![]()
 故障排查与性能优化 专栏收录该内容,点击查看专栏更多内容
故障排查与性能优化 专栏收录该内容,点击查看专栏更多内容原创 吴就业 573 0 2024-02-06
本文为博主原创文章,未经博主允许不得转载。
本文链接:https://wujiuye.com/article/039d7513c37847bfbd1bf30d64567ae5
作者:吴就业
链接:https://wujiuye.com/article/039d7513c37847bfbd1bf30d64567ae5
来源:吴就业的网络日记
本文为博主原创文章,未经博主允许不得转载。
频繁收到推送系统的一个Java服务的Long GC告警。
从查看告警节点的堆live对象来看,告警节点的内存消耗主要与ForwardRequest和CloseMsg两个类有关。
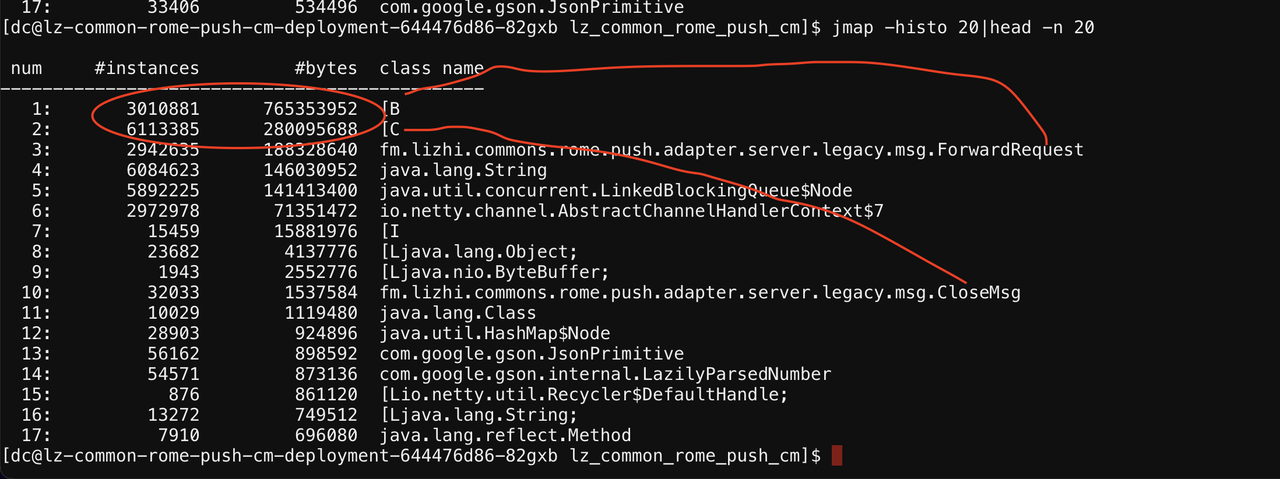
接着查看相关代码,看为什么会有这么多存活实例。
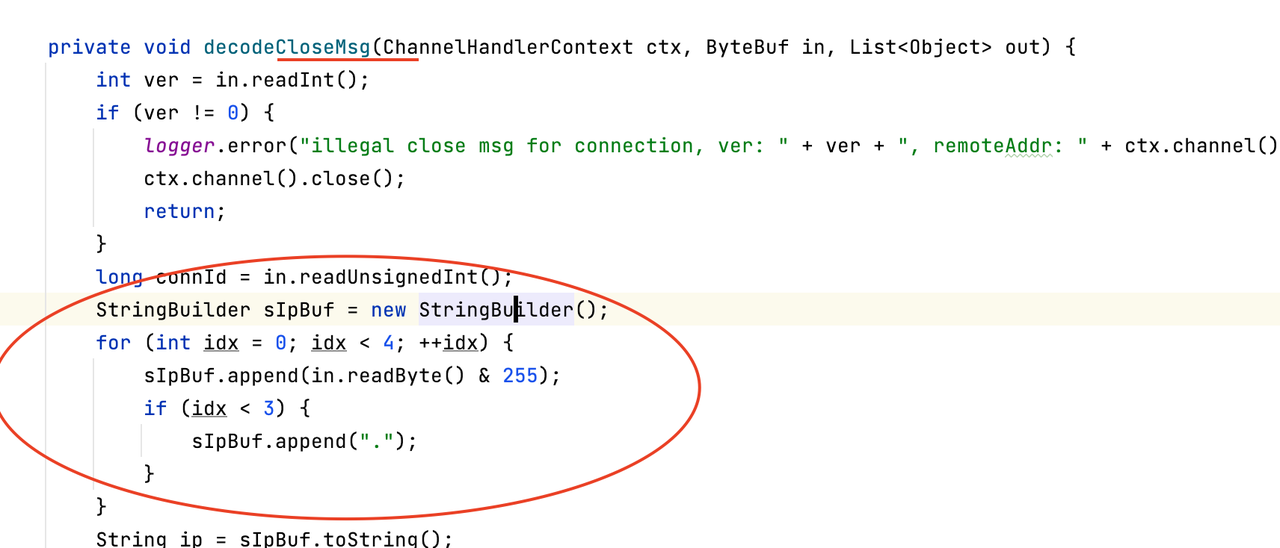
1.创建CloseMsg和ForwardRequest的方法中,都使用了StringBulder,这是导致“[C”对象多的原因。
2.ForwardRequest创建byte数组接收body,这是导致“[B”对象多的原因。
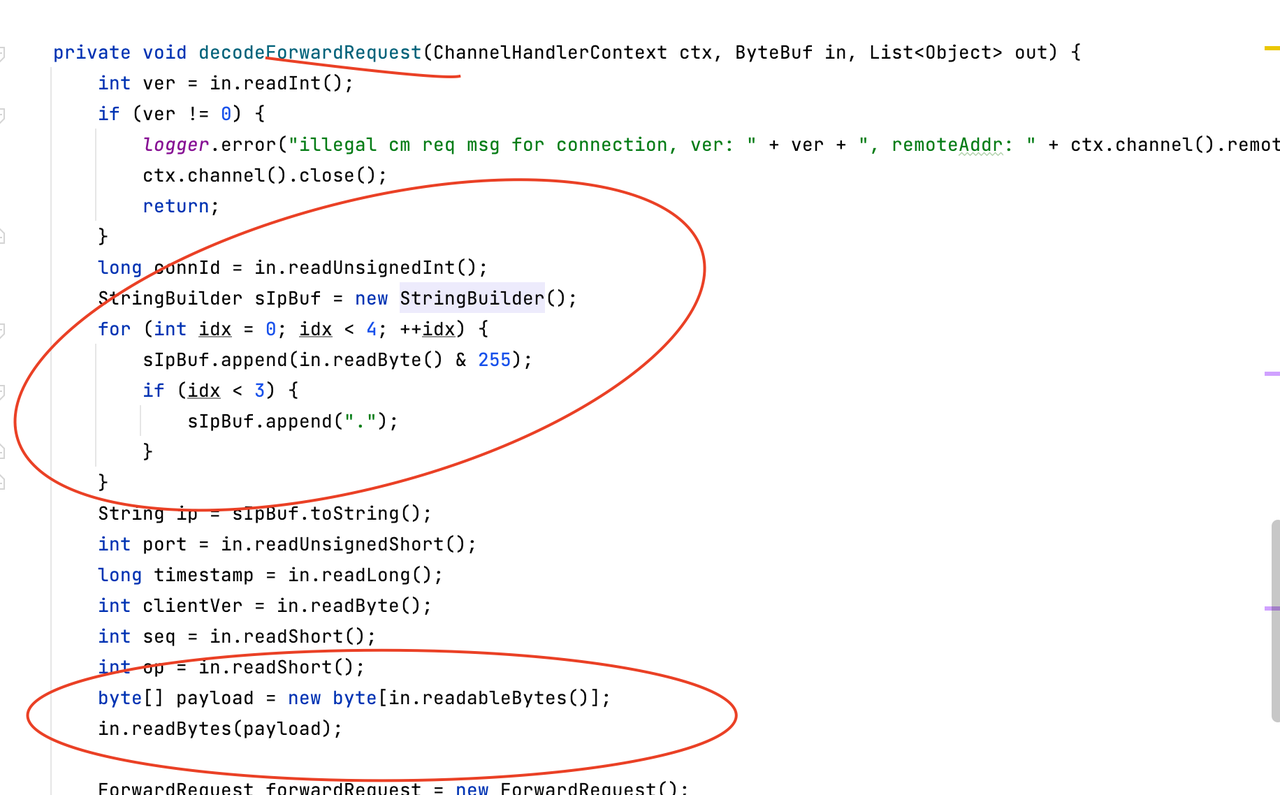
这看起来很正常,不会导致full gc。
所以跟另外一个没有触发告警的节点对比看。
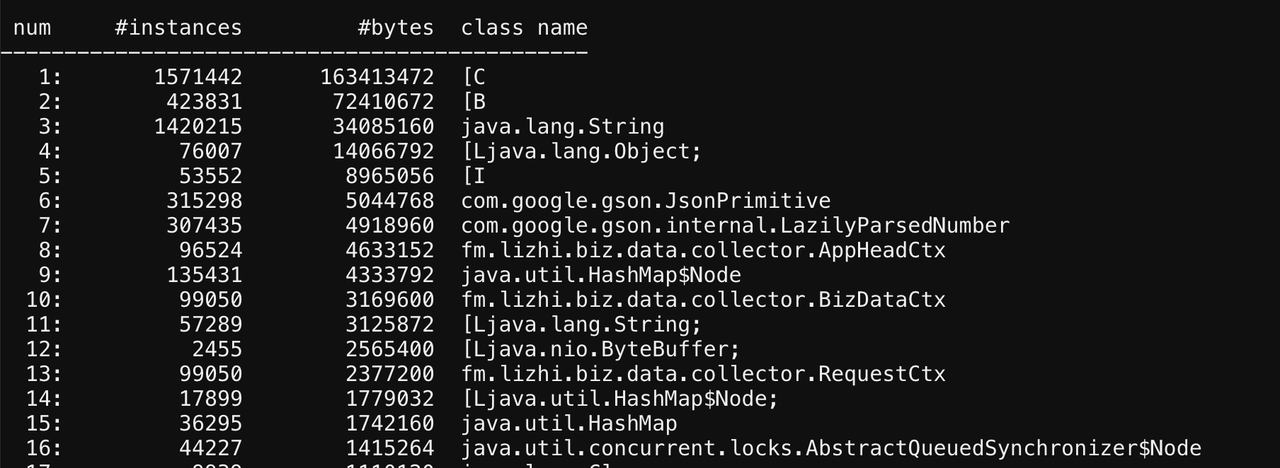
这是没有告警的节点的堆live排行前20的对象截图,从这可以看出,这个节点没有ForwardRequest和CloseMsg对象。
怀疑是否是请求倾斜导致的,所以看了下cat。


可以看到,两个节点的rpc请求分布平均,不存在倾斜情况。
接着对比了下两个节点的gc日记。
