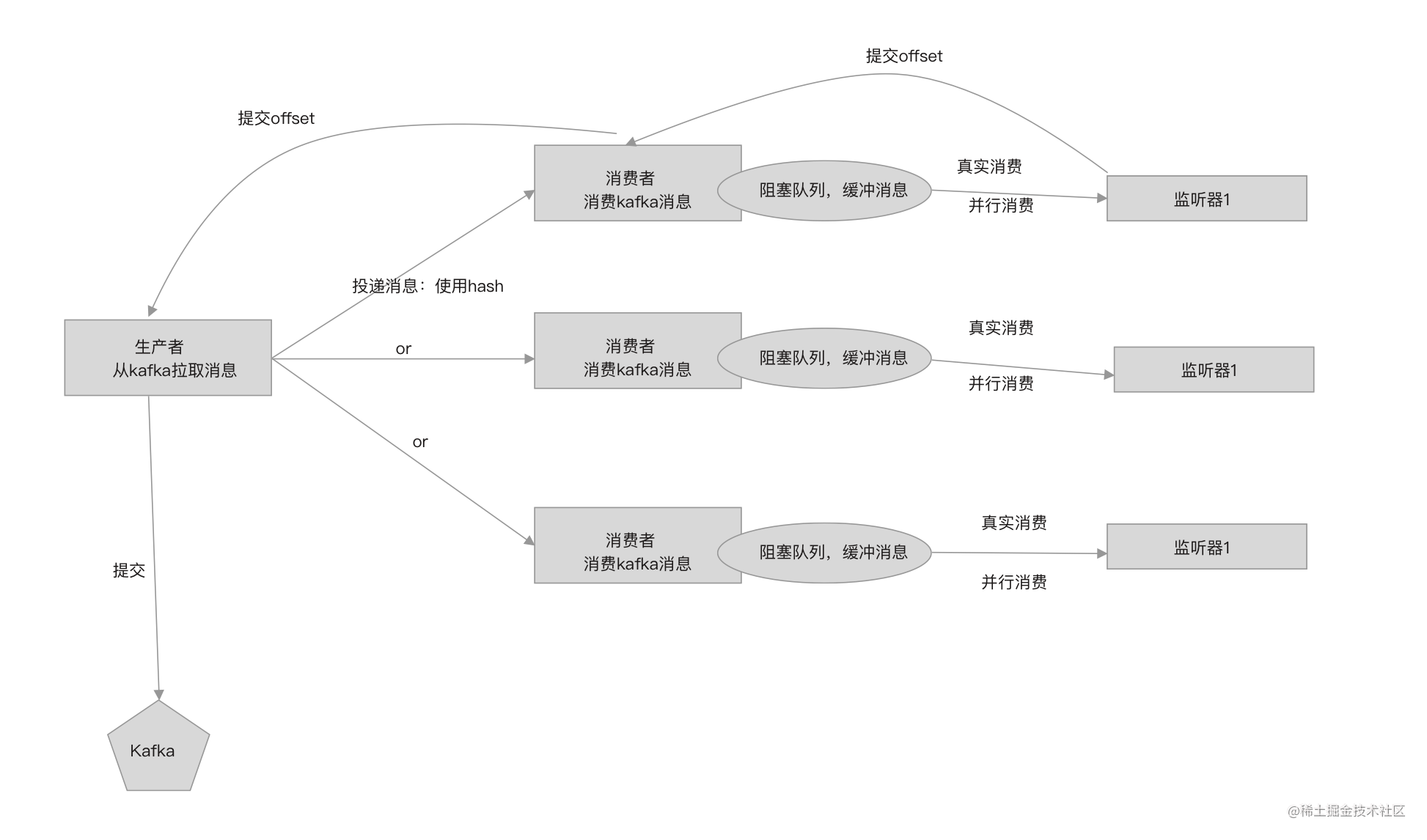
假设有3个消费者,某个时刻,每个消费者提交到队列中的offset为:
A: 2223409、2223415、2223417
B: 2223410、2223411、2223416
C: 2223412、2223413
那么offset队列存储的元素为:
2223409、2223410、2223411、2223412、2223413、2223415、2223416、2223417
下次提交offset时,从offset队列中获取实际要提交的offset的规则如下。
从最小值开始取,取得2223409,将指针往后移动,看看后一个元素是否等于当前元素的值+1,等于表示连续。一直将指针往后移动,发现2223413与它的后一个元素不是连续,则本次取的offset为2223413。将2223413和它之前的元素从队列中移除。最终提交的offset就是2223413。
offset有序队列的实现在文章末尾给出。
“offset提交者”提交者的实现代码如下:
public class AtomicOffsetCommitCallBack extends WorkThread.Work implements OffsetCommitCallBack {
private final Context context;
private volatile boolean existed = false;
/**
* 使用排序链表,确保每次提交的都是最小的offset,容忍重复消费,但不允许漏掉消费
*/
private LinkSortSupporAsync<Checkpoint> linkSort = new LinkSortSupporAsync<>();
private volatile long lastCommitOffset = -1;
public AtomicOffsetCommitCallBack(Context context) {
this.context = context;
}
// 由消费者调用,只是将offset提交到链表
@Override
public void commit(TopicPartition tp, long timestamp, long offset) {
Checkpoint checkpoint = new Checkpoint(tp, timestamp, offset);
linkSort.put(checkpoint);
}
@Override
public void close() {
existed = true;
}
@Override
public void run() {
while (!existed) {
Util.sleepMs(5000); // 5秒提交一次
// 从队列获取本次提交的offset
Checkpoint commitCheckpoint = linkSort.popSuccessiveMax(Integer.MAX_VALUE);
if (commitCheckpoint != null && commitCheckpoint.getOffset() > lastCommitOffset) {
if (commitCheckpoint.getTopicPartition() != null && commitCheckpoint.getOffset() != -1) {
