![]()
为什么要使用redis的多数据库,我们项目中就这么用了,这点我也想不明白。如果是要做业务隔离,那么可以给不同业务的缓存key添加一个前缀,如果因此导致key过长,可以把一个大的redis集群拆分为对应多个业务的集群。不管分多少个库,集群总的内存大小是不变的,所能存储的数据也是一样多的,为何不把一个大的集群拆分给每个业务使用呢?
既然要做业务隔离,将一个大的redis集群拆分给不同业务使用,根据不同业务对缓存大小的要求以及并发访问量拆分,这样不是能更好的做到业务上的隔离吗。用不同数据库隔离也没有多大毛病,但如果各服务不是按业务拆分的情况下,这种方式会导致项目中每操作一次redis都需要切换数据库,对服务来说,平白无辜添加了一次网络I/O,降低缓存读写的性能,并发量越大所展现出来的毛病就越多,这与高并发性能调优背道而驰。
在java项目中,除了jedis会支持动态切换数据库之外,使用其它框架要么通过动态修改连接池的配置,要么就是为每个库配置一个连接池来实现,而这些都会影响到性能,因此jedis成了最优的选择。为什么这些框架都不支持动态切换库,因为没有人会这么使用,显然动态切换库是不推荐的。
我在Google网上论坛的Redis DB论坛上看到这么一篇帖子,链接:https://groups.google.com/forum/?spm=a2c4e.11153987.0.0.1d6e4e37polahb#!forum/redis-db。
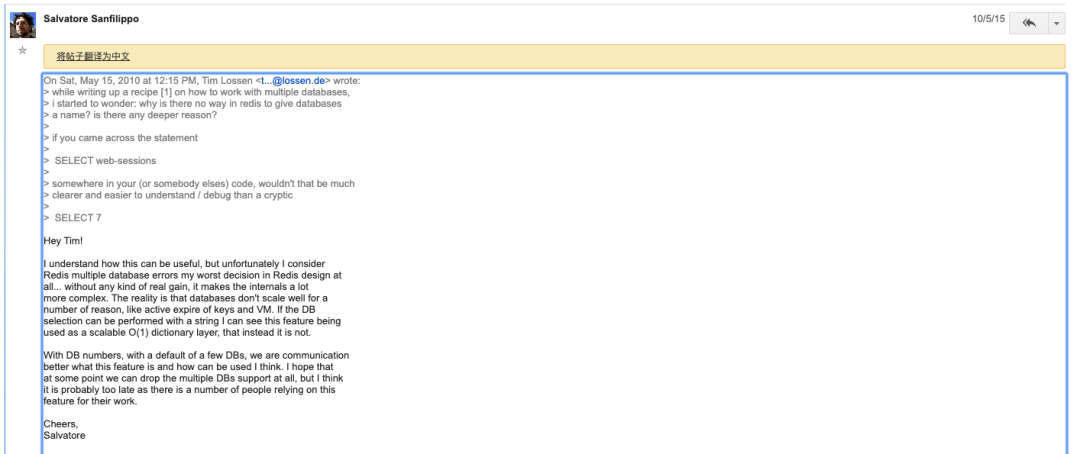
图为redis作者antirez在tim lossen发表的一个帖子database names?中的回复,tim lossen在帖子中提问,为什么redis的多数据库不支持使用名称,而只能使用数字?正如你在图中所看到的,redis作者antirez的回复大致意思是:Redis多数据库是我在Redis设计中最糟糕的决定,我希望在某种程度上,我们可以放弃多个数据库的支持,但我认为可能已经太晚了,因为有很多人在工作中使用这个特性。
在以往的redis文章中,我也提到过,使用jedis配置连接池时,建议把每次从连接池中获取一个连接时都向服务端发送一个ping命令检测连接是否可用的配置关掉,因为高并发场景下,该操作会导致服务频繁的向redis服务端发送ping命令,也会导致服务自身相当于多了一次get请求的耗时,因为网络I/O。
项目不是按业务拆分导致各项目之间耦合严重,多个数据库的使用更是增加了项目的维护难度,增加了各小组之间的沟通成本,而“key是什么,在哪个库?”也成了我们沟通的常用语。当你想修改某个key时,你需要询问各小组的意见,各个项目都得修改,而当你想添加一个key时,你需要询问各个小组,这个key有没有使用,避免覆盖别人的key,当然,这也是系统架构层面最大的错误。而抛开系统架构问题,显然无论通过加key前缀,还是使用多个集群,都比使用不同库隔离业务的方案更合适。