另外一个节点内存使用正常,从gc日记看并没有发生full gc,老年代只有6%左右的使用率,gc大约是每分钟一次Minor GC。
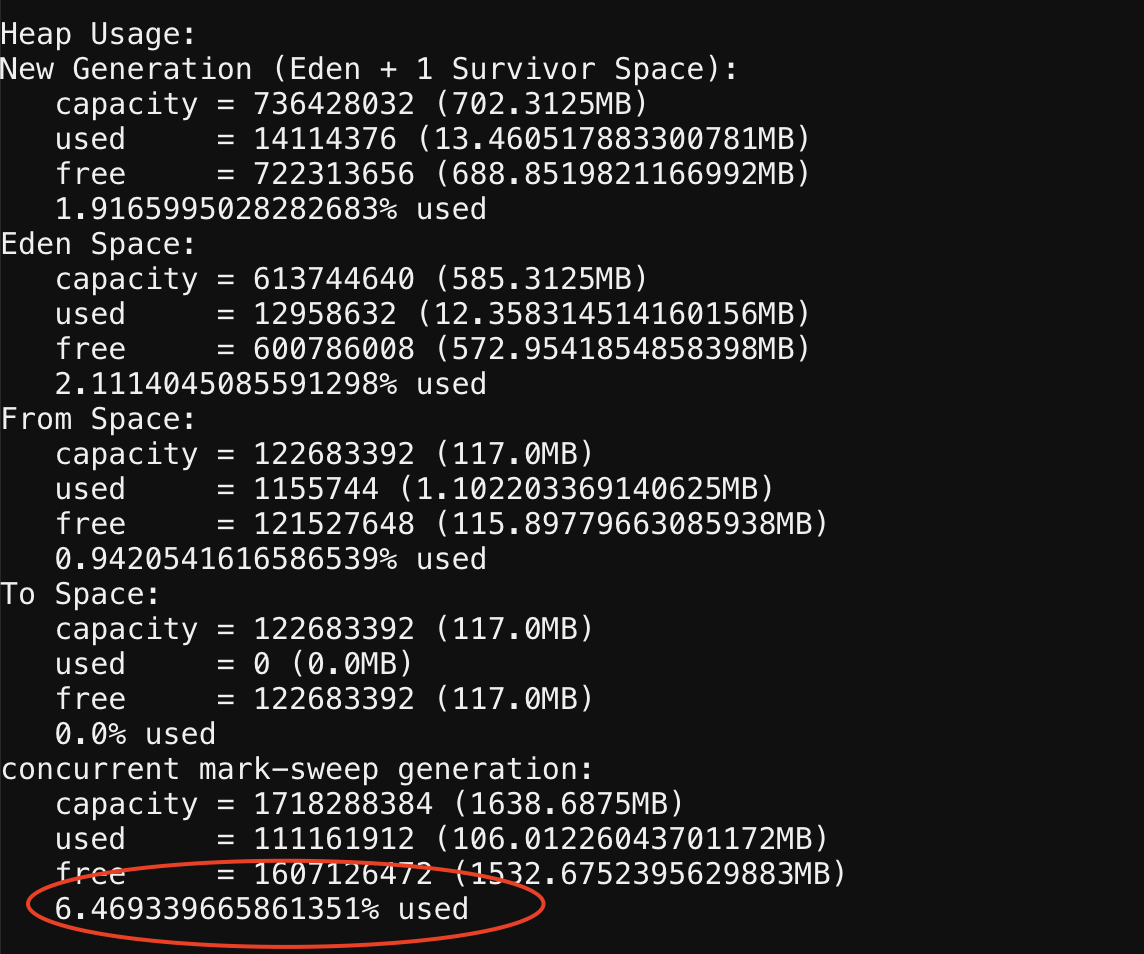
gc日记:
2023-03-05T22:36:26.130+0800: 456600.524: [GC (Allocation Failure) 2023-03-05T22:36:26.131+0800: 456600.524: [ParNew2023-03-05T22:36:26.138+0800: 456600.531: [SoftReference, 1 refs, 0.0006218 secs]2023-03-05T22:36:26.139+0800: 456600.532: [WeakReference, 10 refs, 0.0003294 secs]2023-03-05T22:36:26.139+0800: 456600.532: [FinalReference, 5 refs, 0.0002867 secs]2023-03-05T22:36:26.140+0800: 456600.533: [PhantomReference, 0 refs, 0 refs, 0.0006207 secs]2023-03-05T22:36:26.140+0800: 456600.533: [JNI Weak Reference, 0.0000373 secs]: 600002K->572K(719168K), 0.0097842 secs] 708862K->109438K(2397184K), 0.0100859 secs] [Times: user=0.08 sys=0.01, real=0.01 secs]
而告警的节点很频繁的full gc,老年代使用率达到了92%,从gc日记看,基本10秒左右一次full gc(当时jstat执行不了,只能从gc日记猜测),每次full gc后老年代大小基本只释放了几十M。