// 提交offset
context.getRecordGenerator().setToCommitCheckpoint(commitCheckpoint);
lastCommitOffset = commitCheckpoint.getOffset();
}
}
}
}
}
通过这种方式至少可以确保不会出现大批量消息没消费就已经将offset设置跳过这些消息的情况,解决重启时会丢失这些消费且永久不会被消费到的问题。但这种方式却也导致重启时可能会有大量消息被重复消费。
有得必有失。我们只能通过调整每个消费者持有的消息阻塞队列的大小来控制可能重复消费的最大消息数量。但这个值不能太少,避免因某个消费者的队列消息很多,其它消费者的队列还很空的情况下,阻塞拉取线程。
在每个队列都快满的情况下,阻塞队列阻塞拉取线程可降低消息的生产速度,实现背压。
解决以上两个问题后得出的新模型如下:
public class Context {
/**
* 生产者
*/
private RecordGenerator recordGenerator;
/**
* 消费者
*/
private EtlRecordProcessor[] recordProcessor;
/**
* offset提交者
*/
private AtomicOffsetCommitCallBack offsetCommitCallBack;
}
使用本地存储offset+提交到kafka方式
在上篇文章中,笔者建议不使用本地文件存储offset,这是因为应用部署到新机器上会找不到存储offset的文件。
但如果考虑网络等问题,那么Kafka commit可能存在提交失败的情况,因此新版本中,我们开始同时使用两种策略,先提交到本地再提交到kafka。
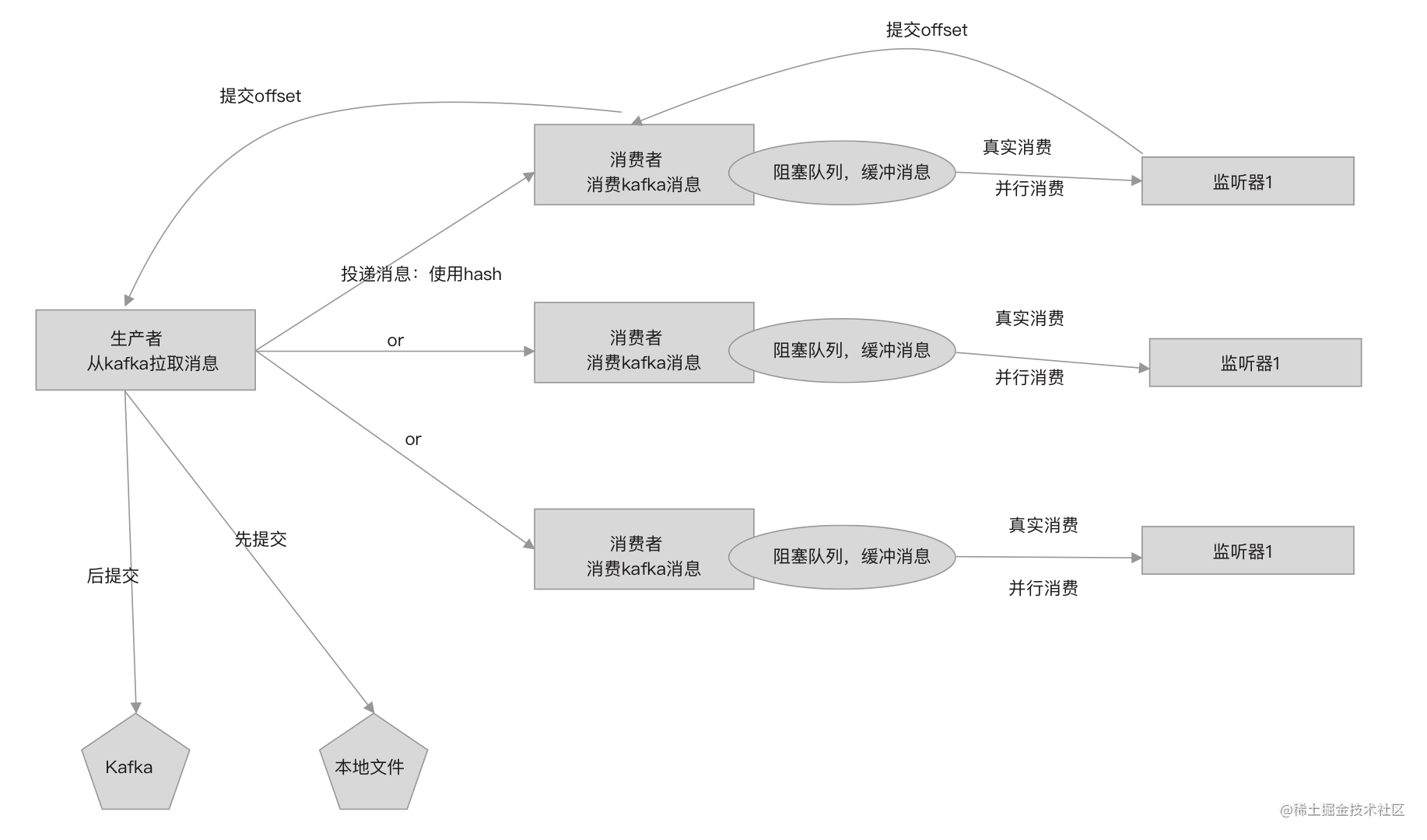
重启时,如果本地存在offset文件,则优先从文件中读取上次提交的offset,没有再从kafka拉取,代码如下。
public class RecordGenerator implements Runnable, Closeable {
private Checkpoint initAndGetCheckpoint(ConsumerWrap kafkaConsumerWrap) {
// 不建议使用LocalFileMetaStore存储(特别是部署到k8s上),否则将消费者部署到其它服务器后,需要将localCheckpointStore文件也要同步过去才可以
// 不过可以选择同时使用两种方式
metaStoreCenter.registerStore(LOCAL_FILE_STORE_NAME, new LocalFileMetaStore(LOCAL_FILE_STORE_NAME));
metaStoreCenter.registerStore(KAFKA_STORE_NAME, new KafkaMetaStore(kafkaConsumerWrap));
Checkpoint checkpoint = null;
// 是否使用配置的检查点,如果是,则必须确保每次应用启动都配置正确的消费位置,否则会重复消费
// 建议只用于测试
if (useCheckpointConfig.compareAndSet(true, false)) {
log.info("RecordGenerator: force use initial checkpoint [{}] to start", checkpoint);