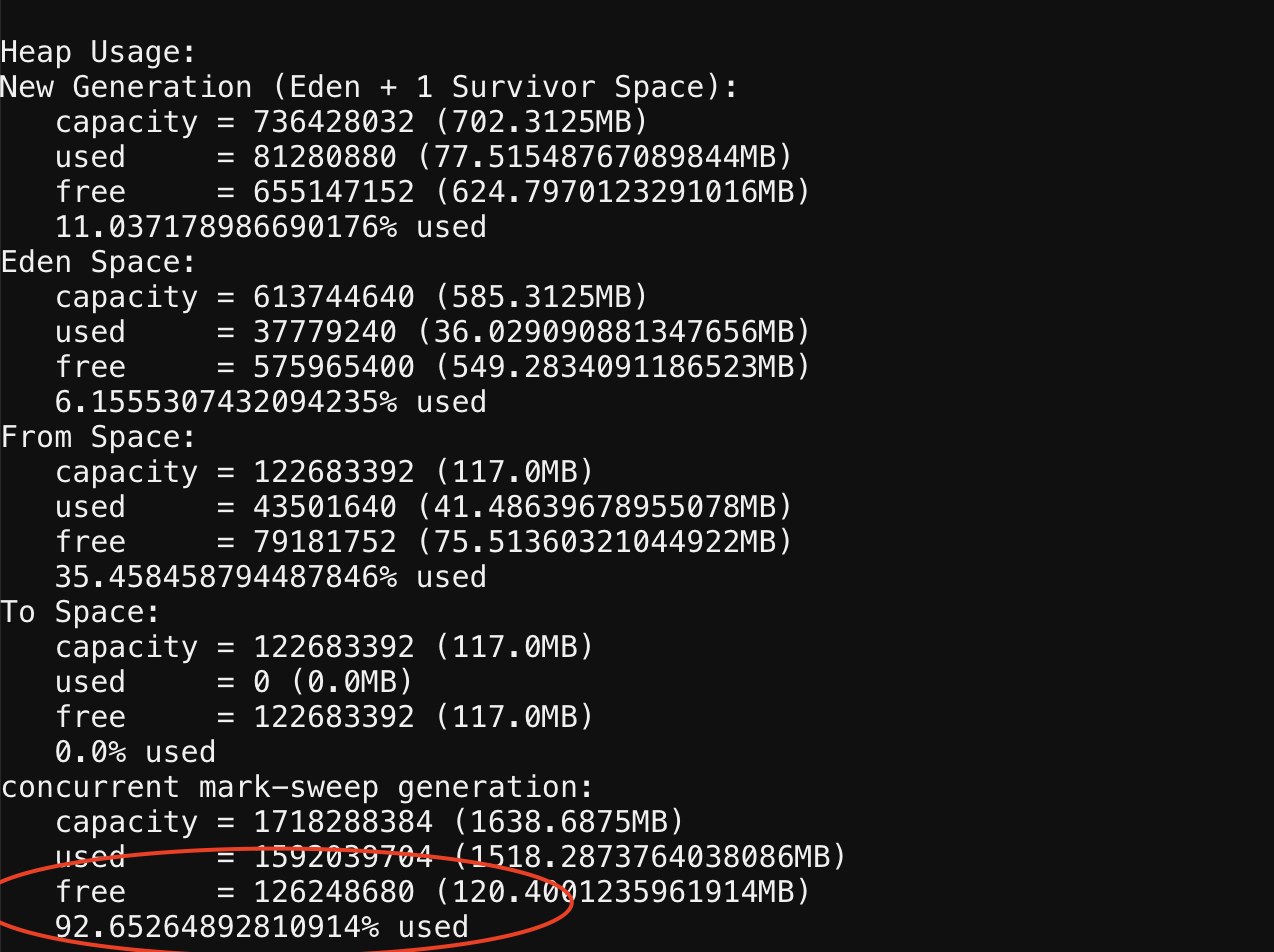
gc日记:
2023-03-05T22:21:04.652+0800: 228099.479: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1555247K(1678016K)] 1704159K(2397184K), 0.0068179 secs] [Times: user=0.07 sys=0.00, real=0.01 secs]
2023-03-05T22:21:04.659+0800: 228099.486: Total time for which application threads were stopped: 0.0088990 seconds, Stopping threads took: 0.0001878 seconds
2023-03-05T22:21:04.659+0800: 228099.486: [CMS-concurrent-mark-start]
2023-03-05T22:21:05.771+0800: 228100.597: [CMS-concurrent-mark: 1.112/1.112 secs] [Times: user=2.19 sys=0.04, real=1.11 secs]
2023-03-05T22:21:05.771+0800: 228100.598: [CMS-concurrent-preclean-start]
2023-03-05T22:21:05.771+0800: 228100.598: [Preclean SoftReferences, 0.0000179 secs]2023-03-05T22:21:05.771+0800: 228100.598: [Preclean WeakReferences, 0.0001326 secs]2023-03-05T22:21:05.771+0800: 228100.598: [Preclean FinalReferences, 0.0000042 secs]2023-03-05T22:21:05.771+0800: 228100.598: [Preclean PhantomReferences, 0.0000417 secs]2023-03-05T22:21:05.775+0800: 228100.601: [CMS-concurrent-preclean: 0.003/0.003 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
2023-03-05T22:21:05.775+0800: 228100.601: [CMS-concurrent-abortable-preclean-start]
2023-03-05T22:21:08.659+0800: 228103.486: Application time: 4.0002883 seconds
2023-03-05T22:21:08.661+0800: 228103.488: Total time for which application threads were stopped: 0.0017681 seconds, Stopping threads took: 0.0002360 seconds
CMS: abort preclean due to time 2023-03-05T22:21:10.842+0800: 228105.669: [CMS-concurrent-abortable-preclean: 4.564/5.067 secs] [Times: user=4.62 sys=0.24, real=5.07 secs]
2023-03-05T22:21:10.842+0800: 228105.669: Application time: 2.1812539 seconds
2023-03-05T22:21:10.844+0800: 228105.671: [GC (CMS Final Remark) [YG occupancy: 209011 K (719168 K)]2023-03-05T22:21:10.844+0800: 228105.671: [Rescan (parallel) , 0.0098310 secs]2023-03-05T22:21:10.854+0800: 228105.681: [weak refs processing2023-03-05T22:21:10.854+0800: 228105.681: [SoftReference, 0 refs, 0.0006263 secs]2023-03-05T22:21:10.855+0800: 228105.681: [WeakReference, 0 refs, 0.0003887 secs]2023-03-05T22:21:10.855+0800: 228105.682: [FinalReference, 0 refs, 0.0004183 secs]2023-03-05T22:21:10.856+0800: 228105.682: [PhantomReference, 0 refs, 0 refs, 0.0006828 secs]2023-03-05T22:21:10.856+0800: 228105.683: [JNI Weak Reference, 0.0000408 secs], 0.0022203 secs]2023-03-05T22:21:10.856+0800: 228105.683: [class unloading, 0.0118796 secs]2023-03-05T22:21:10.868+0800: 228105.695: [scrub symbol table, 0.0042571 secs]2023-03-05T22:21:10.873+0800: 