checkpoint = initialCheckpoint;
} else {
// 从检查点存储器获取检查点(由于是每5秒提交一次,所以每次重起都会有小部分记录被重新消费,请自行确保幂等性)
// 优先使用本地检查点
checkpoint = metaStoreCenter.seek(LOCAL_FILE_STORE_NAME, topicPartition, groupID);
if (null == checkpoint) {
// 使用kafka检查点
checkpoint = metaStoreCenter.seek(KAFKA_STORE_NAME, topicPartition, groupID);
}
// 没有找到检查点,则使用配置的初始化检查点
if (null == checkpoint || Checkpoint.INVALID_STREAM_CHECKPOINT == checkpoint) {
checkpoint = initialCheckpoint;
log.info("RecordGenerator: use initial checkpoint [{}] to start", checkpoint);
} else {
log.info("RecordGenerator: load checkpoint from checkpoint store success, current checkpoint [{}]", checkpoint);
}
}
return checkpoint;
}
}
局部异步消费
生产-消费模型中的消费者并不负责真正的消费消息,而是将消息交给多个监听器去消费。
针对不同场景,可能同一个表有多个监听器监听,针对这种情况,可以让多个监听器并行消费,但需要阻塞等待所有监听器都消费完后再提交offset给offset提交者。
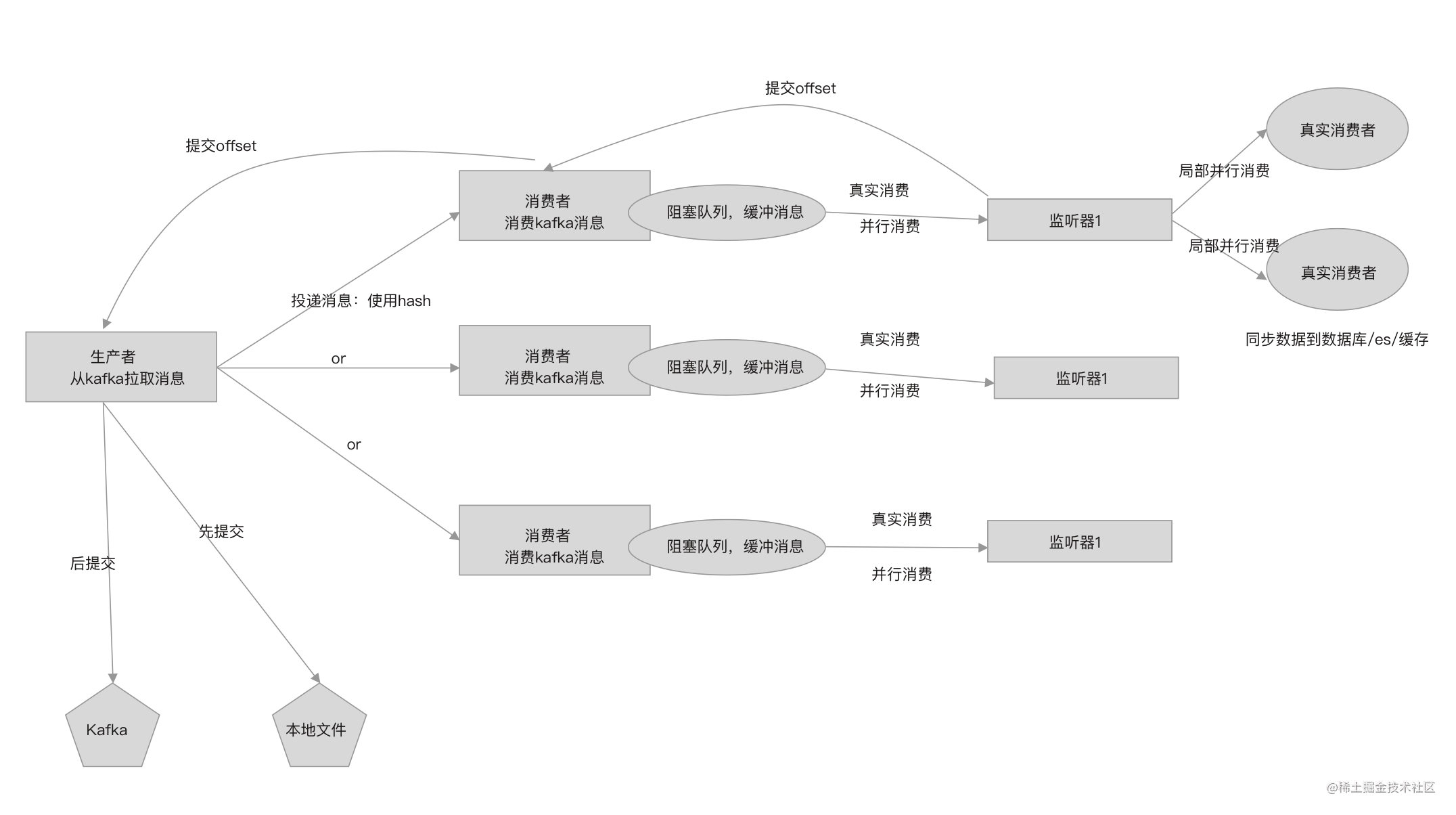
局部多线程消费实现如下:
private List<Future<Void>> submitConsume(String table, BiglogOperation operation, FieldHolderMap<MysqlFieldHolder> fields) {
List<TableOperationHandler> matchHandlers = handlerMap.get(table);
if (CollectionUtils.isEmpty(matchHandlers)) {
return Collections.emptyList();
}
if (matchHandlers.size() == 1) {
// 只有一个监听器则同步消费
matchHandlers.get(0).handle(operation, fields);
return Collections.emptyList();
}
List<Future<Void>> futures = new ArrayList<>();
for (TableOperationHandler handler : matchHandlers) {
// 多个监听器提交到线程池消费
futures.add(executorService.submit(() -> handler.handle(operation, fields), null));
}
return futures;
}
实现支持有序插入的LinkSort
这是一个单向链表,first永远指向表头,tail永远指向表尾,mide随着每次插入元素而变化。mide用于局部优化插入效率,相当于实现一维的二分查找。
/**
* 有序插入队列
* 并发安全
*
* @author wujiuye 2020/11/27
*/
public class LinkSortSupporAsync<T extends Comparable<T>> {
private class Node implements Comparable<Node> {
private T obj;
private Node next;
public Node(T obj) {
this.obj = obj;
}
// ...get set
}
private Node first;
private Node tail;
private Node mide;
private int cap;
private int size = 0;
private Condition notFullCondition;
private ReadWriteLock readWriteLock;
public LinkSortSupporAsync() {
this(Integer.MAX_VALUE);
}
public LinkSortSupporAsync(int cap) {
this.cap = cap;
this.readWriteLock = new ReentrantReadWriteLock();
this.notFullCondition = this.readWriteLock.writeLock().newCondition();
}
public void put(T obj) {
readWriteLock.writeLock().lock();
try {
while (cap <= size) {
try {
notFullCondition.await();
} catch (InterruptedException ignored) {
}
}
size++;
Node node = new Node(obj);
if (first == null) {
first = node;
tail = first;
return;
}
if (node.compareTo(tail) > 0) {
tail.next = node;
tail = node;
return;
}
Node ptr = first;
Node pre = null;
if (mide != null && node.compareTo(mide) >= 0) {
ptr = mide;
}
for (; ptr != null && node.compareTo(ptr) >= 0; pre = ptr, ptr = ptr.next) {
}
if (pre == null) {
node.next = first;
first = node;
} else if (pre == tail) {
pre.next = node;
tail = node;
} else {
mide = node;
pre.next = node;
node.next = ptr;
}
} finally {
readWriteLock.writeLock().unlock();