228105.699: [scrub string table, 0.0007146 secs][1 CMS-remark: 1555247K(1678016K)] 1764259K(2397184K), 0.0292921 secs] [Times: user=0.15 sys=0.00, real=0.03 secs]
2023-03-05T22:21:10.874+0800: 228105.700: Total time for which application threads were stopped: 0.0313728 seconds, Stopping threads took: 0.0001977 seconds
2023-03-05T22:21:10.874+0800: 228105.701: [CMS-concurrent-sweep-start]
2023-03-05T22:21:11.331+0800: 228106.157: [CMS-concurrent-sweep: 0.457/0.457 secs] [Times: user=0.44 sys=0.02, real=0.46 secs]
2023-03-05T22:21:11.331+0800: 228106.158: [CMS-concurrent-reset-start]
2023-03-05T22:21:11.333+0800: 228106.160: [CMS-concurrent-reset: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2023-03-05T22:21:13.333+0800: 228108.159: Application time: 2.4588597 seconds
其中:
[1 CMS-remark: 1555247K(1678016K)] 1764259K(2397184K), 0.0292921 secs]
老年代gc前1638m,gc 后1518m,仅释放了100m左右的内存。
隔了一段时间之后,再看full gc日记:
[1 CMS-remark: 1570195K(1678016K)] 1693221K(2397184K), 0.0354122 secs] [Times: user=0.10 sys=0.01, real=0.04 secs]
gc后老年代还使用了1533m,比之前多了十几m。
结合容器是重启一天后才会出现告警,因此怀疑存在内存泄露(被强引用,无法被gc回收),而且这个泄漏是一点一点慢慢增加的,当增加内存使用占用总内存的80%以上,就会触发full gc。
所以隔个十分钟后再看了一下gc日记:
[1 CMS-remark: 1579052K(1678016K)] 1754833K(2397184K), 0.0373494 secs] [Times: user=0.13 sys=0.00, real=0.03 secs]
发现确实涨上去了,变成1713m了。
那么会是哪里泄漏呢,结合前面jmap -histo 的截图,对比差异,怀疑是ForwardRequest和CloseMsg不会被释放。
前面截图,ForwardRequest的实例数是2942635,大概一个小时后的当前截图ForwardRequest实例数是3072736。

说明是ForwardRequest一直在增长,且没有被释放,导致内存泄露。
内存泄露的问题已经找出。
这里引出新的问题:
一、另一个节点为什么没有ForwardRequest请求?
二、为什么ForwardRequest会泄漏?这里还需要能够拿到dump堆内存下载下来分析对象引用。
dump的时候已经是第二天进程被手动重启之后,经过dump内存分析后,未发现存在被其它地方引入导致无法被gc的情况,而且跑了一段时间,ForwardRequest的实例数也没有异常增长。
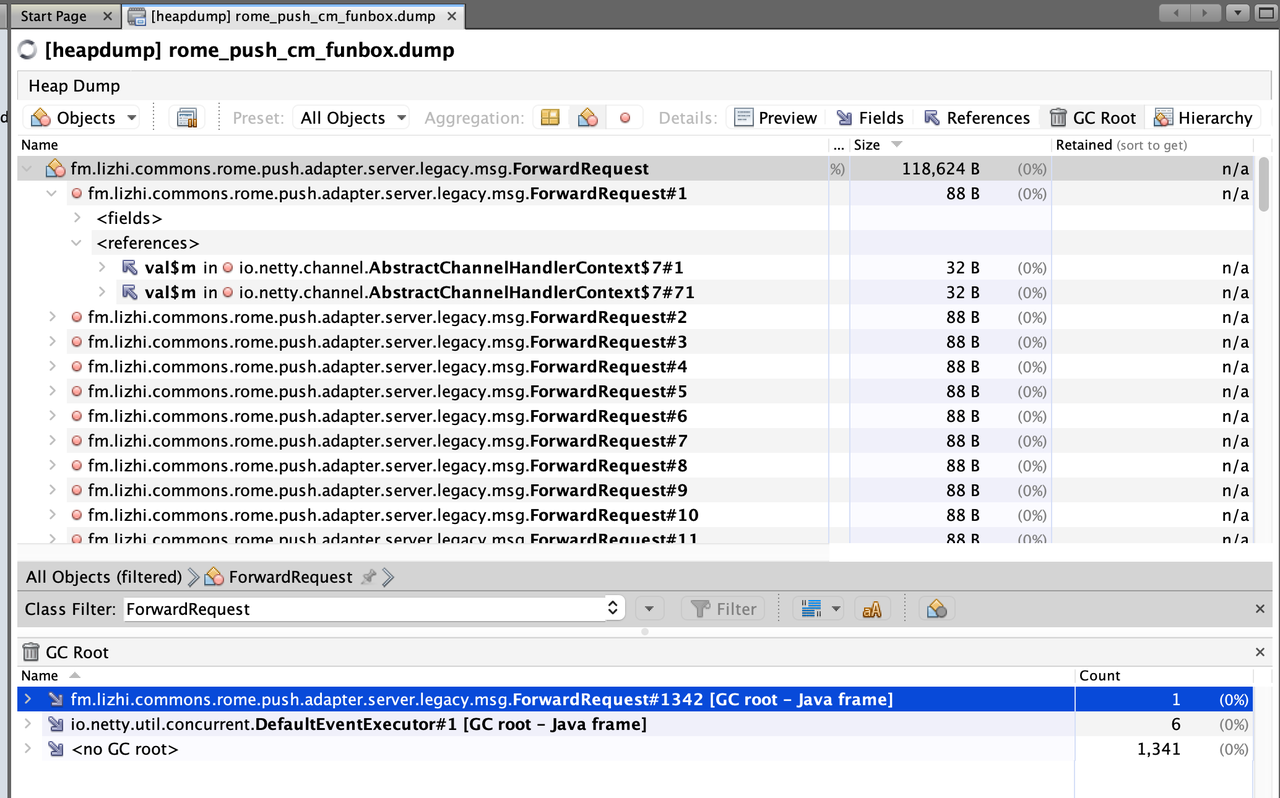