}
}
/**
* 弹出队列中比较值连续的最大的节点,并且移除节点,包括之前的节点
*
* @param maxNode 最大遍历的节点数,避免遍历完整个队列,导致队列一直阻塞
* @return
*/
public T popSuccessiveMax(int maxNode) {
readWriteLock.writeLock().lock();
try {
if (first == null) {
return null;
}
Node ptr = first;
Node pre = null;
int popCnt = 1;
boolean isNumber = first.obj instanceof Number;
for (int i = 0; ptr != null && i < maxNode; pre = ptr, ptr = ptr.next, i++) {
if (pre == null) {
continue;
}
int cz;
if (isNumber) {
cz = (int) (((Number) ptr.obj).longValue() - ((Number) pre.obj).longValue());
} else {
cz = ptr.compareTo(pre);
}
// 确保T 实现的compareTo方法返回值为两个数值的差
if (cz != 1) {
break;
}
popCnt++;
if (mide == pre) {
mide = ptr;
}
}
if (pre == null) {
first = ptr.next;
size--;
if (mide == ptr) {
mide = null;
}
notFullCondition.signal();
return ptr.obj;
}
if (pre == tail) {
first = tail = null;
size = 0;
mide = null;
notFullCondition.signal();
return pre.obj;
}
if (mide == ptr) {
mide = null;
}
first = ptr;
size -= popCnt;
notFullCondition.signal();
return pre.obj;
} finally {
readWriteLock.writeLock().unlock();
}
}
}
使用Kafka订阅Binlog之字段值获取防坑指南(阿里云DTS)
在某些场景下,这种并行消费方式还是出现了问题,出现在关联表更新数据同步的先后顺序上。
在此分享下我们的解决方案:新增分组概念,将关联表放到同一分组,将同一分组的Binlog分配到同一线程消费。限制一个表只能分配到一个分组下,如果没有为表配置分组,则该表就是一个独立的分组,分组名称就是表名称。
在一次调试过程中笔者发现,日记打印的Binlog显示某些字段更新之前和更新之后都有值,可是到消费的时候获取字段的值却是null,如下图所示。

在此之前消费都是正常的,突然获取不到Binlog修改的字段值,而此次代码只是加了一条日记打印。添加打印消费到的每条Binlog记录的详细信息之后,消费就不正常了,并且现象很奇怪,数值类型与日期类型的字段依然能正常获取到值,只是字符串类型的字段获取不到值了。
排查此问题的思路:从Kafka拉取到消息到实际消费,这期间都做了什么,导致获取字段值为null?
使用kafka拉取Binlog需要使用Avro反序列化消息,消息反序列化后生成com.alibaba.dts.formats.avro.Record对象,该对象记录了Binlog的操作类型、操作的库和表、字段、字段修改之前的镜像值与修改之后的镜像值。
从Record对象获取字段的镜像值类型为"com.alibaba.dts.formats.avro"包下对应的类型,这些类型都提供有getValue方法获取值,但不同类型getValue方法返回值类型不同。
com.alibaba.dts.formats.avro.Integer的getValue方法返回值类型为java.lang.String;com.alibaba.dts.formats.avro.Float的getValue方法返回值类型为java.lang.Double;- …
为便于使用,我们封装了获取镜像值的步骤,不管数据库字段是什么类型,统一将镜像值解析为字符串,并提供getAsString、getAsInteger、getAsFloat之类的API,不必再关心数据库该字段的值是什么类型,只需要关心我想要获取的值应该是什么类型。
例如,将字段的镜像值都解析为FieldValue实例,FieldValue类定义如下:
public class FieldValue {
private String encoding;
private byte[] bytes;
public String getAsString() {
return new String(bytes, encoding);
}
public Integer getAsInteger() {
return Integer.parseInt(getAsString());
}
public Long getAsLong() {
return Long.parseLong(getAsString());
}
public BigDecimal getAsBigDecimal() {
return new BigDecimal(getAsString());
}
// ......
}
以将com.alibaba.dts.formats.avro.Integer类型的字段值解析为FieldValue对象为例,实现解析代码如下。
static class NumberStringAdapter implements DataAdapter {
@Override
public FieldValue getFieldValue(Object data) {
FieldValue fieldValue = new FieldValue();
if (null != data) {
com.alibaba.dts.formats.avro.Integer integer = (com.alibaba.dts.formats.avro.Integer) data;
// 调用getValue获取字符串数值,并将字符串转为字节数组
fieldValue.setValue(integer.getValue().getBytes(US_ASCII));
}
fieldValue.setEncoding("ASCII");
return fieldValue;
}
}
为便于使用,我们还可以将字段、字段修改之前的镜像值、字段修改之后的镜像值解析为一个个FieldHolder实例,FieldHolder的定义如下。
public abstract class FieldHolder {
protected Field field;
// 当操作为插入时,此字段没有值
protected FieldValue beforeImage;
// 当操作为删除时,此操作没有值
protected FieldValue afterImage;
// 省略get方法
public FieldHolder(Field field, Object beforeImage, Object afterImage) {
//....