其中gc root - java frame的意思是,虚拟机执行gc时候,会把虚拟机栈里面的局部变量作为gc root,所以这里ForwardRequest作为Gc root是正常的。
那么,唯一能怀疑的是DefaultEventExecutor的队列一直引用了。
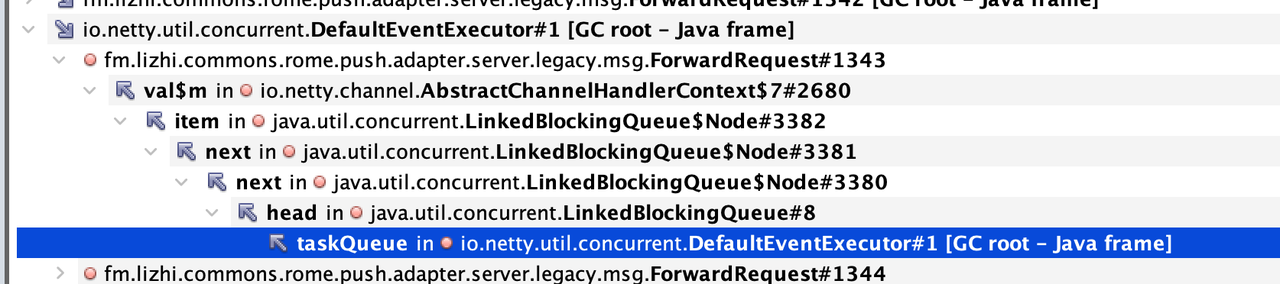
正常任务被从队列取出执行完后,内存也就被释放了。
声明:公众号、CSDN、掘金的曾用名:“Java艺术”,因此您可能看到一些早期的文章的图片有“Java艺术”的水印。
![]()
代码中,与tls有关的地方就是发送https请求从s3下载文件,所以检查下载文件调用链路上是否存在可疑的内存泄漏,发现如下疑点。统计了访问日记,发现确实经常出现响应403。所以问题就清晰了,由于403是有body的,没有close响应的body导致的内存泄漏。
因为go标准库实现tls握手性能比较差,在一台8核的机器,只能到达2000这个量级,所以当到达某个临界点的时候,握手占用CPU过高,反过头来影响正常的业务请求,导致了业务请求处理变得十分慢。
用go开发的一个文件上传中间件,由于依赖了ceph这个c库,早期通过pprof排查,怀疑内存泄露在c层,而项目依赖ceph,于是就怀疑是ceph的问题。但通过使用jemalloc排查后,并未发现ceph有什么异常。最后使用最笨的方法,定位到github.com/chai2010/webp库存在内存泄露bug。
一个微服务可能引入非常多的SDK,例如消息中间件kafka的组件、RPC框架dubbo、定时任务调度平台xxl-job的组件,以及提供web服务的jetty/tomcat等。这些组件的初始化是不确定的,那么假如启动初始化过程中,其中某个组件初始化失败了,会发生什么?
订阅
订阅新文章发布通知吧,不错过精彩内容!
输入邮箱,提交后我们会给您发送一封邮件,您需点击邮件中的链接完成订阅设置。