}
// 比较该字段的值是否修改了
public boolean isModify() {
if (beforeImage == null && afterImage == null) {
return false;
}
if (beforeImage == null) {
return true;
}
if (afterImage == null) {
return true;
}
return !getBeforeFieldValue().equals(getAfterFieldValue());
}
}
以Integer、Float(com.alibaba.dts.formats.avro包下的类)不同的是,Character、BinaryObject的getValue方法返回值类型为java.nio.ByteBuffer。将Character类型的字段值解析为FieldValue对象的实现代码如下。
static class CharacterAdapter implements DataAdapter {
@Override
public FieldValue getFieldValue(Object data) {
FieldValue fieldValue = new FieldValue();
if (null != data) {
com.alibaba.dts.formats.avro.Character character = (com.alibaba.dts.formats.avro.Character) data;
ByteBuffer buffer = character.getValue();
byte[] ret = new byte[buffer.remaining()];
buffer.get(ret);
fieldValue.setValue(ret);
fieldValue.setEncoding(character.getCharset());
} else {
fieldValue.setEncoding("ASCII");
}
return fieldValue;
}
}
可以看出,产生此次bug的原因在于,调用ByteBuffer的get方法读取数据后,ByteBuffer的读偏移量(position)等于limit,由于没有调用flip重置读指针为0,导致后续再调用getFieldValue解析同一个镜像值时,解析后的FieldValue对象的bytes字段值是空的。
应将代码改为如下:
static class CharacterAdapter implements DataAdapter {
@Override
public FieldValue getFieldValue(Object data) {
FieldValue fieldValue = new FieldValue();
if (null != data) {
com.alibaba.dts.formats.avro.Character character = (com.alibaba.dts.formats.avro.Character) data;
ByteBuffer buffer = character.getValue();
byte[] ret = new byte[buffer.remaining()];
buffer.get(ret);
fieldValue.setValue(ret);
fieldValue.setEncoding(character.getCharset());
character.getValue().flip();
} else {
fieldValue.setEncoding("ASCII");
}
return fieldValue;
}
}
当然,我们可以让整个Record记录只解析一次,后续就不会出现反复读取字段值的情况。
定义Record解析器接口:
public interface RecordResolver<T extends FieldHolder> {
String getDdl();
String getDatabase();
String getTable();
Operation getOperation();
FieldHolderMap<T> getFields();
}
根据Record对象创建Record解析器,在解析器构造方法中立即解析Record,外部每次调用Record解析器获取字段信息都是获取到已经解析好的。代码如下。
public abstract class BaseRecordResolver<T extends FieldHolder> implements RecordResolver<T> {
private String db;
private String table;
private String ddl;
private Operation operation;
private FieldHolderMap<T> fieldHolderMap;
public BaseRecordResolver(Record record) {
this.operation = record.getOperation();
String[] dbPair = uncompressionObjectName(record.getObjectName());
if (null != dbPair) {
this.db = dbPair[0];
if (dbPair.length == 2) {
table = dbPair[1];
} else if (dbPair.length == 3) {
table = dbPair[2];
} else if (dbPair.length == 1) {
table = "";
}
}
if (record.getOperation() == Operation.DDL) {
ddl = (String) record.getAfterImages();
} else if (record.getFields() != null) {
this.fieldHolderMap = readFieldInfo(record);
}
}
private FieldHolderMap<T> readFieldInfo(Record record) {
Iterator<Field> fields = ((List<Field>) record.getFields()).iterator();
Iterator<Object> beforeImages = null;
Iterator<Object> afterImages = null;
// update操作没有BeforeImages
if (record.getOperation() == Operation.UPDATE || record.getOperation() == Operation.DELETE) {
beforeImages = ((List<Object>) record.getBeforeImages()).iterator();
}
// delete操作没有AfterImages
if (record.getOperation() == Operation.INSERT || record.getOperation() == Operation.UPDATE) {
afterImages = ((List<Object>) record.getAfterImages()).iterator();
}
List<T> fieldHolders = new ArrayList<>(((List<Field>) record.getFields()).size());
while (fields.hasNext()
&& (beforeImages == null || beforeImages.hasNext())
&& (afterImages == null || afterImages.hasNext())) {
Field field = fields.next();
Object before = beforeImages == null ? null : beforeImages.next();
Object after = afterImages == null ? null : afterImages.next();
fieldHolders.add(resolverField(field, before, after));
}
return new FieldHolderMap<>(fieldHolders);
}
@Override
public String getDdl() {
if (operation == Operation.DDL) {
return this.ddl;
}
throw new IllegalArgumentException("not found ddl error");
}
@Override
public String getDatabase() {
return this.db;
}
@Override
public String getTable() {
return this.table;
}
@Override
public Operation getOperation() {
return this.operation;
}
@Override
public FieldHolderMap<T> getFields() {
if (getOperation() == Operation.DDL) {
throw new IllegalArgumentException("ddl not fields");
}
return this.fieldHolderMap;
}
//
protected abstract T resolverField(Field field, Object before, Object after);
}